 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuestion-Driven Graph Fusion Network For Visual Question Answering
Apr 03, 2022
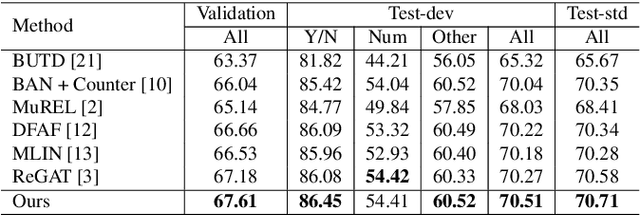
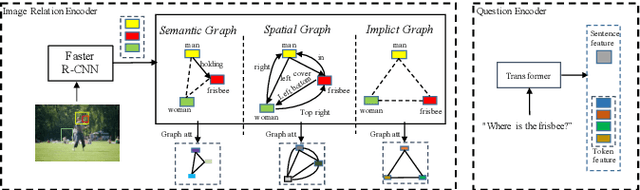
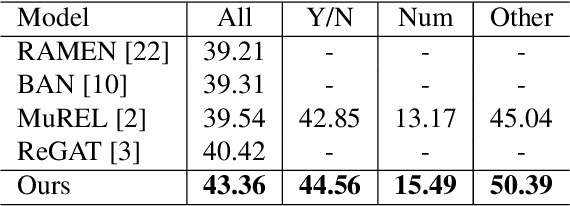
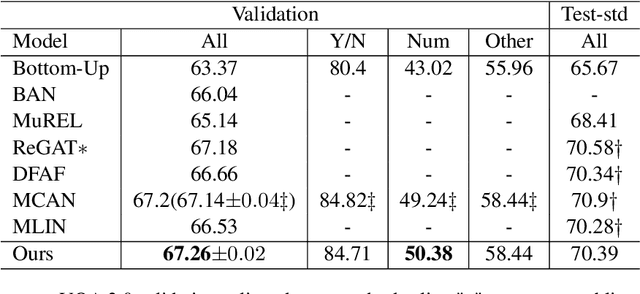
Existing Visual Question Answering (VQA) models have explored various visual relationships between objects in the image to answer complex questions, which inevitably introduces irrelevant information brought by inaccurate object detection and text grounding. To address the problem, we propose a Question-Driven Graph Fusion Network (QD-GFN). It first models semantic, spatial, and implicit visual relations in images by three graph attention networks, then question information is utilized to guide the aggregation process of the three graphs, further, our QD-GFN adopts an object filtering mechanism to remove question-irrelevant objects contained in the image. Experiment results demonstrate that our QD-GFN outperforms the prior state-of-the-art on both VQA 2.0 and VQA-CP v2 datasets. Further analysis shows that both the novel graph aggregation method and object filtering mechanism play a significant role in improving the performance of the model.
Co-VQA : Answering by Interactive Sub Question Sequence
Apr 02, 2022
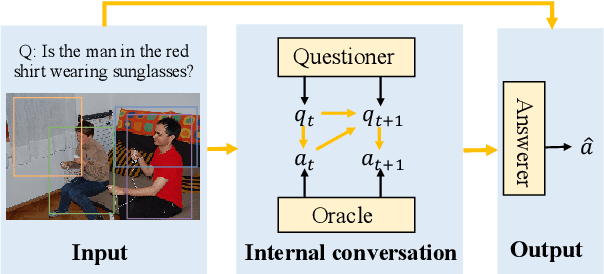
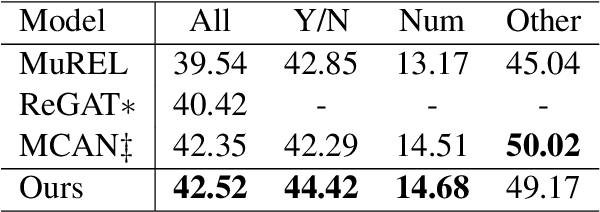
Most existing approaches to Visual Question Answering (VQA) answer questions directly, however, people usually decompose a complex question into a sequence of simple sub questions and finally obtain the answer to the original question after answering the sub question sequence(SQS). By simulating the process, this paper proposes a conversation-based VQA (Co-VQA) framework, which consists of three components: Questioner, Oracle, and Answerer. Questioner raises the sub questions using an extending HRED model, and Oracle answers them one-by-one. An Adaptive Chain Visual Reasoning Model (ACVRM) for Answerer is also proposed, where the question-answer pair is used to update the visual representation sequentially. To perform supervised learning for each model, we introduce a well-designed method to build a SQS for each question on VQA 2.0 and VQA-CP v2 datasets. Experimental results show that our method achieves state-of-the-art on VQA-CP v2. Further analyses show that SQSs help build direct semantic connections between questions and images, provide question-adaptive variable-length reasoning chains, and with explicit interpretability as well as error traceability.