 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTeaching Large Language Models to Express Knowledge Boundary from Their Own Signals
Jun 16, 2024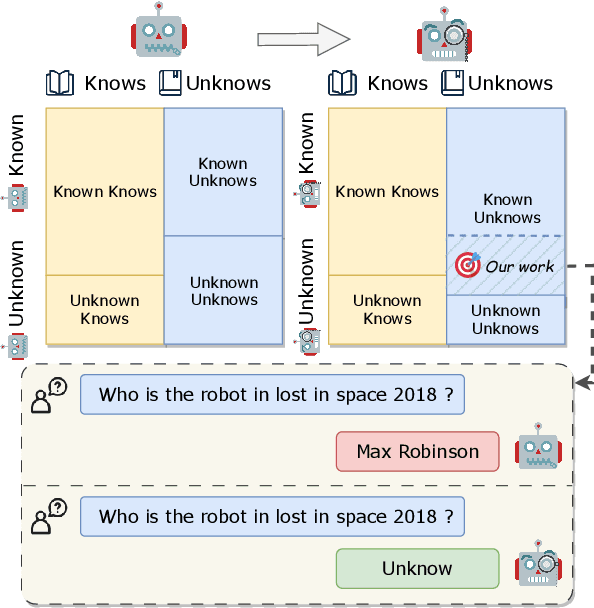
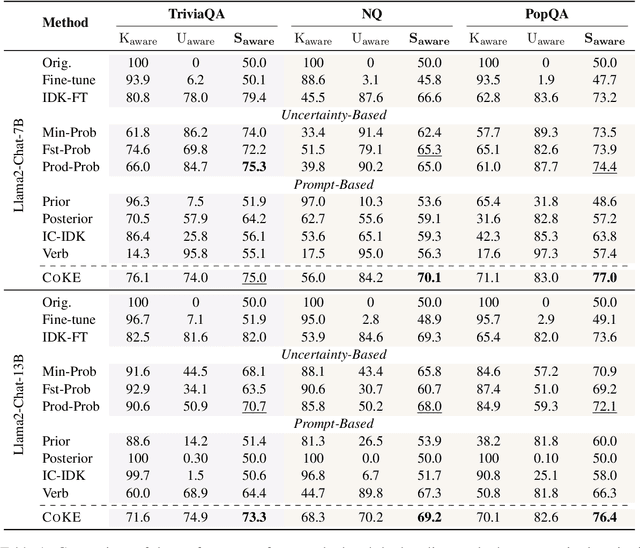
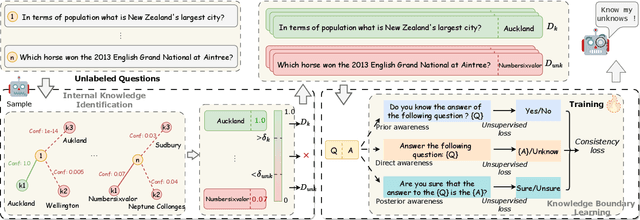
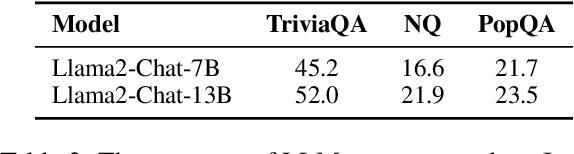
Large language models (LLMs) have achieved great success, but their occasional content fabrication, or hallucination, limits their practical application. Hallucination arises because LLMs struggle to admit ignorance due to inadequate training on knowledge boundaries. We call it a limitation of LLMs that they can not accurately express their knowledge boundary, answering questions they know while admitting ignorance to questions they do not know. In this paper, we aim to teach LLMs to recognize and express their knowledge boundary, so they can reduce hallucinations caused by fabricating when they do not know. We propose CoKE, which first probes LLMs' knowledge boundary via internal confidence given a set of questions, and then leverages the probing results to elicit the expression of the knowledge boundary. Extensive experiments show CoKE helps LLMs express knowledge boundaries, answering known questions while declining unknown ones, significantly improving in-domain and out-of-domain performance.
Semi-Supervised Clustering with Contrastive Learning for Discovering New Intents
Jan 07, 2022



Most dialogue systems in real world rely on predefined intents and answers for QA service, so discovering potential intents from large corpus previously is really important for building such dialogue services. Considering that most scenarios have few intents known already and most intents waiting to be discovered, we focus on semi-supervised text clustering and try to make the proposed method benefit from labeled samples for better overall clustering performance. In this paper, we propose Deep Contrastive Semi-supervised Clustering (DCSC), which aims to cluster text samples in a semi-supervised way and provide grouped intents to operation staff. To make DCSC fully utilize the limited known intents, we propose a two-stage training procedure for DCSC, in which DCSC will be trained on both labeled samples and unlabeled samples, and achieve better text representation and clustering performance. We conduct experiments on two public datasets to compare our model with several popular methods, and the results show DCSC achieve best performance across all datasets and circumstances, indicating the effect of the improvements in our work.