 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneralizing Alignment Paradigm of Text-to-Image Generation with Preferences through $f$-divergence Minimization
Paper and Code
Sep 15, 2024
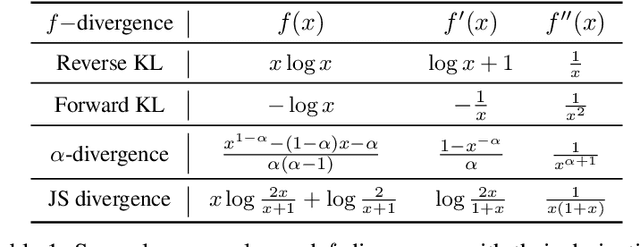
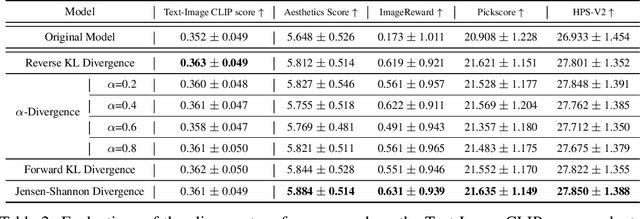
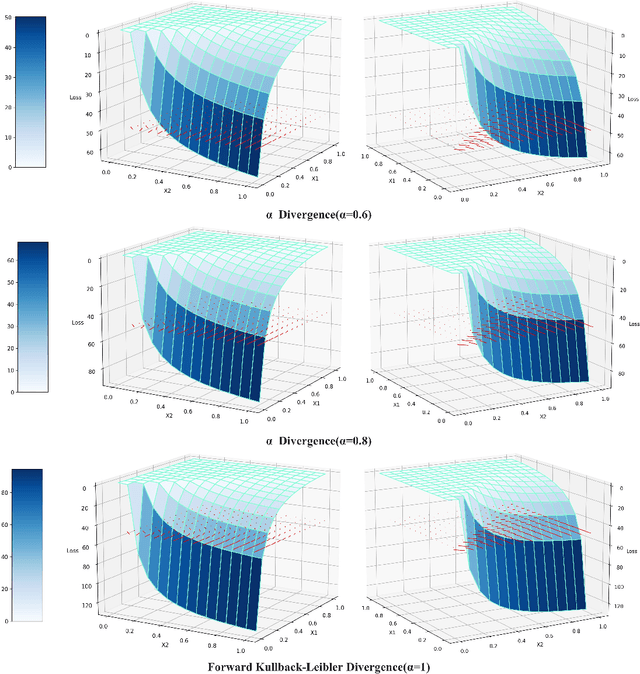
Direct Preference Optimization (DPO) has recently expanded its successful application from aligning large language models (LLMs) to aligning text-to-image models with human preferences, which has generated considerable interest within the community. However, we have observed that these approaches rely solely on minimizing the reverse Kullback-Leibler divergence during alignment process between the fine-tuned model and the reference model, neglecting the incorporation of other divergence constraints. In this study, we focus on extending reverse Kullback-Leibler divergence in the alignment paradigm of text-to-image models to $f$-divergence, which aims to garner better alignment performance as well as good generation diversity. We provide the generalized formula of the alignment paradigm under the $f$-divergence condition and thoroughly analyze the impact of different divergence constraints on alignment process from the perspective of gradient fields. We conduct comprehensive evaluation on image-text alignment performance, human value alignment performance and generation diversity performance under different divergence constraints, and the results indicate that alignment based on Jensen-Shannon divergence achieves the best trade-off among them. The option of divergence employed for aligning text-to-image models significantly impacts the trade-off between alignment performance (especially human value alignment) and generation diversity, which highlights the necessity of selecting an appropriate divergence for practical applications.