 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep learning-based estimation of whole-body kinematics from multi-view images
Jul 12, 2023It is necessary to analyze the whole-body kinematics (including joint locations and joint angles) to assess risks of fatal and musculoskeletal injuries in occupational tasks. Human pose estimation has gotten more attention in recent years as a method to minimize the errors in determining joint locations. However, the joint angles are not often estimated, nor is the quality of joint angle estimation assessed. In this paper, we presented an end-to-end approach on direct joint angle estimation from multi-view images. Our method leveraged the volumetric pose representation and mapped the rotation representation to a continuous space where each rotation was uniquely represented. We also presented a new kinematic dataset in the domain of residential roofing with a data processing pipeline to generate necessary annotations for the supervised training procedure on direct joint angle estimation. We achieved a mean angle error of $7.19^\circ$ on the new Roofing dataset and $8.41^\circ$ on the Human3.6M dataset, paving the way for employment of on-site kinematic analysis using multi-view images.
AdaK-NER: An Adaptive Top-K Approach for Named Entity Recognition with Incomplete Annotations
Sep 11, 2021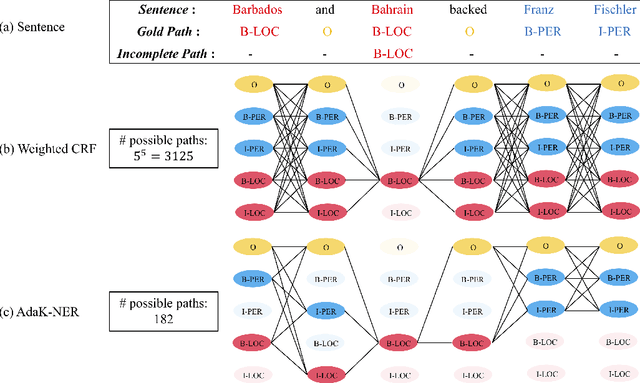

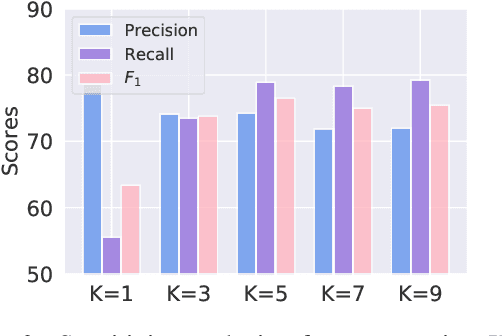
State-of-the-art Named Entity Recognition(NER) models rely heavily on large amountsof fully annotated training data. However, ac-cessible data are often incompletely annotatedsince the annotators usually lack comprehen-sive knowledge in the target domain. Normallythe unannotated tokens are regarded as non-entities by default, while we underline thatthese tokens could either be non-entities orpart of any entity. Here, we study NER mod-eling with incomplete annotated data whereonly a fraction of the named entities are la-beled, and the unlabeled tokens are equiva-lently multi-labeled by every possible label.Taking multi-labeled tokens into account, thenumerous possible paths can distract the train-ing model from the gold path (ground truthlabel sequence), and thus hinders the learn-ing ability. In this paper, we propose AdaK-NER, named the adaptive top-Kapproach, tohelp the model focus on a smaller feasible re-gion where the gold path is more likely to belocated. We demonstrate the superiority ofour approach through extensive experimentson both English and Chinese datasets, aver-agely improving 2% in F-score on the CoNLL-2003 and over 10% on two Chinese datasetscompared with the prior state-of-the-art works.
An Alignment-Agnostic Model for Chinese Text Error Correction
Apr 15, 2021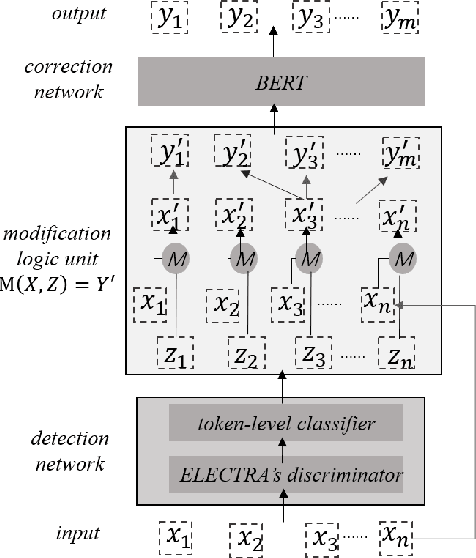
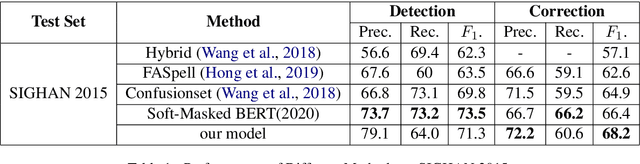

This paper investigates how to correct Chinese text errors with types of mistaken, missing and redundant characters, which is common for Chinese native speakers. Most existing models based on detect-correct framework can correct mistaken characters errors, but they cannot deal with missing or redundant characters. The reason is that lengths of sentences before and after correction are not the same, leading to the inconsistence between model inputs and outputs. Although the Seq2Seq-based or sequence tagging methods provide solutions to the problem and achieved relatively good results on English context, but they do not perform well in Chinese context according to our experimental results. In our work, we propose a novel detect-correct framework which is alignment-agnostic, meaning that it can handle both text aligned and non-aligned occasions, and it can also serve as a cold start model when there are no annotated data provided. Experimental results on three datasets demonstrate that our method is effective and achieves the best performance among existing published models.
NVAE-GAN Based Approach for Unsupervised Time Series Anomaly Detection
Jan 08, 2021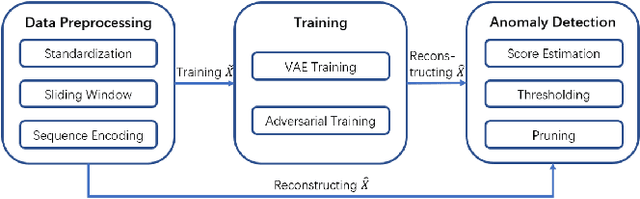



In recent studies, Lots of work has been done to solve time series anomaly detection by applying Variational Auto-Encoders (VAEs). Time series anomaly detection is a very common but challenging task in many industries, which plays an important role in network monitoring, facility maintenance, information security, and so on. However, it is very difficult to detect anomalies in time series with high accuracy, due to noisy data collected from real world, and complicated abnormal patterns. From recent studies, we are inspired by Nouveau VAE (NVAE) and propose our anomaly detection model: Time series to Image VAE (T2IVAE), an unsupervised model based on NVAE for univariate series, transforming 1D time series to 2D image as input, and adopting the reconstruction error to detect anomalies. Besides, we also apply the Generative Adversarial Networks based techniques to T2IVAE training strategy, aiming to reduce the overfitting. We evaluate our model performance on three datasets, and compare it with other several popular models using F1 score. T2IVAE achieves 0.639 on Numenta Anomaly Benchmark, 0.651 on public dataset from NASA, and 0.504 on our dataset collected from real-world scenario, outperforms other comparison models.