 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUltrasound-CLIP: Semantic-Aware Contrastive Pre-training for Ultrasound Image-Text Understanding
Apr 02, 2026Ultrasound imaging is widely used in clinical diagnostics due to its real-time capability and radiation-free nature. However, existing vision-language pre-training models, such as CLIP, are primarily designed for other modalities, and are difficult to directly apply to ultrasound data, which exhibit heterogeneous anatomical structures and diverse diagnostic attributes. To bridge this gap, we construct US-365K, a large-scale ultrasound image-text dataset containing 365k paired samples across 52 anatomical categories. We establish Ultrasonographic Diagnostic Taxonomy (UDT) containing two hierarchical knowledge frameworks. Ultrasonographic Hierarchical Anatomical Taxonomy standardizes anatomical organization, and Ultrasonographic Diagnostic Attribute Framework formalizes nine diagnostic dimensions, including body system, organ, diagnosis, shape, margins, echogenicity, internal characteristics, posterior acoustic phenomena, and vascularity. Building upon these foundations, we propose Ultrasound-CLIP, a semantic-aware contrastive learning framework that introduces semantic soft labels and semantic loss to refine sample discrimination. Moreover, we construct a heterogeneous graph modality derived from UDAF's textual representations, enabling structured reasoning over lesion-attribute relations. Extensive experiments with patient-level data splitting demonstrate that our approach achieves state-of-the-art performance on classification and retrieval benchmarks, while also delivering strong generalization to zero-shot, linear probing, and fine-tuning tasks.
Policy Representation via Diffusion Probability Model for Reinforcement Learning
May 22, 2023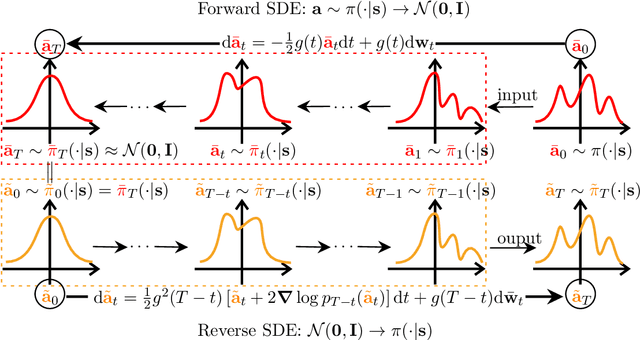

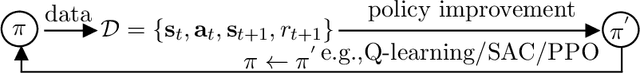
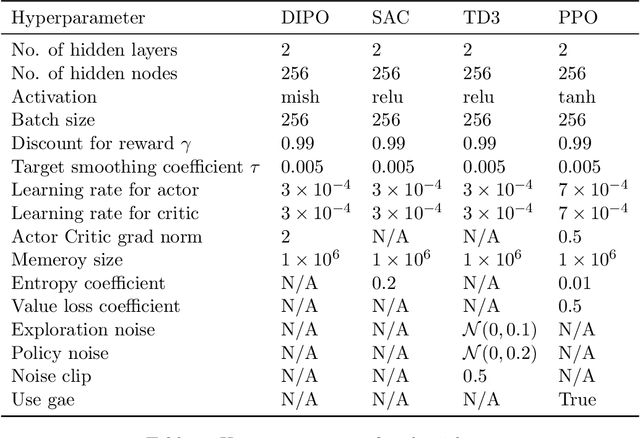
Popular reinforcement learning (RL) algorithms tend to produce a unimodal policy distribution, which weakens the expressiveness of complicated policy and decays the ability of exploration. The diffusion probability model is powerful to learn complicated multimodal distributions, which has shown promising and potential applications to RL. In this paper, we formally build a theoretical foundation of policy representation via the diffusion probability model and provide practical implementations of diffusion policy for online model-free RL. Concretely, we character diffusion policy as a stochastic process, which is a new approach to representing a policy. Then we present a convergence guarantee for diffusion policy, which provides a theory to understand the multimodality of diffusion policy. Furthermore, we propose the DIPO which is an implementation for model-free online RL with DIffusion POlicy. To the best of our knowledge, DIPO is the first algorithm to solve model-free online RL problems with the diffusion model. Finally, extensive empirical results show the effectiveness and superiority of DIPO on the standard continuous control Mujoco benchmark.
Constrained Update Projection Approach to Safe Policy Optimization
Sep 15, 2022

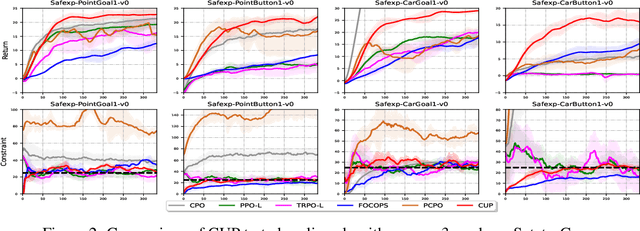
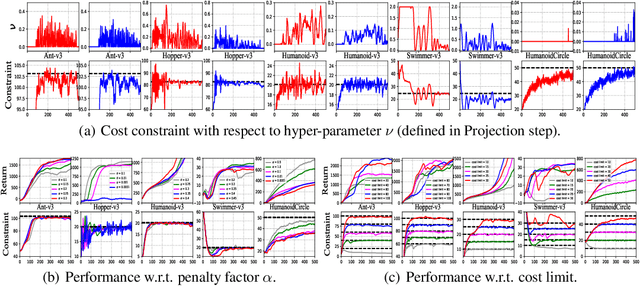
Safe reinforcement learning (RL) studies problems where an intelligent agent has to not only maximize reward but also avoid exploring unsafe areas. In this study, we propose CUP, a novel policy optimization method based on Constrained Update Projection framework that enjoys rigorous safety guarantee. Central to our CUP development is the newly proposed surrogate functions along with the performance bound. Compared to previous safe RL methods, CUP enjoys the benefits of 1) CUP generalizes the surrogate functions to generalized advantage estimator (GAE), leading to strong empirical performance. 2) CUP unifies performance bounds, providing a better understanding and interpretability for some existing algorithms; 3) CUP provides a non-convex implementation via only first-order optimizers, which does not require any strong approximation on the convexity of the objectives. To validate our CUP method, we compared CUP against a comprehensive list of safe RL baselines on a wide range of tasks. Experiments show the effectiveness of CUP both in terms of reward and safety constraint satisfaction. We have opened the source code of CUP at https://github.com/RL-boxes/Safe-RL/tree/ main/CUP.