 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCo-Evolutionary Multi-Modal Alignment via Structured Adversarial Evolution
Mar 02, 2026Adversarial behavior plays a central role in aligning large language models with human values. However, existing alignment methods largely rely on static adversarial settings, which fundamentally limit robustness, particularly in multimodal settings with a larger attack surface. In this work, we move beyond static adversarial supervision and introduce co-evolutionary alignment with evolving attacks, instantiated by CEMMA (Co-Evolutionary Multi-Modal Alignment), an automated and adaptive framework for multimodal safety alignment. We introduce an Evolutionary Attacker that decomposes adversarial prompts into method templates and harmful intents. By employing genetic operators, including mutation, crossover, and differential evolution, it enables simple seed attacks to inherit the structural efficacy of sophisticated jailbreaks. The Adaptive Defender is iteratively updated on the synthesized hard negatives, forming a closed-loop process that adapts alignment to evolving attacks. Experiments show that the Evolutionary Attacker substantially increases red-teaming jailbreak attack success rate (ASR), while the Adaptive Defender improves robustness and generalization across benchmarks with higher data efficiency, without inducing excessive benign refusal, and remains compatible with inference-time defenses such as AdaShield.
UACER: An Uncertainty-Aware Critic Ensemble Framework for Robust Adversarial Reinforcement Learning
Dec 11, 2025Robust adversarial reinforcement learning has emerged as an effective paradigm for training agents to handle uncertain disturbance in real environments, with critical applications in sequential decision-making domains such as autonomous driving and robotic control. Within this paradigm, agent training is typically formulated as a zero-sum Markov game between a protagonist and an adversary to enhance policy robustness. However, the trainable nature of the adversary inevitably induces non-stationarity in the learning dynamics, leading to exacerbated training instability and convergence difficulties, particularly in high-dimensional complex environments. In this paper, we propose a novel approach, Uncertainty-Aware Critic Ensemble for robust adversarial Reinforcement learning (UACER), which consists of two strategies: 1) Diversified critic ensemble: a diverse set of K critic networks is exploited in parallel to stabilize Q-value estimation rather than conventional single-critic architectures for both variance reduction and robustness enhancement. 2) Time-varying Decay Uncertainty (TDU) mechanism: advancing beyond simple linear combinations, we develop a variance-derived Q-value aggregation strategy that explicitly incorporates epistemic uncertainty to dynamically regulate the exploration-exploitation trade-off while simultaneously stabilizing the training process. Comprehensive experiments across several MuJoCo control problems validate the superior effectiveness of UACER, outperforming state-of-the-art methods in terms of overall performance, stability, and efficiency.
Sample By Step, Optimize By Chunk: Chunk-Level GRPO For Text-to-Image Generation
Oct 24, 2025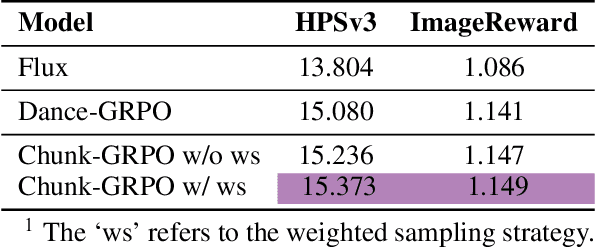
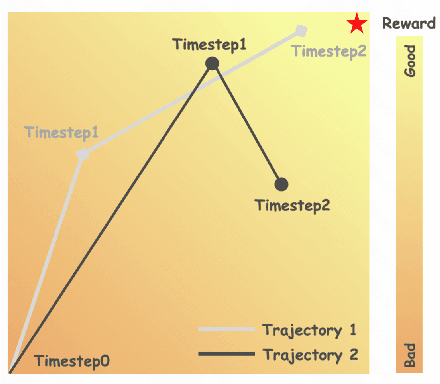
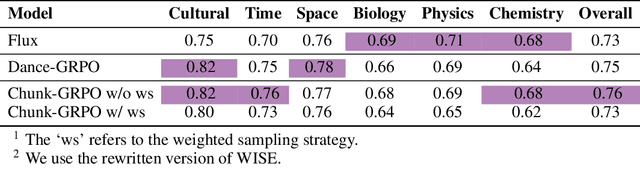
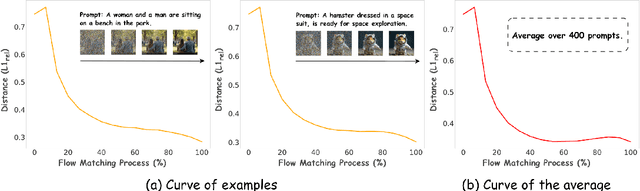
Group Relative Policy Optimization (GRPO) has shown strong potential for flow-matching-based text-to-image (T2I) generation, but it faces two key limitations: inaccurate advantage attribution, and the neglect of temporal dynamics of generation. In this work, we argue that shifting the optimization paradigm from the step level to the chunk level can effectively alleviate these issues. Building on this idea, we propose Chunk-GRPO, the first chunk-level GRPO-based approach for T2I generation. The insight is to group consecutive steps into coherent 'chunk's that capture the intrinsic temporal dynamics of flow matching, and to optimize policies at the chunk level. In addition, we introduce an optional weighted sampling strategy to further enhance performance. Extensive experiments show that ChunkGRPO achieves superior results in both preference alignment and image quality, highlighting the promise of chunk-level optimization for GRPO-based methods.
Distribution Preference Optimization: A Fine-grained Perspective for LLM Unlearning
Oct 06, 2025As Large Language Models (LLMs) demonstrate remarkable capabilities learned from vast corpora, concerns regarding data privacy and safety are receiving increasing attention. LLM unlearning, which aims to remove the influence of specific data while preserving overall model utility, is becoming an important research area. One of the mainstream unlearning classes is optimization-based methods, which achieve forgetting directly through fine-tuning, exemplified by Negative Preference Optimization (NPO). However, NPO's effectiveness is limited by its inherent lack of explicit positive preference signals. Attempts to introduce such signals by constructing preferred responses often necessitate domain-specific knowledge or well-designed prompts, fundamentally restricting their generalizability. In this paper, we shift the focus to the distribution-level, directly targeting the next-token probability distribution instead of entire responses, and derive a novel unlearning algorithm termed \textbf{Di}stribution \textbf{P}reference \textbf{O}ptimization (DiPO). We show that the requisite preference distribution pairs for DiPO, which are distributions over the model's output tokens, can be constructed by selectively amplifying or suppressing the model's high-confidence output logits, thereby effectively overcoming NPO's limitations. We theoretically prove the consistency of DiPO's loss function with the desired unlearning direction. Extensive experiments demonstrate that DiPO achieves a strong trade-off between model utility and forget quality. Notably, DiPO attains the highest forget quality on the TOFU benchmark, and maintains leading scalability and sustainability in utility preservation on the MUSE benchmark.
Reinforcement Fine-Tuning Powers Reasoning Capability of Multimodal Large Language Models
May 24, 2025Standing in 2025, at a critical juncture in the pursuit of Artificial General Intelligence (AGI), reinforcement fine-tuning (RFT) has demonstrated significant potential in enhancing the reasoning capability of large language models (LLMs) and has led to the development of cutting-edge AI models such as OpenAI-o1 and DeepSeek-R1. Moreover, the efficient application of RFT to enhance the reasoning capability of multimodal large language models (MLLMs) has attracted widespread attention from the community. In this position paper, we argue that reinforcement fine-tuning powers the reasoning capability of multimodal large language models. To begin with, we provide a detailed introduction to the fundamental background knowledge that researchers interested in this field should be familiar with. Furthermore, we meticulously summarize the improvements of RFT in powering reasoning capability of MLLMs into five key points: diverse modalities, diverse tasks and domains, better training algorithms, abundant benchmarks and thriving engineering frameworks. Finally, we propose five promising directions for future research that the community might consider. We hope that this position paper will provide valuable insights to the community at this pivotal stage in the advancement toward AGI. Summary of works done on RFT for MLLMs is available at https://github.com/Sun-Haoyuan23/Awesome-RL-based-Reasoning-MLLMs.
Generalizing Alignment Paradigm of Text-to-Image Generation with Preferences through $f$-divergence Minimization
Sep 15, 2024
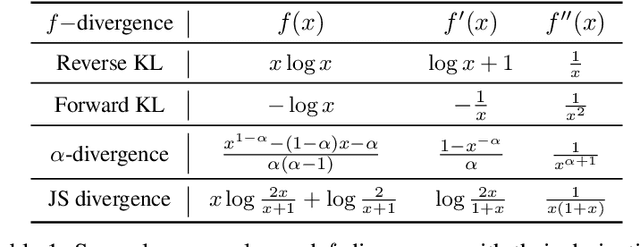
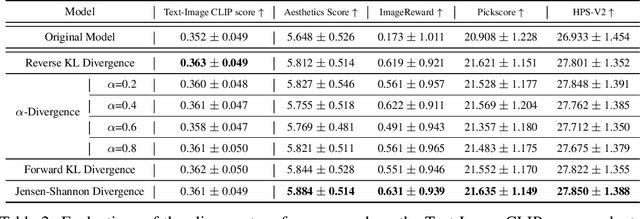
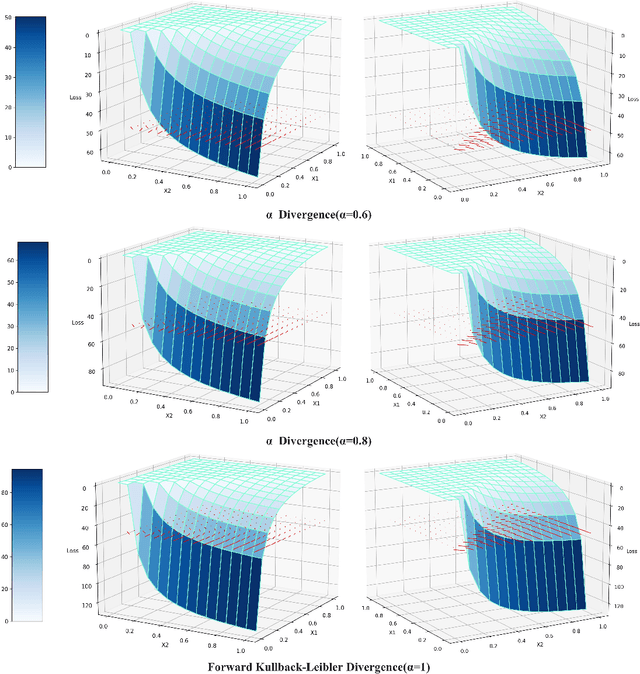
Direct Preference Optimization (DPO) has recently expanded its successful application from aligning large language models (LLMs) to aligning text-to-image models with human preferences, which has generated considerable interest within the community. However, we have observed that these approaches rely solely on minimizing the reverse Kullback-Leibler divergence during alignment process between the fine-tuned model and the reference model, neglecting the incorporation of other divergence constraints. In this study, we focus on extending reverse Kullback-Leibler divergence in the alignment paradigm of text-to-image models to $f$-divergence, which aims to garner better alignment performance as well as good generation diversity. We provide the generalized formula of the alignment paradigm under the $f$-divergence condition and thoroughly analyze the impact of different divergence constraints on alignment process from the perspective of gradient fields. We conduct comprehensive evaluation on image-text alignment performance, human value alignment performance and generation diversity performance under different divergence constraints, and the results indicate that alignment based on Jensen-Shannon divergence achieves the best trade-off among them. The option of divergence employed for aligning text-to-image models significantly impacts the trade-off between alignment performance (especially human value alignment) and generation diversity, which highlights the necessity of selecting an appropriate divergence for practical applications.
Probing the Safety Response Boundary of Large Language Models via Unsafe Decoding Path Generation
Aug 21, 2024



Large Language Models (LLMs) are implicit troublemakers. While they provide valuable insights and assist in problem-solving, they can also potentially serve as a resource for malicious activities. Implementing safety alignment could mitigate the risk of LLMs generating harmful responses. We argue that: even when an LLM appears to successfully block harmful queries, there may still be hidden vulnerabilities that could act as ticking time bombs. To identify these underlying weaknesses, we propose to use a cost value model as both a detector and an attacker. Trained on external or self-generated harmful datasets, the cost value model could successfully influence the original safe LLM to output toxic content in decoding process. For instance, LLaMA-2-chat 7B outputs 39.18% concrete toxic content, along with only 22.16% refusals without any harmful suffixes. These potential weaknesses can then be exploited via prompt optimization such as soft prompts on images. We name this decoding strategy: Jailbreak Value Decoding (JVD), emphasizing that seemingly secure LLMs may not be as safe as we initially believe. They could be used to gather harmful data or launch covert attacks.
QPO: Query-dependent Prompt Optimization via Multi-Loop Offline Reinforcement Learning
Aug 20, 2024Prompt engineering has demonstrated remarkable success in enhancing the performance of large language models (LLMs) across diverse tasks. However, most existing prompt optimization methods only focus on the task-level performance, overlooking the importance of query-preferred prompts, which leads to suboptimal performances. Additionally, these methods rely heavily on frequent interactions with LLMs to obtain feedback for guiding the optimization process, incurring substantial redundant interaction costs. In this paper, we introduce Query-dependent Prompt Optimization (QPO), which leverages multi-loop offline reinforcement learning to iteratively fine-tune a small pretrained language model to generate optimal prompts tailored to the input queries, thus significantly improving the prompting effect on the large target LLM. We derive insights from offline prompting demonstration data, which already exists in large quantities as a by-product of benchmarking diverse prompts on open-sourced tasks, thereby circumventing the expenses of online interactions. Furthermore, we continuously augment the offline dataset with the generated prompts in each loop, as the prompts from the fine-tuned model are supposed to outperform the source prompts in the original dataset. These iterative loops bootstrap the model towards generating optimal prompts. Experiments on various LLM scales and diverse NLP and math tasks demonstrate the efficacy and cost-efficiency of our method in both zero-shot and few-shot scenarios.
DEER: A Delay-Resilient Framework for Reinforcement Learning with Variable Delays
Jun 05, 2024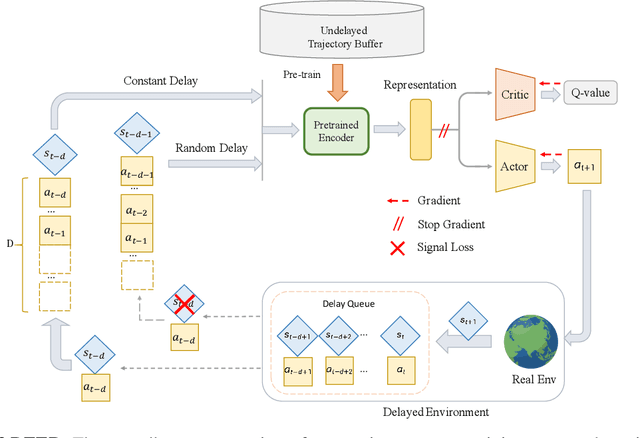
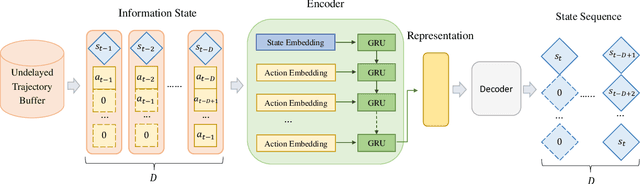
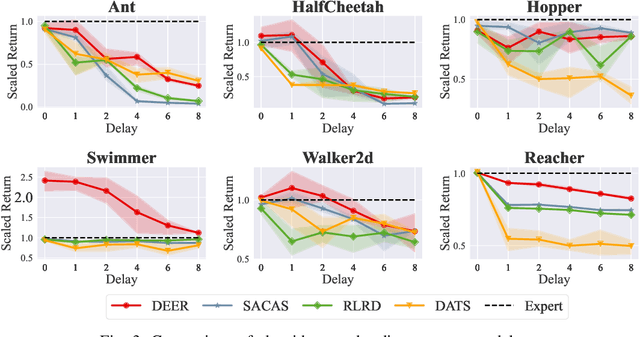
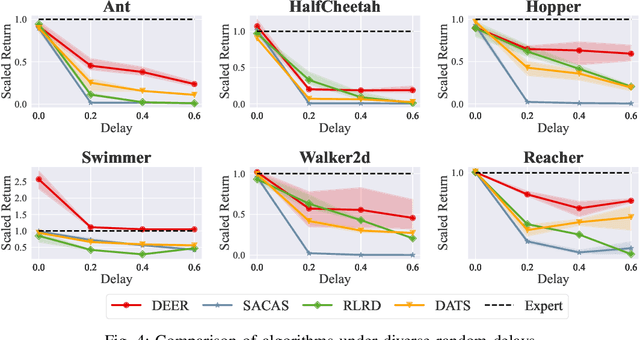
Classic reinforcement learning (RL) frequently confronts challenges in tasks involving delays, which cause a mismatch between received observations and subsequent actions, thereby deviating from the Markov assumption. Existing methods usually tackle this issue with end-to-end solutions using state augmentation. However, these black-box approaches often involve incomprehensible processes and redundant information in the information states, causing instability and potentially undermining the overall performance. To alleviate the delay challenges in RL, we propose $\textbf{DEER (Delay-resilient Encoder-Enhanced RL)}$, a framework designed to effectively enhance the interpretability and address the random delay issues. DEER employs a pretrained encoder to map delayed states, along with their variable-length past action sequences resulting from different delays, into hidden states, which is trained on delay-free environment datasets. In a variety of delayed scenarios, the trained encoder can seamlessly integrate with standard RL algorithms without requiring additional modifications and enhance the delay-solving capability by simply adapting the input dimension of the original algorithms. We evaluate DEER through extensive experiments on Gym and Mujoco environments. The results confirm that DEER is superior to state-of-the-art RL algorithms in both constant and random delay settings.
A Method on Searching Better Activation Functions
May 22, 2024



The success of artificial neural networks (ANNs) hinges greatly on the judicious selection of an activation function, introducing non-linearity into network and enabling them to model sophisticated relationships in data. However, the search of activation functions has largely relied on empirical knowledge in the past, lacking theoretical guidance, which has hindered the identification of more effective activation functions. In this work, we offer a proper solution to such issue. Firstly, we theoretically demonstrate the existence of the worst activation function with boundary conditions (WAFBC) from the perspective of information entropy. Furthermore, inspired by the Taylor expansion form of information entropy functional, we propose the Entropy-based Activation Function Optimization (EAFO) methodology. EAFO methodology presents a novel perspective for designing static activation functions in deep neural networks and the potential of dynamically optimizing activation during iterative training. Utilizing EAFO methodology, we derive a novel activation function from ReLU, known as Correction Regularized ReLU (CRReLU). Experiments conducted with vision transformer and its variants on CIFAR-10, CIFAR-100 and ImageNet-1K datasets demonstrate the superiority of CRReLU over existing corrections of ReLU. Extensive empirical studies on task of large language model (LLM) fine-tuning, CRReLU exhibits superior performance compared to GELU, suggesting its broader potential for practical applications.