 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUltra Flash: Scaling Real-Time Streaming Video Generation to High Resolutions
Jun 08, 2026While recent autoregressive video diffusion models achieve remarkable streaming quality, they remain confined to low resolutions (e.g., 480P), leaving efficient, scalable, real-time high-resolution video generation a fundamental open challenge. To bridge this gap, we present Ultra Flash, a cascaded streaming framework capable of real-time high-resolution video generation. Ultra Flash achieves ~30 FPS at 1K resolution and ~18 FPS at 2K resolution on a single GPU through three key contributions: (1) an architecture-preserving T2V-to-TV2V super-resolution training paradigm coupled with an AIGC-oriented data degradation pipeline that effectively preserves the generative capability of the base model, enabling enhanced high-resolution detail when cascaded after mainstream low-resolution generative models; (2) a causal streaming latent upsampler paired with a high-resolution decoder, which enhances spatiotemporal coherence while enabling efficient latent spatial scaling and precise high-resolution decoding with negligible computational overhead; and (3) a cascade high-resolution streaming video generation optimization scheme that first performs hybrid-reward-enhanced sparse causalization and single-step distillation of the super-resolution model, then introduces cascaded streaming self-forcing preference optimization with dynamic cache management, jointly enhancing overall coherence, improving quality, and enabling real-time high-resolution streaming video generation. Extensive experiments demonstrate that Ultra Flash reliably produces ultra-high-resolution streaming video while maintaining state-of-the-art visual quality and superior efficiency.
Channel-Level Relation to Attentive Aggregation with Neighborhood-Homogeneity Constraint for Point Cloud Analysis
May 04, 2026In 3D point cloud understanding, the core challenge lies in accurately capturing discriminative features within complex neighborhoods, which directly affects the execution precision of downstream tasks such as embodied AI and autonomous driving. Existing methods explore feature correlation discrimination but are limited to point-level spatial distribution or channel responses, enabling only coarse-grained level evaluation. For modern multi-scale point cloud networks, such coarse-grained metrics inevitably incur significant information loss in deeper layers. To address this issue, we propose a novel network equipped with a channel-level metric-based enhancement mechanism, termed the PointCRA network. Our core idea is to introduce temporal trend variation as a new evaluation dimension to avoid the information loss caused by weight dimension collapse in existing spatial and channel attention mechanisms. On this basis, we construct a multi-level calibration framework guided by neighborhood homogeneity for weight calibration, and design a dedicated loss function to enhance channel discriminability. The module effectively leverages the intrinsic feature priors of deep networks to adaptively correct the feature aggregation process, offering strong interpretability with low parameter overhead. Furthermore, our proposed method exhibits strong transferability, interpretability, and parameter efficiency. We validate the proposed method effectiveness on diverse datasets and benchmark models, and further demonstrate its rationality through extensive analytical experiments. Our PointCRA achieves 77.5% mIoU on the S3DIS dataset, 90.4% OA on the ScanObjectNN dataset, and 87.4% instance mIoU on the ShapeNetPart dataset. The code and pretrained weights are publicly available on GitHub:
CARE: Multi-Task Pretraining for Latent Continuous Action Representation in Robot Control
Jan 30, 2026Recent advances in Vision-Language-Action (VLA) models have shown promise for robot control, but their dependence on action supervision limits scalability and generalization. To address this challenge, we introduce CARE, a novel framework designed to train VLA models for robotic task execution. Unlike existing methods that depend on action annotations during pretraining, CARE eliminates the need for explicit action labels by leveraging only video-text pairs. These weakly aligned data sources enable the model to learn continuous latent action representations through a newly designed multi-task pretraining objective. During fine-tuning, a small set of labeled data is used to train the action head for control. Experimental results across various simulation tasks demonstrate CARE's superior success rate, semantic interpretability, and ability to avoid shortcut learning. These results underscore CARE's scalability, interpretability, and effectiveness in robotic control with weak supervision.
Enhancing point cloud analysis via neighbor aggregation correction based on cross-stage structure correlation
Jun 18, 2025Point cloud analysis is the cornerstone of many downstream tasks, among which aggregating local structures is the basis for understanding point cloud data. While numerous works aggregate neighbor using three-dimensional relative coordinates, there are irrelevant point interference and feature hierarchy gap problems due to the limitation of local coordinates. Although some works address this limitation by refining spatial description though explicit modeling of cross-stage structure, these enhancement methods based on direct geometric structure encoding have problems of high computational overhead and noise sensitivity. To overcome these problems, we propose the Point Distribution Set Abstraction module (PDSA) that utilizes the correlation in the high-dimensional space to correct the feature distribution during aggregation, which improves the computational efficiency and robustness. PDSA distinguishes the point correlation based on a lightweight cross-stage structural descriptor, and enhances structural homogeneity by reducing the variance of the neighbor feature matrix and increasing classes separability though long-distance modeling. Additionally, we introducing a key point mechanism to optimize the computational overhead. The experimental result on semantic segmentation and classification tasks based on different baselines verify the generalization of the method we proposed, and achieve significant performance improvement with less parameter cost. The corresponding ablation and visualization results demonstrate the effectiveness and rationality of our method. The code and training weight is available at: https://github.com/AGENT9717/PointDistribution
Vision-Based Deep Reinforcement Learning of UAV Autonomous Navigation Using Privileged Information
Dec 09, 2024The capability of UAVs for efficient autonomous navigation and obstacle avoidance in complex and unknown environments is critical for applications in agricultural irrigation, disaster relief and logistics. In this paper, we propose the DPRL (Distributed Privileged Reinforcement Learning) navigation algorithm, an end-to-end policy designed to address the challenge of high-speed autonomous UAV navigation under partially observable environmental conditions. Our approach combines deep reinforcement learning with privileged learning to overcome the impact of observation data corruption caused by partial observability. We leverage an asymmetric Actor-Critic architecture to provide the agent with privileged information during training, which enhances the model's perceptual capabilities. Additionally, we present a multi-agent exploration strategy across diverse environments to accelerate experience collection, which in turn expedites model convergence. We conducted extensive simulations across various scenarios, benchmarking our DPRL algorithm against the state-of-the-art navigation algorithms. The results consistently demonstrate the superior performance of our algorithm in terms of flight efficiency, robustness and overall success rate.
Multi-View Collaborative Network Embedding
May 17, 2020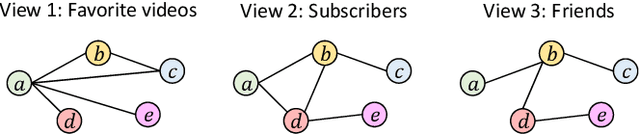

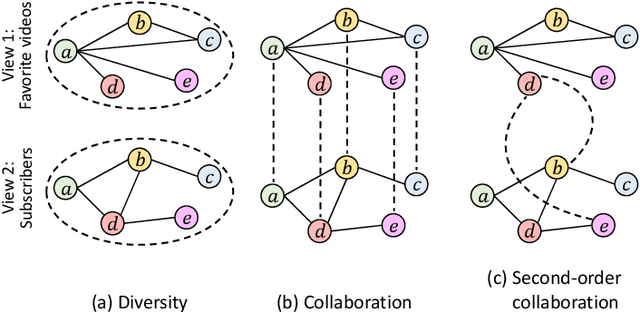
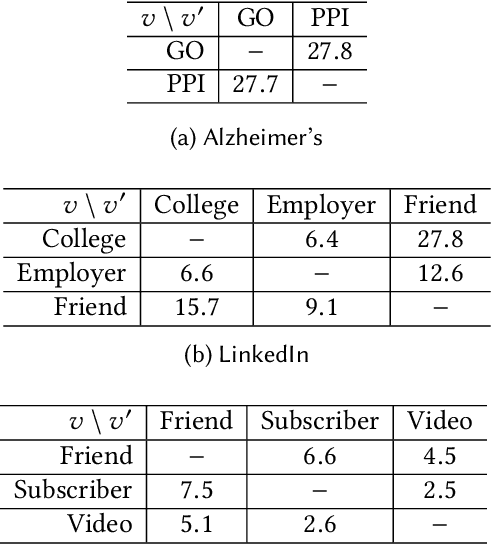
Real-world networks often exist with multiple views, where each view describes one type of interaction among a common set of nodes. For example, on a video-sharing network, while two user nodes are linked if they have common favorite videos in one view, they can also be linked in another view if they share common subscribers. Unlike traditional single-view networks, multiple views maintain different semantics to complement each other. In this paper, we propose MANE, a multi-view network embedding approach to learn low-dimensional representations. Similar to existing studies, MANE hinges on diversity and collaboration - while diversity enables views to maintain their individual semantics, collaboration enables views to work together. However, we also discover a novel form of second-order collaboration that has not been explored previously, and further unify it into our framework to attain superior node representations. Furthermore, as each view often has varying importance w.r.t. different nodes, we propose MANE+, an attention-based extension of MANE to model node-wise view importance. Finally, we conduct comprehensive experiments on three public, real-world multi-view networks, and the results demonstrate that our models consistently outperform state-of-the-art approaches.