 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobotic Assistant: Completing Collaborative Tasks with Dexterous Vision-Language-Action Models
Oct 29, 2025We adapt a pre-trained Vision-Language-Action (VLA) model (Open-VLA) for dexterous human-robot collaboration with minimal language prompting. Our approach adds (i) FiLM conditioning to visual backbones for task-aware perception, (ii) an auxiliary intent head that predicts collaborator hand pose and target cues, and (iii) action-space post-processing that predicts compact deltas (position/rotation) and PCA-reduced finger joints before mapping to full commands. Using a multi-view, teleoperated Franka and Mimic-hand dataset augmented with MediaPipe hand poses, we demonstrate that delta actions are well-behaved and that four principal components explain ~96% of hand-joint variance. Ablations identify action post-processing as the primary performance driver; auxiliary intent helps, FiLM is mixed, and a directional motion loss is detrimental. A real-time stack (~0.3 s latency on one RTX 4090) composes "pick-up" and "pass" into a long-horizon behavior. We surface "trainer overfitting" to specific demonstrators as the key limitation.
Arnold: a generalist muscle transformer policy
Aug 25, 2025

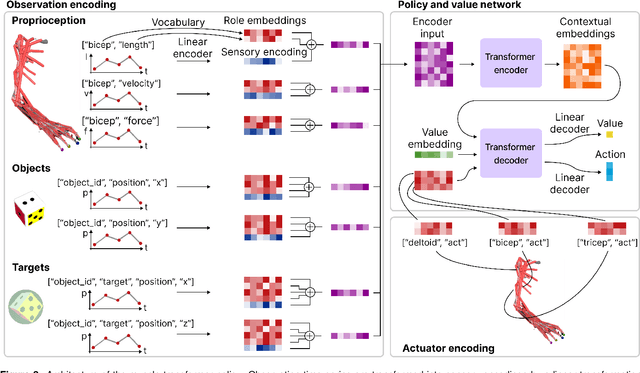

Controlling high-dimensional and nonlinear musculoskeletal models of the human body is a foundational scientific challenge. Recent machine learning breakthroughs have heralded policies that master individual skills like reaching, object manipulation and locomotion in musculoskeletal systems with many degrees of freedom. However, these agents are merely "specialists", achieving high performance for a single skill. In this work, we develop Arnold, a generalist policy that masters multiple tasks and embodiments. Arnold combines behavior cloning and fine-tuning with PPO to achieve expert or super-expert performance in 14 challenging control tasks from dexterous object manipulation to locomotion. A key innovation is Arnold's sensorimotor vocabulary, a compositional representation of the semantics of heterogeneous sensory modalities, objectives, and actuators. Arnold leverages this vocabulary via a transformer architecture to deal with the variable observation and action spaces of each task. This framework supports efficient multi-task, multi-embodiment learning and facilitates rapid adaptation to novel tasks. Finally, we analyze Arnold to provide insights into biological motor control, corroborating recent findings on the limited transferability of muscle synergies across tasks.
RoboVerse: Towards a Unified Platform, Dataset and Benchmark for Scalable and Generalizable Robot Learning
Apr 26, 2025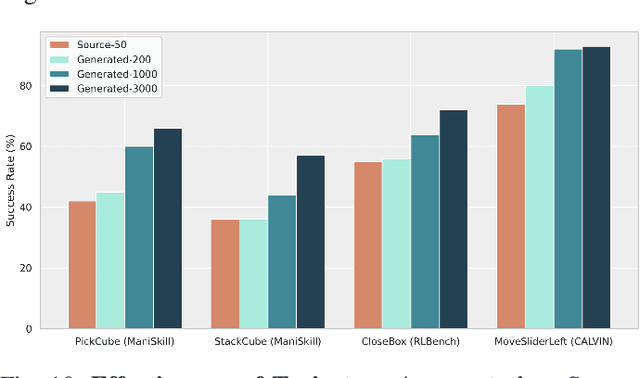



Data scaling and standardized evaluation benchmarks have driven significant advances in natural language processing and computer vision. However, robotics faces unique challenges in scaling data and establishing evaluation protocols. Collecting real-world data is resource-intensive and inefficient, while benchmarking in real-world scenarios remains highly complex. Synthetic data and simulation offer promising alternatives, yet existing efforts often fall short in data quality, diversity, and benchmark standardization. To address these challenges, we introduce RoboVerse, a comprehensive framework comprising a simulation platform, a synthetic dataset, and unified benchmarks. Our simulation platform supports multiple simulators and robotic embodiments, enabling seamless transitions between different environments. The synthetic dataset, featuring high-fidelity physics and photorealistic rendering, is constructed through multiple approaches. Additionally, we propose unified benchmarks for imitation learning and reinforcement learning, enabling evaluation across different levels of generalization. At the core of the simulation platform is MetaSim, an infrastructure that abstracts diverse simulation environments into a universal interface. It restructures existing simulation environments into a simulator-agnostic configuration system, as well as an API aligning different simulator functionalities, such as launching simulation environments, loading assets with initial states, stepping the physics engine, etc. This abstraction ensures interoperability and extensibility. Comprehensive experiments demonstrate that RoboVerse enhances the performance of imitation learning, reinforcement learning, world model learning, and sim-to-real transfer. These results validate the reliability of our dataset and benchmarks, establishing RoboVerse as a robust solution for advancing robot learning.
Bilateral Propagation Network for Depth Completion
Apr 01, 2024



Depth completion aims to derive a dense depth map from sparse depth measurements with a synchronized color image. Current state-of-the-art (SOTA) methods are predominantly propagation-based, which work as an iterative refinement on the initial estimated dense depth. However, the initial depth estimations mostly result from direct applications of convolutional layers on the sparse depth map. In this paper, we present a Bilateral Propagation Network (BP-Net), that propagates depth at the earliest stage to avoid directly convolving on sparse data. Specifically, our approach propagates the target depth from nearby depth measurements via a non-linear model, whose coefficients are generated through a multi-layer perceptron conditioned on both \emph{radiometric difference} and \emph{spatial distance}. By integrating bilateral propagation with multi-modal fusion and depth refinement in a multi-scale framework, our BP-Net demonstrates outstanding performance on both indoor and outdoor scenes. It achieves SOTA on the NYUv2 dataset and ranks 1st on the KITTI depth completion benchmark at the time of submission. Experimental results not only show the effectiveness of bilateral propagation but also emphasize the significance of early-stage propagation in contrast to the refinement stage. Our code and trained models will be available on the project page.
ImageManip: Image-based Robotic Manipulation with Affordance-guided Next View Selection
Oct 13, 2023



In the realm of future home-assistant robots, 3D articulated object manipulation is essential for enabling robots to interact with their environment. Many existing studies make use of 3D point clouds as the primary input for manipulation policies. However, this approach encounters challenges due to data sparsity and the significant cost associated with acquiring point cloud data, which can limit its practicality. In contrast, RGB images offer high-resolution observations using cost effective devices but lack spatial 3D geometric information. To overcome these limitations, we present a novel image-based robotic manipulation framework. This framework is designed to capture multiple perspectives of the target object and infer depth information to complement its geometry. Initially, the system employs an eye-on-hand RGB camera to capture an overall view of the target object. It predicts the initial depth map and a coarse affordance map. The affordance map indicates actionable areas on the object and serves as a constraint for selecting subsequent viewpoints. Based on the global visual prior, we adaptively identify the optimal next viewpoint for a detailed observation of the potential manipulation success area. We leverage geometric consistency to fuse the views, resulting in a refined depth map and a more precise affordance map for robot manipulation decisions. By comparing with prior works that adopt point clouds or RGB images as inputs, we demonstrate the effectiveness and practicality of our method. In the project webpage (https://sites.google.com/view/imagemanip), real world experiments further highlight the potential of our method for practical deployment.
RGBManip: Monocular Image-based Robotic Manipulation through Active Object Pose Estimation
Oct 05, 2023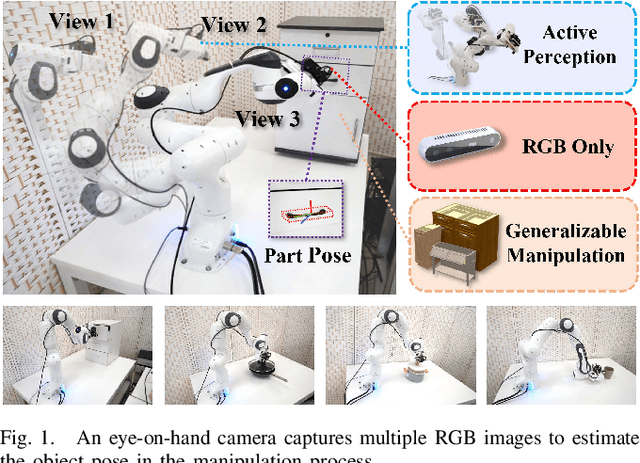
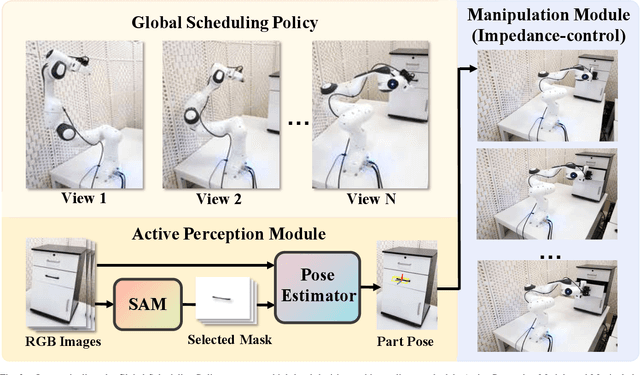

Robotic manipulation requires accurate perception of the environment, which poses a significant challenge due to its inherent complexity and constantly changing nature. In this context, RGB image and point-cloud observations are two commonly used modalities in visual-based robotic manipulation, but each of these modalities have their own limitations. Commercial point-cloud observations often suffer from issues like sparse sampling and noisy output due to the limits of the emission-reception imaging principle. On the other hand, RGB images, while rich in texture information, lack essential depth and 3D information crucial for robotic manipulation. To mitigate these challenges, we propose an image-only robotic manipulation framework that leverages an eye-on-hand monocular camera installed on the robot's parallel gripper. By moving with the robot gripper, this camera gains the ability to actively perceive object from multiple perspectives during the manipulation process. This enables the estimation of 6D object poses, which can be utilized for manipulation. While, obtaining images from more and diverse viewpoints typically improves pose estimation, it also increases the manipulation time. To address this trade-off, we employ a reinforcement learning policy to synchronize the manipulation strategy with active perception, achieving a balance between 6D pose accuracy and manipulation efficiency. Our experimental results in both simulated and real-world environments showcase the state-of-the-art effectiveness of our approach. %, which, to the best of our knowledge, is the first to achieve robust real-world robotic manipulation through active pose estimation. We believe that our method will inspire further research on real-world-oriented robotic manipulation.
Learning Multi-Object Positional Relationships via Emergent Communication
Feb 16, 2023



The study of emergent communication has been dedicated to interactive artificial intelligence. While existing work focuses on communication about single objects or complex image scenes, we argue that communicating relationships between multiple objects is important in more realistic tasks, but understudied. In this paper, we try to fill this gap and focus on emergent communication about positional relationships between two objects. We train agents in the referential game where observations contain two objects, and find that generalization is the major problem when the positional relationship is involved. The key factor affecting the generalization ability of the emergent language is the input variation between Speaker and Listener, which is realized by a random image generator in our work. Further, we find that the learned language can generalize well in a new multi-step MDP task where the positional relationship describes the goal, and performs better than raw-pixel images as well as pre-trained image features, verifying the strong generalization ability of discrete sequences. We also show that language transfer from the referential game performs better in the new task than learning language directly in this task, implying the potential benefits of pre-training in referential games. All in all, our experiments demonstrate the viability and merit of having agents learn to communicate positional relationships between multiple objects through emergent communication.
End-to-End Affordance Learning for Robotic Manipulation
Sep 26, 2022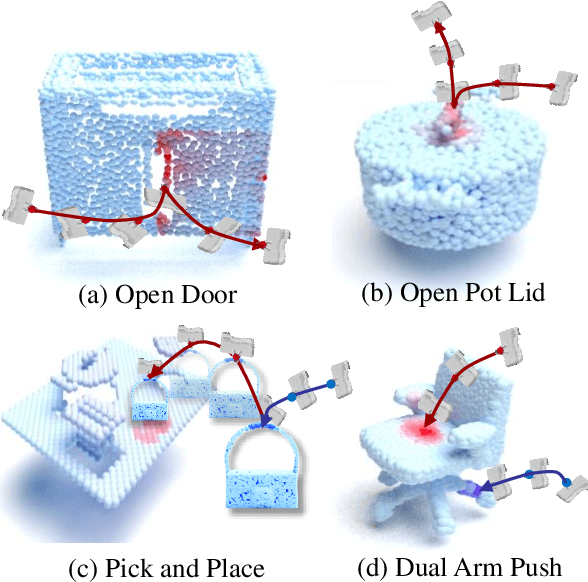
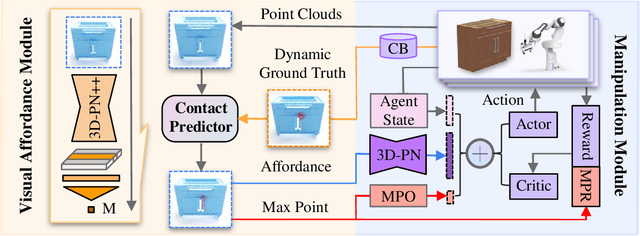

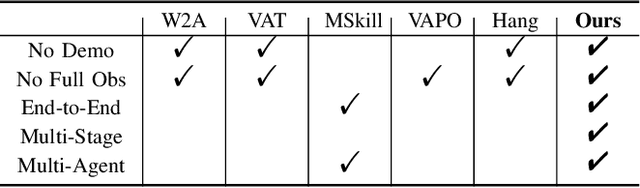
Learning to manipulate 3D objects in an interactive environment has been a challenging problem in Reinforcement Learning (RL). In particular, it is hard to train a policy that can generalize over objects with different semantic categories, diverse shape geometry and versatile functionality. Recently, the technique of visual affordance has shown great prospects in providing object-centric information priors with effective actionable semantics. As such, an effective policy can be trained to open a door by knowing how to exert force on the handle. However, to learn the affordance, it often requires human-defined action primitives, which limits the range of applicable tasks. In this study, we take advantage of visual affordance by using the contact information generated during the RL training process to predict contact maps of interest. Such contact prediction process then leads to an end-to-end affordance learning framework that can generalize over different types of manipulation tasks. Surprisingly, the effectiveness of such framework holds even under the multi-stage and the multi-agent scenarios. We tested our method on eight types of manipulation tasks. Results showed that our methods outperform baseline algorithms, including visual-based affordance methods and RL methods, by a large margin on the success rate. The demonstration can be found at https://sites.google.com/view/rlafford/.