 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraph2Eval: Automatic Multimodal Task Generation for Agents via Knowledge Graphs
Oct 01, 2025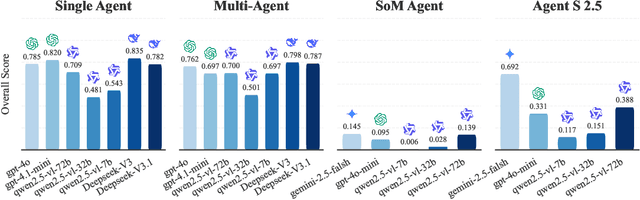
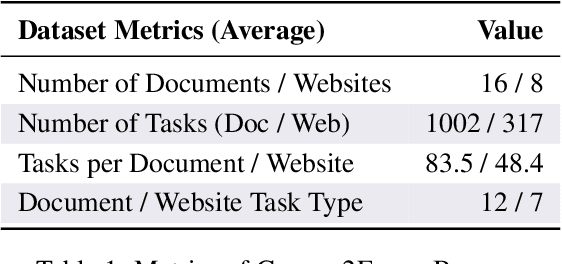
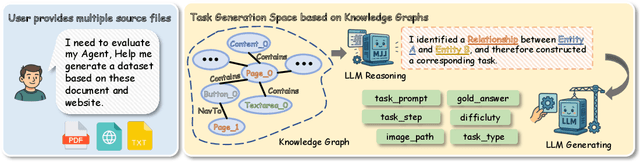
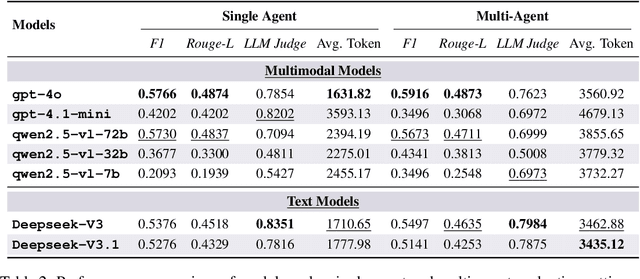
As multimodal LLM-driven agents continue to advance in autonomy and generalization, evaluation based on static datasets can no longer adequately assess their true capabilities in dynamic environments and diverse tasks. Existing LLM-based synthetic data methods are largely designed for LLM training and evaluation, and thus cannot be directly applied to agent tasks that require tool use and interactive capabilities. While recent studies have explored automatic agent task generation with LLMs, most efforts remain limited to text or image analysis, without systematically modeling multi-step interactions in web environments. To address these challenges, we propose Graph2Eval, a knowledge graph-based framework that automatically generates both multimodal document comprehension tasks and web interaction tasks, enabling comprehensive evaluation of agents' reasoning, collaboration, and interactive capabilities. In our approach, knowledge graphs constructed from multi-source external data serve as the task space, where we translate semantic relations into structured multimodal tasks using subgraph sampling, task templates, and meta-paths. A multi-stage filtering pipeline based on node reachability, LLM scoring, and similarity analysis is applied to guarantee the quality and executability of the generated tasks. Furthermore, Graph2Eval supports end-to-end evaluation of multiple agent types (Single-Agent, Multi-Agent, Web Agent) and measures reasoning, collaboration, and interaction capabilities. We instantiate the framework with Graph2Eval-Bench, a curated dataset of 1,319 tasks spanning document comprehension and web interaction scenarios. Experiments show that Graph2Eval efficiently generates tasks that differentiate agent and model performance, revealing gaps in reasoning, collaboration, and web interaction across different settings and offering a new perspective for agent evaluation.
Towards Adaptive ML Benchmarks: Web-Agent-Driven Construction, Domain Expansion, and Metric Optimization
Sep 11, 2025Recent advances in large language models (LLMs) have enabled the emergence of general-purpose agents for automating end-to-end machine learning (ML) workflows, including data analysis, feature engineering, model training, and competition solving. However, existing benchmarks remain limited in task coverage, domain diversity, difficulty modeling, and evaluation rigor, failing to capture the full capabilities of such agents in realistic settings. We present TAM Bench, a diverse, realistic, and structured benchmark for evaluating LLM-based agents on end-to-end ML tasks. TAM Bench features three key innovations: (1) A browser automation and LLM-based task acquisition system that automatically collects and structures ML challenges from platforms such as Kaggle, AIcrowd, and Biendata, spanning multiple task types and data modalities (e.g., tabular, text, image, graph, audio); (2) A leaderboard-driven difficulty modeling mechanism that estimates task complexity using participant counts and score dispersion, enabling scalable and objective task calibration; (3) A multi-dimensional evaluation framework incorporating performance, format compliance, constraint adherence, and task generalization. Based on 150 curated AutoML tasks, we construct three benchmark subsets of different sizes -- Lite, Medium, and Full -- designed for varying evaluation scenarios. The Lite version, with 18 tasks and balanced coverage across modalities and difficulty levels, serves as a practical testbed for daily benchmarking and comparative studies.
RoboVerse: Towards a Unified Platform, Dataset and Benchmark for Scalable and Generalizable Robot Learning
Apr 26, 2025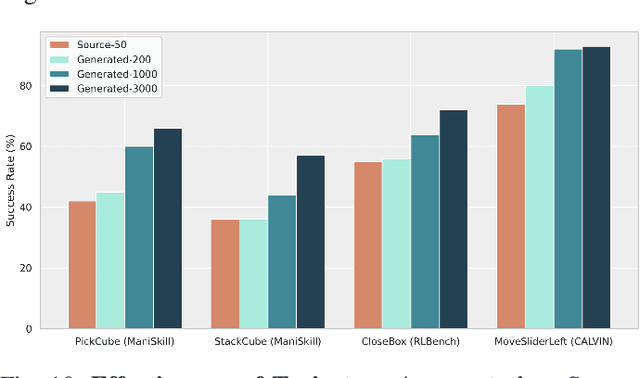



Data scaling and standardized evaluation benchmarks have driven significant advances in natural language processing and computer vision. However, robotics faces unique challenges in scaling data and establishing evaluation protocols. Collecting real-world data is resource-intensive and inefficient, while benchmarking in real-world scenarios remains highly complex. Synthetic data and simulation offer promising alternatives, yet existing efforts often fall short in data quality, diversity, and benchmark standardization. To address these challenges, we introduce RoboVerse, a comprehensive framework comprising a simulation platform, a synthetic dataset, and unified benchmarks. Our simulation platform supports multiple simulators and robotic embodiments, enabling seamless transitions between different environments. The synthetic dataset, featuring high-fidelity physics and photorealistic rendering, is constructed through multiple approaches. Additionally, we propose unified benchmarks for imitation learning and reinforcement learning, enabling evaluation across different levels of generalization. At the core of the simulation platform is MetaSim, an infrastructure that abstracts diverse simulation environments into a universal interface. It restructures existing simulation environments into a simulator-agnostic configuration system, as well as an API aligning different simulator functionalities, such as launching simulation environments, loading assets with initial states, stepping the physics engine, etc. This abstraction ensures interoperability and extensibility. Comprehensive experiments demonstrate that RoboVerse enhances the performance of imitation learning, reinforcement learning, world model learning, and sim-to-real transfer. These results validate the reliability of our dataset and benchmarks, establishing RoboVerse as a robust solution for advancing robot learning.
I-MCTS: Enhancing Agentic AutoML via Introspective Monte Carlo Tree Search
Feb 21, 2025



Recent advancements in large language models (LLMs) have shown remarkable potential in automating machine learning tasks. However, existing LLM-based agents often struggle with low-diversity and suboptimal code generation. While recent work has introduced Monte Carlo Tree Search (MCTS) to address these issues, limitations persist in the quality and diversity of thoughts generated, as well as in the scalar value feedback mechanisms used for node selection. In this study, we introduce Introspective Monte Carlo Tree Search (I-MCTS), a novel approach that iteratively expands tree nodes through an introspective process that meticulously analyzes solutions and results from parent and sibling nodes. This facilitates a continuous refinement of the node in the search tree, thereby enhancing the overall decision-making process. Furthermore, we integrate a Large Language Model (LLM)-based value model to facilitate direct evaluation of each node's solution prior to conducting comprehensive computational rollouts. A hybrid rewarding mechanism is implemented to seamlessly transition the Q-value from LLM-estimated scores to actual performance scores. This allows higher-quality nodes to be traversed earlier. Applied to the various ML tasks, our approach demonstrates a 6% absolute improvement in performance compared to the strong open-source AutoML agents, showcasing its effectiveness in enhancing agentic AutoML systems. Resource available at https://github.com/jokieleung/I-MCTS
SEGMENT+: Long Text Processing with Short-Context Language Models
Oct 09, 2024



There is a growing interest in expanding the input capacity of language models (LMs) across various domains. However, simply increasing the context window does not guarantee robust performance across diverse long-input processing tasks, such as understanding extensive documents and extracting detailed information from lengthy and noisy data. In response, we introduce SEGMENT+, a general framework that enables LMs to handle extended inputs within limited context windows efficiently. SEGMENT+ utilizes structured notes and a filtering module to manage information flow, resulting in a system that is both controllable and interpretable. Our extensive experiments across various model sizes, focusing on long-document question-answering and Needle-in-a-Haystack tasks, demonstrate the effectiveness of SEGMENT+ in improving performance.
A Language Agent for Autonomous Driving
Nov 27, 2023Human-level driving is an ultimate goal of autonomous driving. Conventional approaches formulate autonomous driving as a perception-prediction-planning framework, yet their systems do not capitalize on the inherent reasoning ability and experiential knowledge of humans. In this paper, we propose a fundamental paradigm shift from current pipelines, exploiting Large Language Models (LLMs) as a cognitive agent to integrate human-like intelligence into autonomous driving systems. Our approach, termed Agent-Driver, transforms the traditional autonomous driving pipeline by introducing a versatile tool library accessible via function calls, a cognitive memory of common sense and experiential knowledge for decision-making, and a reasoning engine capable of chain-of-thought reasoning, task planning, motion planning, and self-reflection. Powered by LLMs, our Agent-Driver is endowed with intuitive common sense and robust reasoning capabilities, thus enabling a more nuanced, human-like approach to autonomous driving. We evaluate our approach on the large-scale nuScenes benchmark, and extensive experiments substantiate that our Agent-Driver significantly outperforms the state-of-the-art driving methods by a large margin. Our approach also demonstrates superior interpretability and few-shot learning ability to these methods. Code will be released.
GPT-Driver: Learning to Drive with GPT
Oct 16, 2023



We present a simple yet effective approach that can transform the OpenAI GPT-3.5 model into a reliable motion planner for autonomous vehicles. Motion planning is a core challenge in autonomous driving, aiming to plan a driving trajectory that is safe and comfortable. Existing motion planners predominantly leverage heuristic methods to forecast driving trajectories, yet these approaches demonstrate insufficient generalization capabilities in the face of novel and unseen driving scenarios. In this paper, we propose a novel approach to motion planning that capitalizes on the strong reasoning capabilities and generalization potential inherent to Large Language Models (LLMs). The fundamental insight of our approach is the reformulation of motion planning as a language modeling problem, a perspective not previously explored. Specifically, we represent the planner inputs and outputs as language tokens, and leverage the LLM to generate driving trajectories through a language description of coordinate positions. Furthermore, we propose a novel prompting-reasoning-finetuning strategy to stimulate the numerical reasoning potential of the LLM. With this strategy, the LLM can describe highly precise trajectory coordinates and also its internal decision-making process in natural language. We evaluate our approach on the large-scale nuScenes dataset, and extensive experiments substantiate the effectiveness, generalization ability, and interpretability of our GPT-based motion planner. Code is now available at https://github.com/PointsCoder/GPT-Driver.
Question-Driven Graph Fusion Network For Visual Question Answering
Apr 03, 2022
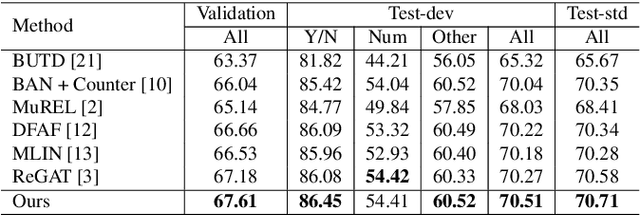
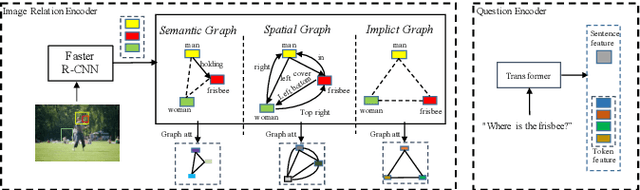
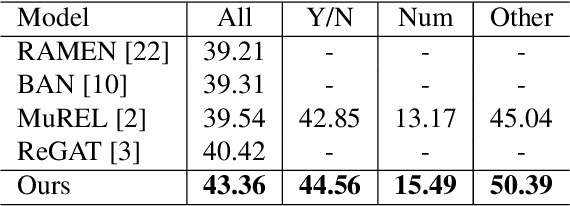
Existing Visual Question Answering (VQA) models have explored various visual relationships between objects in the image to answer complex questions, which inevitably introduces irrelevant information brought by inaccurate object detection and text grounding. To address the problem, we propose a Question-Driven Graph Fusion Network (QD-GFN). It first models semantic, spatial, and implicit visual relations in images by three graph attention networks, then question information is utilized to guide the aggregation process of the three graphs, further, our QD-GFN adopts an object filtering mechanism to remove question-irrelevant objects contained in the image. Experiment results demonstrate that our QD-GFN outperforms the prior state-of-the-art on both VQA 2.0 and VQA-CP v2 datasets. Further analysis shows that both the novel graph aggregation method and object filtering mechanism play a significant role in improving the performance of the model.
Co-VQA : Answering by Interactive Sub Question Sequence
Apr 02, 2022
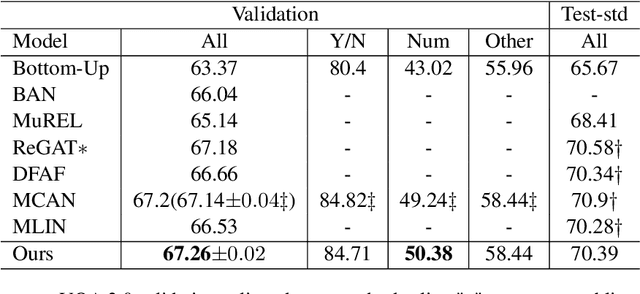
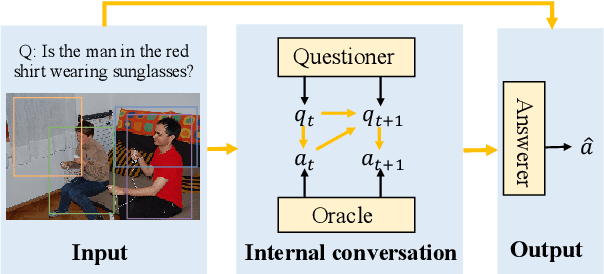
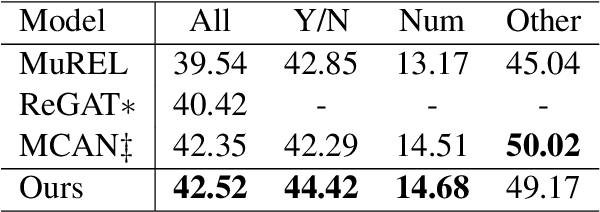
Most existing approaches to Visual Question Answering (VQA) answer questions directly, however, people usually decompose a complex question into a sequence of simple sub questions and finally obtain the answer to the original question after answering the sub question sequence(SQS). By simulating the process, this paper proposes a conversation-based VQA (Co-VQA) framework, which consists of three components: Questioner, Oracle, and Answerer. Questioner raises the sub questions using an extending HRED model, and Oracle answers them one-by-one. An Adaptive Chain Visual Reasoning Model (ACVRM) for Answerer is also proposed, where the question-answer pair is used to update the visual representation sequentially. To perform supervised learning for each model, we introduce a well-designed method to build a SQS for each question on VQA 2.0 and VQA-CP v2 datasets. Experimental results show that our method achieves state-of-the-art on VQA-CP v2. Further analyses show that SQSs help build direct semantic connections between questions and images, provide question-adaptive variable-length reasoning chains, and with explicit interpretability as well as error traceability.
StrucTexT: Structured Text Understanding with Multi-Modal Transformers
Aug 10, 2021
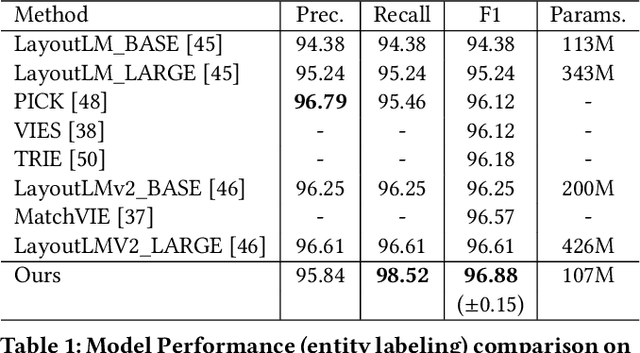
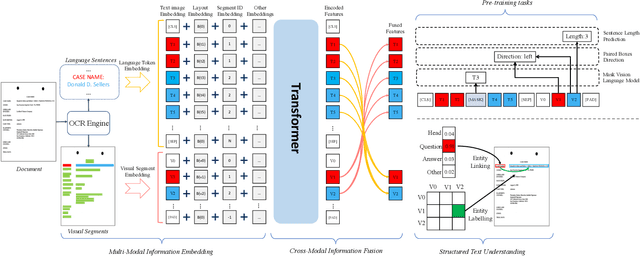
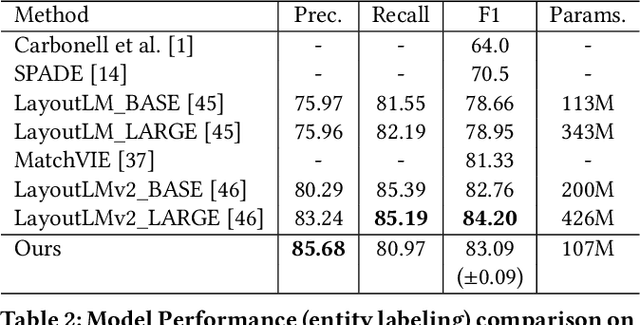
Structured text understanding on Visually Rich Documents (VRDs) is a crucial part of Document Intelligence. Due to the complexity of content and layout in VRDs, structured text understanding has been a challenging task. Most existing studies decoupled this problem into two sub-tasks: entity labeling and entity linking, which require an entire understanding of the context of documents at both token and segment levels. However, little work has been concerned with the solutions that efficiently extract the structured data from different levels. This paper proposes a unified framework named StrucTexT, which is flexible and effective for handling both sub-tasks. Specifically, based on the transformer, we introduce a segment-token aligned encoder to deal with the entity labeling and entity linking tasks at different levels of granularity. Moreover, we design a novel pre-training strategy with three self-supervised tasks to learn a richer representation. StrucTexT uses the existing Masked Visual Language Modeling task and the new Sentence Length Prediction and Paired Boxes Direction tasks to incorporate the multi-modal information across text, image, and layout. We evaluate our method for structured text understanding at segment-level and token-level and show it outperforms the state-of-the-art counterparts with significantly superior performance on the FUNSD, SROIE, and EPHOIE datasets.