 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemi-Supervised Clustering with Contrastive Learning for Discovering New Intents
Jan 07, 2022



Most dialogue systems in real world rely on predefined intents and answers for QA service, so discovering potential intents from large corpus previously is really important for building such dialogue services. Considering that most scenarios have few intents known already and most intents waiting to be discovered, we focus on semi-supervised text clustering and try to make the proposed method benefit from labeled samples for better overall clustering performance. In this paper, we propose Deep Contrastive Semi-supervised Clustering (DCSC), which aims to cluster text samples in a semi-supervised way and provide grouped intents to operation staff. To make DCSC fully utilize the limited known intents, we propose a two-stage training procedure for DCSC, in which DCSC will be trained on both labeled samples and unlabeled samples, and achieve better text representation and clustering performance. We conduct experiments on two public datasets to compare our model with several popular methods, and the results show DCSC achieve best performance across all datasets and circumstances, indicating the effect of the improvements in our work.
NVAE-GAN Based Approach for Unsupervised Time Series Anomaly Detection
Jan 08, 2021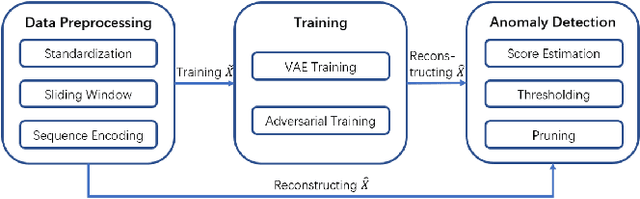



In recent studies, Lots of work has been done to solve time series anomaly detection by applying Variational Auto-Encoders (VAEs). Time series anomaly detection is a very common but challenging task in many industries, which plays an important role in network monitoring, facility maintenance, information security, and so on. However, it is very difficult to detect anomalies in time series with high accuracy, due to noisy data collected from real world, and complicated abnormal patterns. From recent studies, we are inspired by Nouveau VAE (NVAE) and propose our anomaly detection model: Time series to Image VAE (T2IVAE), an unsupervised model based on NVAE for univariate series, transforming 1D time series to 2D image as input, and adopting the reconstruction error to detect anomalies. Besides, we also apply the Generative Adversarial Networks based techniques to T2IVAE training strategy, aiming to reduce the overfitting. We evaluate our model performance on three datasets, and compare it with other several popular models using F1 score. T2IVAE achieves 0.639 on Numenta Anomaly Benchmark, 0.651 on public dataset from NASA, and 0.504 on our dataset collected from real-world scenario, outperforms other comparison models.