 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuestion-Driven Graph Fusion Network For Visual Question Answering
Paper and Code
Apr 03, 2022
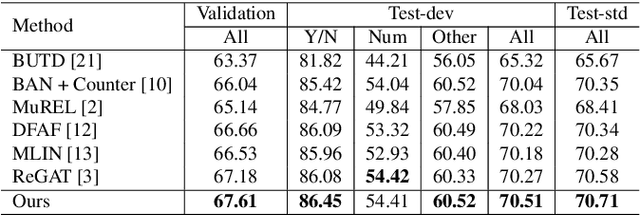
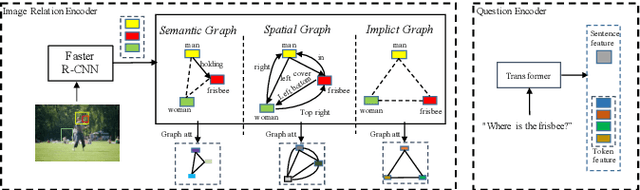
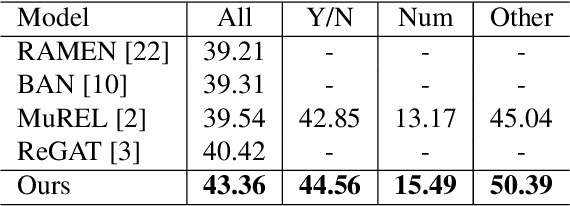
Existing Visual Question Answering (VQA) models have explored various visual relationships between objects in the image to answer complex questions, which inevitably introduces irrelevant information brought by inaccurate object detection and text grounding. To address the problem, we propose a Question-Driven Graph Fusion Network (QD-GFN). It first models semantic, spatial, and implicit visual relations in images by three graph attention networks, then question information is utilized to guide the aggregation process of the three graphs, further, our QD-GFN adopts an object filtering mechanism to remove question-irrelevant objects contained in the image. Experiment results demonstrate that our QD-GFN outperforms the prior state-of-the-art on both VQA 2.0 and VQA-CP v2 datasets. Further analysis shows that both the novel graph aggregation method and object filtering mechanism play a significant role in improving the performance of the model.