 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeALPS: Attention Localization and Pruning Strategy for Efficient Alignment of Large Language Models
May 24, 2025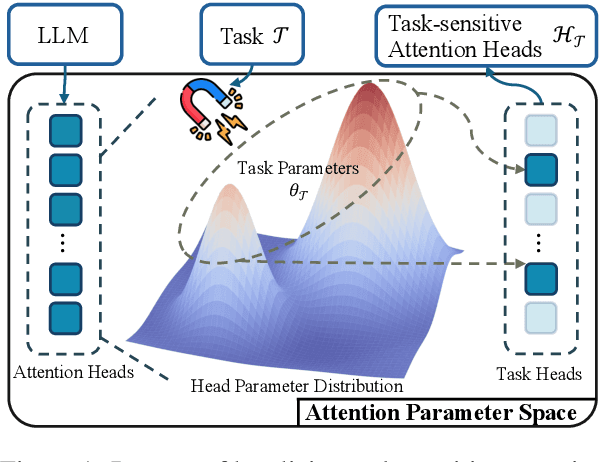
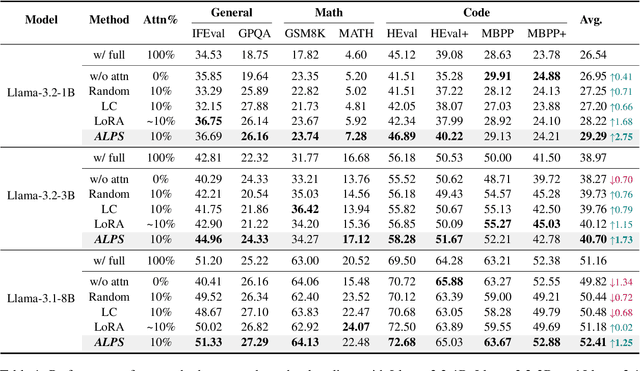

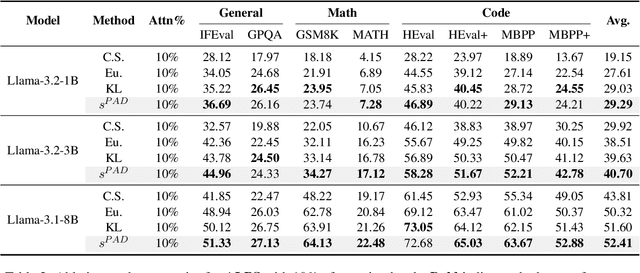
Aligning general-purpose large language models (LLMs) to downstream tasks often incurs significant costs, including constructing task-specific instruction pairs and extensive training adjustments. Prior research has explored various avenues to enhance alignment efficiency, primarily through minimal-data training or data-driven activations to identify key attention heads. However, these approaches inherently introduce data dependency, which hinders generalization and reusability. To address this issue and enhance model alignment efficiency, we propose the \textit{\textbf{A}ttention \textbf{L}ocalization and \textbf{P}runing \textbf{S}trategy (\textbf{ALPS})}, an efficient algorithm that localizes the most task-sensitive attention heads and prunes by restricting attention training updates to these heads, thereby reducing alignment costs. Experimental results demonstrate that our method activates only \textbf{10\%} of attention parameters during fine-tuning while achieving a \textbf{2\%} performance improvement over baselines on three tasks. Moreover, the identified task-specific heads are transferable across datasets and mitigate knowledge forgetting. Our work and findings provide a novel perspective on efficient LLM alignment.
LeTS: Learning to Think-and-Search via Process-and-Outcome Reward Hybridization
May 23, 2025Large language models (LLMs) have demonstrated impressive capabilities in reasoning with the emergence of reasoning models like OpenAI-o1 and DeepSeek-R1. Recent research focuses on integrating reasoning capabilities into the realm of retrieval-augmented generation (RAG) via outcome-supervised reinforcement learning (RL) approaches, while the correctness of intermediate think-and-search steps is usually neglected. To address this issue, we design a process-level reward module to mitigate the unawareness of intermediate reasoning steps in outcome-level supervision without additional annotation. Grounded on this, we propose Learning to Think-and-Search (LeTS), a novel framework that hybridizes stepwise process reward and outcome-based reward to current RL methods for RAG. Extensive experiments demonstrate the generalization and inference efficiency of LeTS across various RAG benchmarks. In addition, these results reveal the potential of process- and outcome-level reward hybridization in boosting LLMs' reasoning ability via RL under other scenarios. The code will be released soon.
D.Va: Validate Your Demonstration First Before You Use It
Feb 19, 2025In-context learning (ICL) has demonstrated significant potential in enhancing the capabilities of large language models (LLMs) during inference. It's well-established that ICL heavily relies on selecting effective demonstrations to generate outputs that better align with the expected results. As for demonstration selection, previous approaches have typically relied on intuitive metrics to evaluate the effectiveness of demonstrations, which often results in limited robustness and poor cross-model generalization capabilities. To tackle these challenges, we propose a novel method, \textbf{D}emonstration \textbf{VA}lidation (\textbf{D.Va}), which integrates a demonstration validation perspective into this field. By introducing the demonstration validation mechanism, our method effectively identifies demonstrations that are both effective and highly generalizable. \textbf{D.Va} surpasses all existing demonstration selection techniques across both natural language understanding (NLU) and natural language generation (NLG) tasks. Additionally, we demonstrate the robustness and generalizability of our approach across various language models with different retrieval models.
DORY: Deliberative Prompt Recovery for LLM
May 31, 2024Prompt recovery in large language models (LLMs) is crucial for understanding how LLMs work and addressing concerns regarding privacy, copyright, etc. The trend towards inference-only APIs complicates this task by restricting access to essential outputs for recovery. To tackle this challenge, we extract prompt-related information from limited outputs and identify a strong(negative) correlation between output probability-based uncertainty and the success of prompt recovery. This finding led to the development of Deliberative PrOmpt RecoverY (DORY), our novel approach that leverages uncertainty to recover prompts accurately. DORY involves reconstructing drafts from outputs, refining these with hints, and filtering out noise based on uncertainty. Our evaluation across diverse LLMs and prompt benchmarks shows that DORY outperforms existing baselines, improving performance by approximately 10.82% and establishing a new state-of-the-art record in prompt recovery tasks. Significantly, DORY operates using a single LLM without any external resources or model, offering a cost-effective, user-friendly prompt recovery solution.