 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConditioning Matters: Training Diffusion Policies is Faster Than You Think
May 16, 2025Diffusion policies have emerged as a mainstream paradigm for building vision-language-action (VLA) models. Although they demonstrate strong robot control capabilities, their training efficiency remains suboptimal. In this work, we identify a fundamental challenge in conditional diffusion policy training: when generative conditions are hard to distinguish, the training objective degenerates into modeling the marginal action distribution, a phenomenon we term loss collapse. To overcome this, we propose Cocos, a simple yet general solution that modifies the source distribution in the conditional flow matching to be condition-dependent. By anchoring the source distribution around semantics extracted from condition inputs, Cocos encourages stronger condition integration and prevents the loss collapse. We provide theoretical justification and extensive empirical results across simulation and real-world benchmarks. Our method achieves faster convergence and higher success rates than existing approaches, matching the performance of large-scale pre-trained VLAs using significantly fewer gradient steps and parameters. Cocos is lightweight, easy to implement, and compatible with diverse policy architectures, offering a general-purpose improvement to diffusion policy training.
EmbodiedMAE: A Unified 3D Multi-Modal Representation for Robot Manipulation
May 15, 2025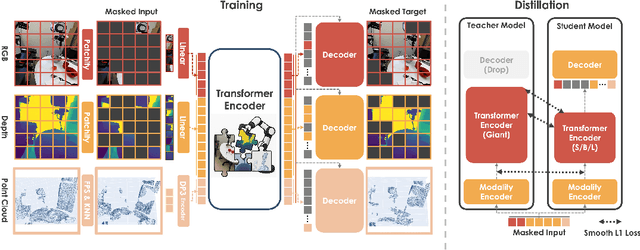


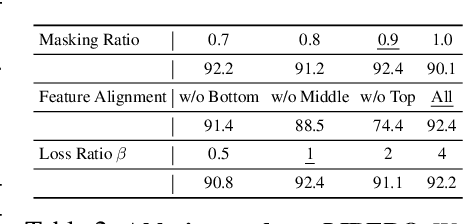
We present EmbodiedMAE, a unified 3D multi-modal representation for robot manipulation. Current approaches suffer from significant domain gaps between training datasets and robot manipulation tasks, while also lacking model architectures that can effectively incorporate 3D information. To overcome these limitations, we enhance the DROID dataset with high-quality depth maps and point clouds, constructing DROID-3D as a valuable supplement for 3D embodied vision research. Then we develop EmbodiedMAE, a multi-modal masked autoencoder that simultaneously learns representations across RGB, depth, and point cloud modalities through stochastic masking and cross-modal fusion. Trained on DROID-3D, EmbodiedMAE consistently outperforms state-of-the-art vision foundation models (VFMs) in both training efficiency and final performance across 70 simulation tasks and 20 real-world robot manipulation tasks on two robot platforms. The model exhibits strong scaling behavior with size and promotes effective policy learning from 3D inputs. Experimental results establish EmbodiedMAE as a reliable unified 3D multi-modal VFM for embodied AI systems, particularly in precise tabletop manipulation settings where spatial perception is critical.
From Seeing to Doing: Bridging Reasoning and Decision for Robotic Manipulation
May 13, 2025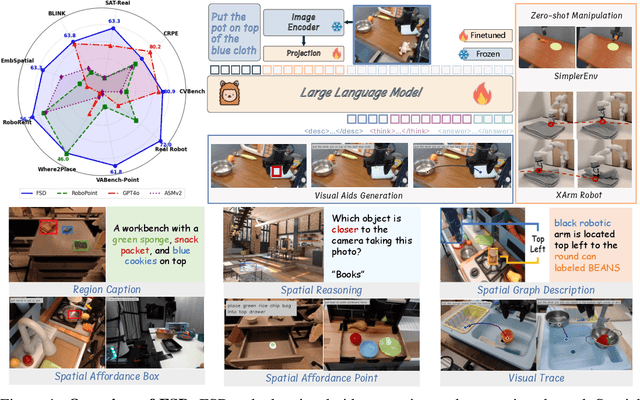

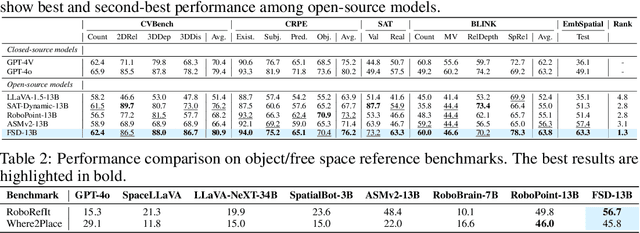
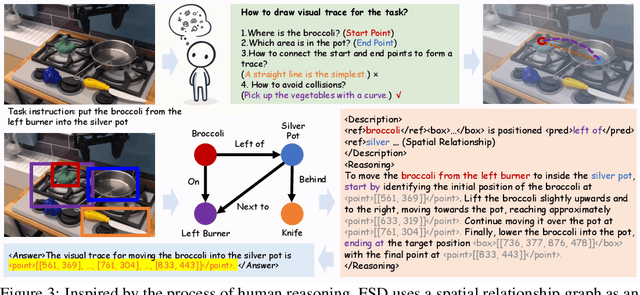
Achieving generalization in robotic manipulation remains a critical challenge, particularly for unseen scenarios and novel tasks. Current Vision-Language-Action (VLA) models, while building on top of general Vision-Language Models (VLMs), still fall short of achieving robust zero-shot performance due to the scarcity and heterogeneity prevalent in embodied datasets. To address these limitations, we propose FSD (From Seeing to Doing), a novel vision-language model that generates intermediate representations through spatial relationship reasoning, providing fine-grained guidance for robotic manipulation. Our approach combines a hierarchical data pipeline for training with a self-consistency mechanism that aligns spatial coordinates with visual signals. Through extensive experiments, we comprehensively validated FSD's capabilities in both "seeing" and "doing," achieving outstanding performance across 8 benchmarks for general spatial reasoning and embodied reference abilities, as well as on our proposed more challenging benchmark VABench. We also verified zero-shot capabilities in robot manipulation, demonstrating significant performance improvements over baseline methods in both SimplerEnv and real robot settings. Experimental results show that FSD achieves 54.1% success rate in SimplerEnv and 72% success rate across 8 real-world tasks, outperforming the strongest baseline by 30%.
MODULI: Unlocking Preference Generalization via Diffusion Models for Offline Multi-Objective Reinforcement Learning
Aug 28, 2024



Multi-objective Reinforcement Learning (MORL) seeks to develop policies that simultaneously optimize multiple conflicting objectives, but it requires extensive online interactions. Offline MORL provides a promising solution by training on pre-collected datasets to generalize to any preference upon deployment. However, real-world offline datasets are often conservatively and narrowly distributed, failing to comprehensively cover preferences, leading to the emergence of out-of-distribution (OOD) preference areas. Existing offline MORL algorithms exhibit poor generalization to OOD preferences, resulting in policies that do not align with preferences. Leveraging the excellent expressive and generalization capabilities of diffusion models, we propose MODULI (Multi-objective Diffusion Planner with Sliding Guidance), which employs a preference-conditioned diffusion model as a planner to generate trajectories that align with various preferences and derive action for decision-making. To achieve accurate generation, MODULI introduces two return normalization methods under diverse preferences for refining guidance. To further enhance generalization to OOD preferences, MODULI proposes a novel sliding guidance mechanism, which involves training an additional slider adapter to capture the direction of preference changes. Incorporating the slider, it transitions from in-distribution (ID) preferences to generating OOD preferences, patching, and extending the incomplete Pareto front. Extensive experiments on the D4MORL benchmark demonstrate that our algorithm outperforms state-of-the-art Offline MORL baselines, exhibiting excellent generalization to OOD preferences.
CleanDiffuser: An Easy-to-use Modularized Library for Diffusion Models in Decision Making
Jun 13, 2024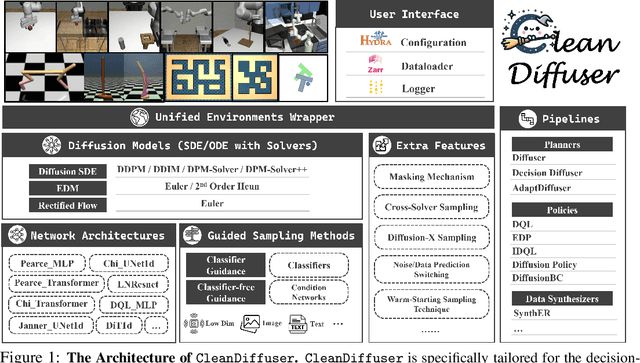
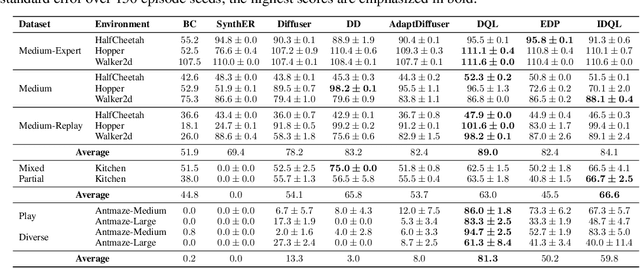
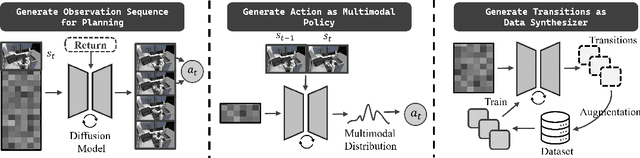
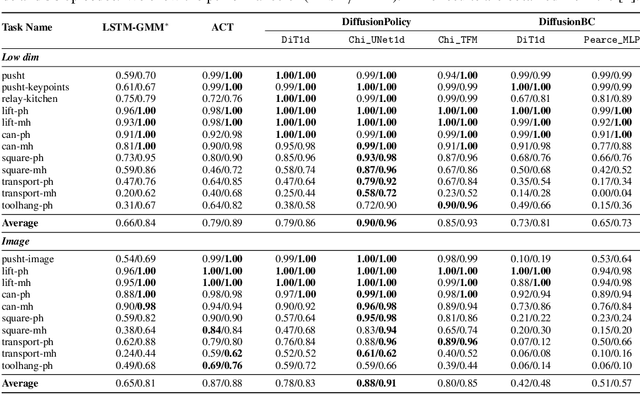
Leveraging the powerful generative capability of diffusion models (DMs) to build decision-making agents has achieved extensive success. However, there is still a demand for an easy-to-use and modularized open-source library that offers customized and efficient development for DM-based decision-making algorithms. In this work, we introduce CleanDiffuser, the first DM library specifically designed for decision-making algorithms. By revisiting the roles of DMs in the decision-making domain, we identify a set of essential sub-modules that constitute the core of CleanDiffuser, allowing for the implementation of various DM algorithms with simple and flexible building blocks. To demonstrate the reliability and flexibility of CleanDiffuser, we conduct comprehensive evaluations of various DM algorithms implemented with CleanDiffuser across an extensive range of tasks. The analytical experiments provide a wealth of valuable design choices and insights, reveal opportunities and challenges, and lay a solid groundwork for future research. CleanDiffuser will provide long-term support to the decision-making community, enhancing reproducibility and fostering the development of more robust solutions. The code and documentation of CleanDiffuser are open-sourced on the https://github.com/CleanDiffuserTeam/CleanDiffuser.
A Method on Searching Better Activation Functions
May 22, 2024



The success of artificial neural networks (ANNs) hinges greatly on the judicious selection of an activation function, introducing non-linearity into network and enabling them to model sophisticated relationships in data. However, the search of activation functions has largely relied on empirical knowledge in the past, lacking theoretical guidance, which has hindered the identification of more effective activation functions. In this work, we offer a proper solution to such issue. Firstly, we theoretically demonstrate the existence of the worst activation function with boundary conditions (WAFBC) from the perspective of information entropy. Furthermore, inspired by the Taylor expansion form of information entropy functional, we propose the Entropy-based Activation Function Optimization (EAFO) methodology. EAFO methodology presents a novel perspective for designing static activation functions in deep neural networks and the potential of dynamically optimizing activation during iterative training. Utilizing EAFO methodology, we derive a novel activation function from ReLU, known as Correction Regularized ReLU (CRReLU). Experiments conducted with vision transformer and its variants on CIFAR-10, CIFAR-100 and ImageNet-1K datasets demonstrate the superiority of CRReLU over existing corrections of ReLU. Extensive empirical studies on task of large language model (LLM) fine-tuning, CRReLU exhibits superior performance compared to GELU, suggesting its broader potential for practical applications.
Uni-RLHF: Universal Platform and Benchmark Suite for Reinforcement Learning with Diverse Human Feedback
Feb 04, 2024Reinforcement Learning with Human Feedback (RLHF) has received significant attention for performing tasks without the need for costly manual reward design by aligning human preferences. It is crucial to consider diverse human feedback types and various learning methods in different environments. However, quantifying progress in RLHF with diverse feedback is challenging due to the lack of standardized annotation platforms and widely used unified benchmarks. To bridge this gap, we introduce Uni-RLHF, a comprehensive system implementation tailored for RLHF. It aims to provide a complete workflow from real human feedback, fostering progress in the development of practical problems. Uni-RLHF contains three packages: 1) a universal multi-feedback annotation platform, 2) large-scale crowdsourced feedback datasets, and 3) modular offline RLHF baseline implementations. Uni-RLHF develops a user-friendly annotation interface tailored to various feedback types, compatible with a wide range of mainstream RL environments. We then establish a systematic pipeline of crowdsourced annotations, resulting in large-scale annotated datasets comprising more than 15 million steps across 30+ popular tasks. Through extensive experiments, the results in the collected datasets demonstrate competitive performance compared to those from well-designed manual rewards. We evaluate various design choices and offer insights into their strengths and potential areas of improvement. We wish to build valuable open-source platforms, datasets, and baselines to facilitate the development of more robust and reliable RLHF solutions based on realistic human feedback. The website is available at https://uni-rlhf.github.io/.
DiffuserLite: Towards Real-time Diffusion Planning
Feb 02, 2024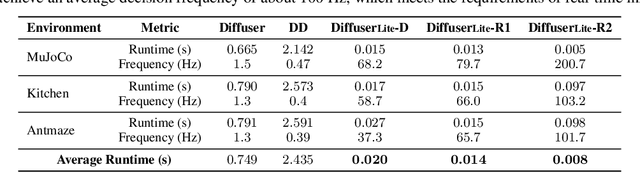
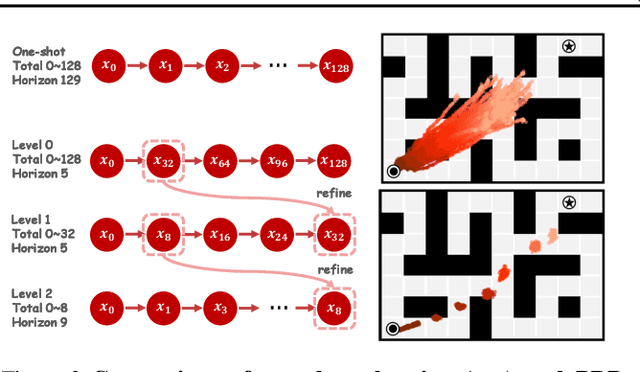
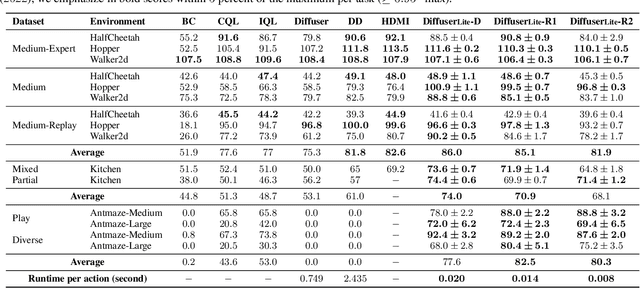
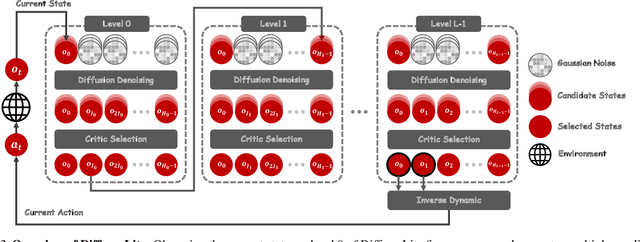
Diffusion planning has been recognized as an effective decision-making paradigm in various domains. The capability of conditionally generating high-quality long-horizon trajectories makes it a promising research direction. However, existing diffusion planning methods suffer from low decision-making frequencies due to the expensive iterative sampling cost. To address this issue, we introduce DiffuserLite, a super fast and lightweight diffusion planning framework. DiffuserLite employs a planning refinement process (PRP) to generate coarse-to-fine-grained trajectories, significantly reducing the modeling of redundant information and leading to notable increases in decision-making frequency. Our experimental results demonstrate that DiffuserLite achieves a decision-making frequency of $122$Hz ($112.7$x faster than previous mainstream frameworks) and reaches state-of-the-art performance on D4RL benchmarks. In addition, our neat DiffuserLite framework can serve as a flexible plugin to enhance decision frequency in other diffusion planning algorithms, providing a structural design reference for future works. More details and visualizations are available at https://diffuserlite.github.io/.
AlignDiff: Aligning Diverse Human Preferences via Behavior-Customisable Diffusion Model
Oct 03, 2023Aligning agent behaviors with diverse human preferences remains a challenging problem in reinforcement learning (RL), owing to the inherent abstractness and mutability of human preferences. To address these issues, we propose AlignDiff, a novel framework that leverages RL from Human Feedback (RLHF) to quantify human preferences, covering abstractness, and utilizes them to guide diffusion planning for zero-shot behavior customizing, covering mutability. AlignDiff can accurately match user-customized behaviors and efficiently switch from one to another. To build the framework, we first establish the multi-perspective human feedback datasets, which contain comparisons for the attributes of diverse behaviors, and then train an attribute strength model to predict quantified relative strengths. After relabeling behavioral datasets with relative strengths, we proceed to train an attribute-conditioned diffusion model, which serves as a planner with the attribute strength model as a director for preference aligning at the inference phase. We evaluate AlignDiff on various locomotion tasks and demonstrate its superior performance on preference matching, switching, and covering compared to other baselines. Its capability of completing unseen downstream tasks under human instructions also showcases the promising potential for human-AI collaboration. More visualization videos are released on https://aligndiff.github.io/.