 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDebtFree: Minimizing Labeling Cost in Self-Admitted Technical Debt Identification using Semi-Supervised Learning
Paper and Code
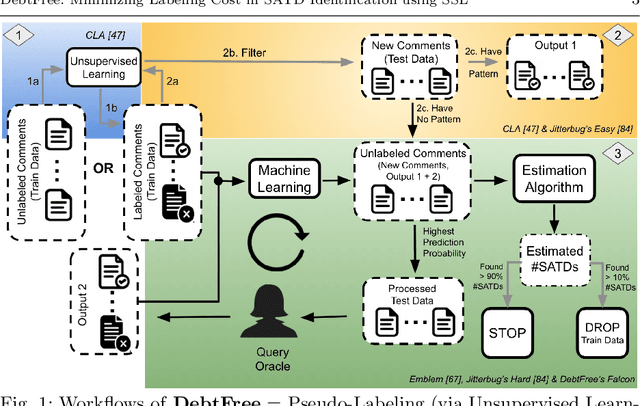

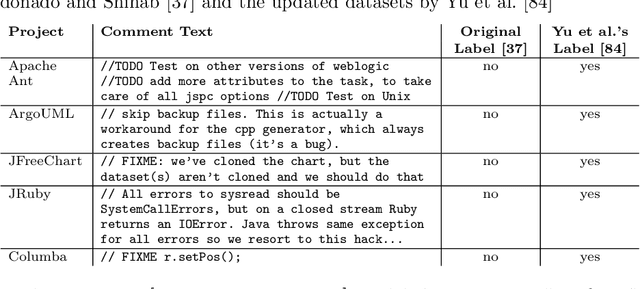
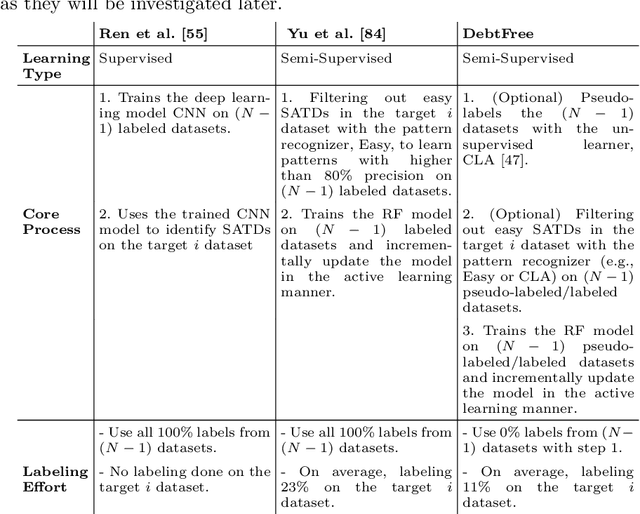
Keeping track of and managing Self-Admitted Technical Debts (SATDs) is important for maintaining a healthy software project. Current active-learning SATD recognition tool involves manual inspection of 24% of the test comments on average to reach 90% of the recall. Among all the test comments, about 5% are SATDs. The human experts are then required to read almost a quintuple of the SATD comments which indicates the inefficiency of the tool. Plus, human experts are still prone to error: 95% of the false-positive labels from previous work were actually true positives. To solve the above problems, we propose DebtFree, a two-mode framework based on unsupervised learning for identifying SATDs. In mode1, when the existing training data is unlabeled, DebtFree starts with an unsupervised learner to automatically pseudo-label the programming comments in the training data. In contrast, in mode2 where labels are available with the corresponding training data, DebtFree starts with a pre-processor that identifies the highly prone SATDs from the test dataset. Then, our machine learning model is employed to assist human experts in manually identifying the remaining SATDs. Our experiments on 10 software projects show that both models yield a statistically significant improvement in effectiveness over the state-of-the-art automated and semi-automated models. Specifically, DebtFree can reduce the labeling effort by 99% in mode1 (unlabeled training data), and up to 63% in mode2 (labeled training data) while improving the current active learner's F1 relatively to almost 100%.