 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeepMF: Deep Motion Factorization for Closed-Loop Safety-Critical Driving Scenario Simulation
Dec 23, 2024



Safety-critical traffic scenarios are of great practical relevance to evaluating the robustness of autonomous driving (AD) systems. Given that these long-tail events are extremely rare in real-world traffic data, there is a growing body of work dedicated to the automatic traffic scenario generation. However, nearly all existing algorithms for generating safety-critical scenarios rely on snippets of previously recorded traffic events, transforming normal traffic flow into accident-prone situations directly. In other words, safety-critical traffic scenario generation is hindsight and not applicable to newly encountered and open-ended traffic events.In this paper, we propose the Deep Motion Factorization (DeepMF) framework, which extends static safety-critical driving scenario generation to closed-loop and interactive adversarial traffic simulation. DeepMF casts safety-critical traffic simulation as a Bayesian factorization that includes the assignment of hazardous traffic participants, the motion prediction of selected opponents, the reaction estimation of autonomous vehicle (AV) and the probability estimation of the accident occur. All the aforementioned terms are calculated using decoupled deep neural networks, with inputs limited to the current observation and historical states. Consequently, DeepMF can effectively and efficiently simulate safety-critical traffic scenarios at any triggered time and for any duration by maximizing the compounded posterior probability of traffic risk. Extensive experiments demonstrate that DeepMF excels in terms of risk management, flexibility, and diversity, showcasing outstanding performance in simulating a wide range of realistic, high-risk traffic scenarios.
Chemistry3D: Robotic Interaction Benchmark for Chemistry Experiments
Jun 12, 2024The advent of simulation engines has revolutionized learning and operational efficiency for robots, offering cost-effective and swift pipelines. However, the lack of a universal simulation platform tailored for chemical scenarios impedes progress in robotic manipulation and visualization of reaction processes. Addressing this void, we present Chemistry3D, an innovative toolkit that integrates extensive chemical and robotic knowledge. Chemistry3D not only enables robots to perform chemical experiments but also provides real-time visualization of temperature, color, and pH changes during reactions. Built on the NVIDIA Omniverse platform, Chemistry3D offers interfaces for robot operation, visual inspection, and liquid flow control, facilitating the simulation of special objects such as liquids and transparent entities. Leveraging this toolkit, we have devised RL tasks, object detection, and robot operation scenarios. Additionally, to discern disparities between the rendering engine and the real world, we conducted transparent object detection experiments using Sim2Real, validating the toolkit's exceptional simulation performance. The source code is available at https://github.com/huangyan28/Chemistry3D, and a related tutorial can be found at https://www.omni-chemistry.com.
CAT: Closed-loop Adversarial Training for Safe End-to-End Driving
Oct 19, 2023Driving safety is a top priority for autonomous vehicles. Orthogonal to prior work handling accident-prone traffic events by algorithm designs at the policy level, we investigate a Closed-loop Adversarial Training (CAT) framework for safe end-to-end driving in this paper through the lens of environment augmentation. CAT aims to continuously improve the safety of driving agents by training the agent on safety-critical scenarios that are dynamically generated over time. A novel resampling technique is developed to turn log-replay real-world driving scenarios into safety-critical ones via probabilistic factorization, where the adversarial traffic generation is modeled as the multiplication of standard motion prediction sub-problems. Consequently, CAT can launch more efficient physical attacks compared to existing safety-critical scenario generation methods and yields a significantly less computational cost in the iterative learning pipeline. We incorporate CAT into the MetaDrive simulator and validate our approach on hundreds of driving scenarios imported from real-world driving datasets. Experimental results demonstrate that CAT can effectively generate adversarial scenarios countering the agent being trained. After training, the agent can achieve superior driving safety in both log-replay and safety-critical traffic scenarios on the held-out test set. Code and data are available at https://metadriverse.github.io/cat.
DiffCPS: Diffusion Model based Constrained Policy Search for Offline Reinforcement Learning
Oct 09, 2023Constrained policy search (CPS) is a fundamental problem in offline reinforcement learning, which is generally solved by advantage weighted regression (AWR). However, previous methods may still encounter out-of-distribution actions due to the limited expressivity of Gaussian-based policies. On the other hand, directly applying the state-of-the-art models with distribution expression capabilities (i.e., diffusion models) in the AWR framework is insufficient since AWR requires exact policy probability densities, which is intractable in diffusion models. In this paper, we propose a novel approach called $\textbf{Diffusion Model based Constrained Policy Search (DiffCPS)}$, which tackles the diffusion-based constrained policy search without resorting to AWR. The theoretical analysis reveals our key insights by leveraging the action distribution of the diffusion model to eliminate the policy distribution constraint in the CPS and then utilizing the Evidence Lower Bound (ELBO) of diffusion-based policy to approximate the KL constraint. Consequently, DiffCPS admits the high expressivity of diffusion models while circumventing the cumbersome density calculation brought by AWR. Extensive experimental results based on the D4RL benchmark demonstrate the efficacy of our approach. We empirically show that DiffCPS achieves better or at least competitive performance compared to traditional AWR-based baselines as well as recent diffusion-based offline RL methods. The code is now available at $\href{https://github.com/felix-thu/DiffCPS}{https://github.com/felix-thu/DiffCPS}$.
Are Large Language Models Really Robust to Word-Level Perturbations?
Sep 27, 2023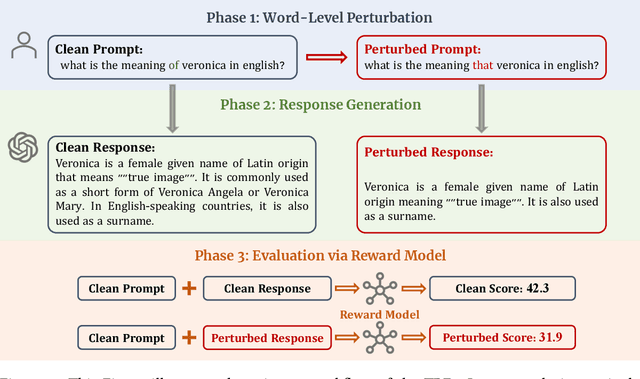


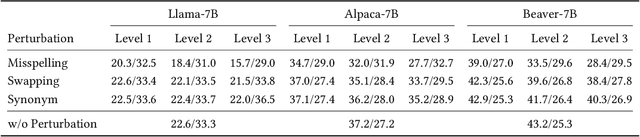
The swift advancement in the scales and capabilities of Large Language Models (LLMs) positions them as promising tools for a variety of downstream tasks. In addition to the pursuit of better performance and the avoidance of violent feedback on a certain prompt, to ensure the responsibility of the LLM, much attention is drawn to the robustness of LLMs. However, existing evaluation methods mostly rely on traditional question answering datasets with predefined supervised labels, which do not align with the superior generation capabilities of contemporary LLMs. To address this issue, we propose a novel rational evaluation approach that leverages pre-trained reward models as diagnostic tools to evaluate the longer conversation generated from more challenging open questions by LLMs, which we refer to as the Reward Model for Reasonable Robustness Evaluation (TREvaL). Longer conversations manifest the comprehensive grasp of language models in terms of their proficiency in understanding questions, a capability not entirely encompassed by individual words or letters, which may exhibit oversimplification and inherent biases. Our extensive empirical experiments demonstrate that TREvaL provides an innovative method for evaluating the robustness of an LLM. Furthermore, our results demonstrate that LLMs frequently exhibit vulnerability to word-level perturbations that are commonplace in daily language usage. Notably, we are surprised to discover that robustness tends to decrease as fine-tuning (SFT and RLHF) is conducted. The code of TREval is available in https://github.com/Harry-mic/TREvaL.
Learning Better with Less: Effective Augmentation for Sample-Efficient Visual Reinforcement Learning
May 25, 2023



Data augmentation (DA) is a crucial technique for enhancing the sample efficiency of visual reinforcement learning (RL) algorithms. Notably, employing simple observation transformations alone can yield outstanding performance without extra auxiliary representation tasks or pre-trained encoders. However, it remains unclear which attributes of DA account for its effectiveness in achieving sample-efficient visual RL. To investigate this issue and further explore the potential of DA, this work conducts comprehensive experiments to assess the impact of DA's attributes on its efficacy and provides the following insights and improvements: (1) For individual DA operations, we reveal that both ample spatial diversity and slight hardness are indispensable. Building on this finding, we introduce Random PadResize (Rand PR), a new DA operation that offers abundant spatial diversity with minimal hardness. (2) For multi-type DA fusion schemes, the increased DA hardness and unstable data distribution result in the current fusion schemes being unable to achieve higher sample efficiency than their corresponding individual operations. Taking the non-stationary nature of RL into account, we propose a RL-tailored multi-type DA fusion scheme called Cycling Augmentation (CycAug), which performs periodic cycles of different DA operations to increase type diversity while maintaining data distribution consistency. Extensive evaluations on the DeepMind Control suite and CARLA driving simulator demonstrate that our methods achieve superior sample efficiency compared with the prior state-of-the-art methods.
SaFormer: A Conditional Sequence Modeling Approach to Offline Safe Reinforcement Learning
Jan 28, 2023



Offline safe RL is of great practical relevance for deploying agents in real-world applications. However, acquiring constraint-satisfying policies from the fixed dataset is non-trivial for conventional approaches. Even worse, the learned constraints are stationary and may become invalid when the online safety requirement changes. In this paper, we present a novel offline safe RL approach referred to as SaFormer, which tackles the above issues via conditional sequence modeling. In contrast to existing sequence models, we propose cost-related tokens to restrict the action space and a posterior safety verification to enforce the constraint explicitly. Specifically, SaFormer performs a two-stage auto-regression conditioned by the maximum remaining cost to generate feasible candidates. It then filters out unsafe attempts and executes the optimal action with the highest expected return. Extensive experiments demonstrate the efficacy of SaFormer featuring (1) competitive returns with tightened constraint satisfaction; (2) adaptability to the in-range cost values of the offline data without retraining; (3) generalizability for constraints beyond the current dataset.
Safety Correction from Baseline: Towards the Risk-aware Policy in Robotics via Dual-agent Reinforcement Learning
Dec 14, 2022



Learning a risk-aware policy is essential but rather challenging in unstructured robotic tasks. Safe reinforcement learning methods open up new possibilities to tackle this problem. However, the conservative policy updates make it intractable to achieve sufficient exploration and desirable performance in complex, sample-expensive environments. In this paper, we propose a dual-agent safe reinforcement learning strategy consisting of a baseline and a safe agent. Such a decoupled framework enables high flexibility, data efficiency and risk-awareness for RL-based control. Concretely, the baseline agent is responsible for maximizing rewards under standard RL settings. Thus, it is compatible with off-the-shelf training techniques of unconstrained optimization, exploration and exploitation. On the other hand, the safe agent mimics the baseline agent for policy improvement and learns to fulfill safety constraints via off-policy RL tuning. In contrast to training from scratch, safe policy correction requires significantly fewer interactions to obtain a near-optimal policy. The dual policies can be optimized synchronously via a shared replay buffer, or leveraging the pre-trained model or the non-learning-based controller as a fixed baseline agent. Experimental results show that our approach can learn feasible skills without prior knowledge as well as deriving risk-averse counterparts from pre-trained unsafe policies. The proposed method outperforms the state-of-the-art safe RL algorithms on difficult robot locomotion and manipulation tasks with respect to both safety constraint satisfaction and sample efficiency.
Evaluating Model-free Reinforcement Learning toward Safety-critical Tasks
Dec 12, 2022Safety comes first in many real-world applications involving autonomous agents. Despite a large number of reinforcement learning (RL) methods focusing on safety-critical tasks, there is still a lack of high-quality evaluation of those algorithms that adheres to safety constraints at each decision step under complex and unknown dynamics. In this paper, we revisit prior work in this scope from the perspective of state-wise safe RL and categorize them as projection-based, recovery-based, and optimization-based approaches, respectively. Furthermore, we propose Unrolling Safety Layer (USL), a joint method that combines safety optimization and safety projection. This novel technique explicitly enforces hard constraints via the deep unrolling architecture and enjoys structural advantages in navigating the trade-off between reward improvement and constraint satisfaction. To facilitate further research in this area, we reproduce related algorithms in a unified pipeline and incorporate them into SafeRL-Kit, a toolkit that provides off-the-shelf interfaces and evaluation utilities for safety-critical tasks. We then perform a comparative study of the involved algorithms on six benchmarks ranging from robotic control to autonomous driving. The empirical results provide an insight into their applicability and robustness in learning zero-cost-return policies without task-dependent handcrafting. The project page is available at https://sites.google.com/view/saferlkit.
Constrained Update Projection Approach to Safe Policy Optimization
Sep 15, 2022

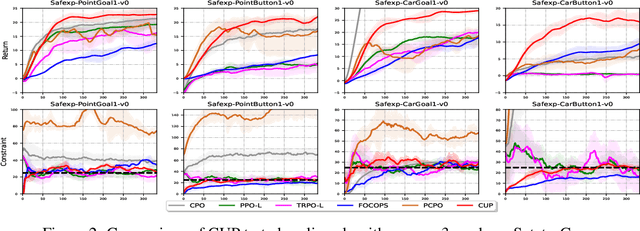
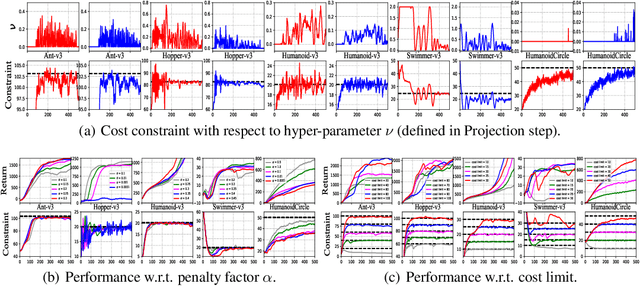
Safe reinforcement learning (RL) studies problems where an intelligent agent has to not only maximize reward but also avoid exploring unsafe areas. In this study, we propose CUP, a novel policy optimization method based on Constrained Update Projection framework that enjoys rigorous safety guarantee. Central to our CUP development is the newly proposed surrogate functions along with the performance bound. Compared to previous safe RL methods, CUP enjoys the benefits of 1) CUP generalizes the surrogate functions to generalized advantage estimator (GAE), leading to strong empirical performance. 2) CUP unifies performance bounds, providing a better understanding and interpretability for some existing algorithms; 3) CUP provides a non-convex implementation via only first-order optimizers, which does not require any strong approximation on the convexity of the objectives. To validate our CUP method, we compared CUP against a comprehensive list of safe RL baselines on a wide range of tasks. Experiments show the effectiveness of CUP both in terms of reward and safety constraint satisfaction. We have opened the source code of CUP at https://github.com/RL-boxes/Safe-RL/tree/ main/CUP.