 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Less is More: On the Value of "Co-training" for Semi-Supervised Software Defect Predictors
Nov 10, 2022Labeling a module defective or non-defective is an expensive task. Hence, there are often limits on how much-labeled data is available for training. Semi-supervised classifiers use far fewer labels for training models, but there are numerous semi-supervised methods, including self-labeling, co-training, maximal-margin, and graph-based methods, to name a few. Only a handful of these methods have been tested in SE for (e.g.) predicting defects and even that, those tests have been on just a handful of projects. This paper takes a wide range of 55 semi-supervised learners and applies these to over 714 projects. We find that semi-supervised "co-training methods" work significantly better than other approaches. However, co-training needs to be used with caution since the specific choice of co-training methods needs to be carefully selected based on a user's specific goals. Also, we warn that a commonly-used co-training method ("multi-view"-- where different learners get different sets of columns) does not improve predictions (while adding too much to the run time costs 11 hours vs. 1.8 hours). Those cautions stated, we find using these "co-trainers," we can label just 2.5% of data, then make predictions that are competitive to those using 100% of the data. It is an open question worthy of future work to test if these reductions can be seen in other areas of software analytics. All the codes used and datasets analyzed during the current study are available in the https://GitHub.com/Suvodeep90/Semi_Supervised_Methods.
Can We Achieve Fairness Using Semi-Supervised Learning?
Nov 25, 2021
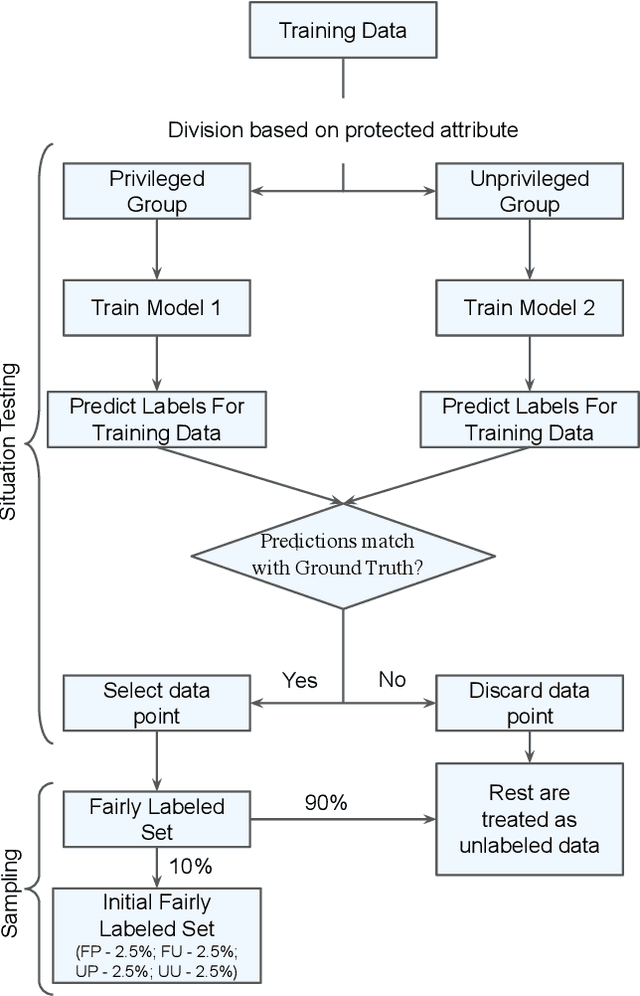

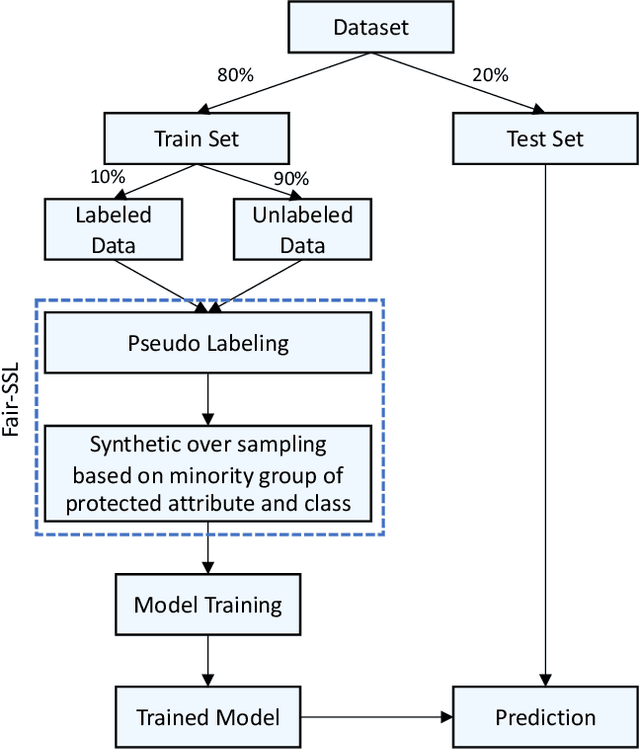
Ethical bias in machine learning models has become a matter of concern in the software engineering community. Most of the prior software engineering works concentrated on finding ethical bias in models rather than fixing it. After finding bias, the next step is mitigation. Prior researchers mainly tried to use supervised approaches to achieve fairness. However, in the real world, getting data with trustworthy ground truth is challenging and also ground truth can contain human bias. Semi-supervised learning is a machine learning technique where, incrementally, labeled data is used to generate pseudo-labels for the rest of the data (and then all that data is used for model training). In this work, we apply four popular semi-supervised techniques as pseudo-labelers to create fair classification models. Our framework, Fair-SSL, takes a very small amount (10%) of labeled data as input and generates pseudo-labels for the unlabeled data. We then synthetically generate new data points to balance the training data based on class and protected attribute as proposed by Chakraborty et al. in FSE 2021. Finally, the classification model is trained on the balanced pseudo-labeled data and validated on test data. After experimenting on ten datasets and three learners, we find that Fair-SSL achieves similar performance as three state-of-the-art bias mitigation algorithms. That said, the clear advantage of Fair-SSL is that it requires only 10% of the labeled training data. To the best of our knowledge, this is the first SE work where semi-supervised techniques are used to fight against ethical bias in SE ML models.
Fair Enough: Searching for Sufficient Measures of Fairness
Oct 25, 2021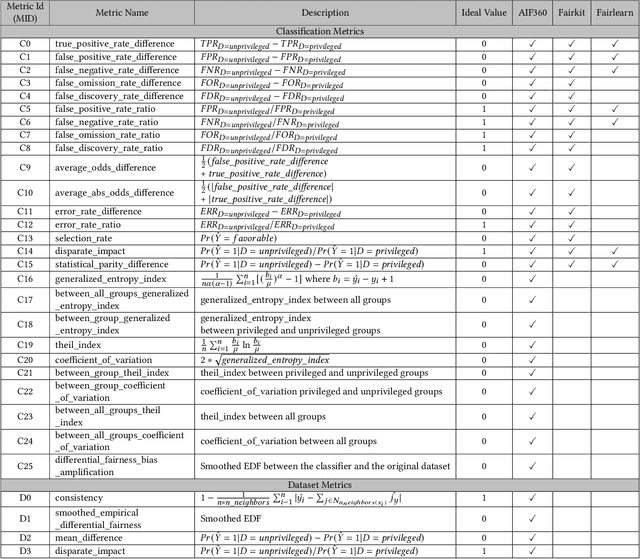
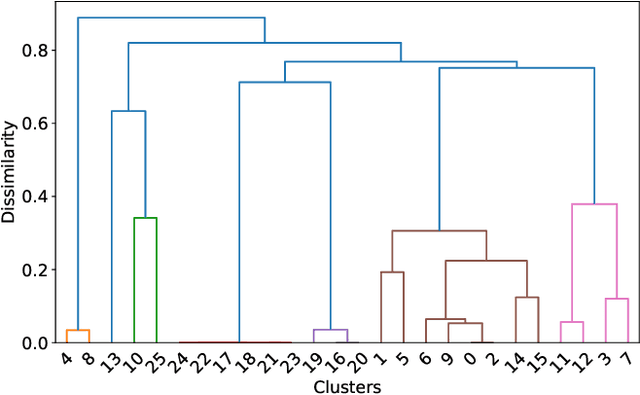
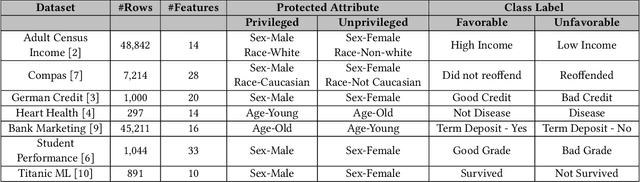
Testing machine learning software for ethical bias has become a pressing current concern. In response, recent research has proposed a plethora of new fairness metrics, for example, the dozens of fairness metrics in the IBM AIF360 toolkit. This raises the question: How can any fairness tool satisfy such a diverse range of goals? While we cannot completely simplify the task of fairness testing, we can certainly reduce the problem. This paper shows that many of those fairness metrics effectively measure the same thing. Based on experiments using seven real-world datasets, we find that (a) 26 classification metrics can be clustered into seven groups, and (b) four dataset metrics can be clustered into three groups. Further, each reduced set may actually predict different things. Hence, it is no longer necessary (or even possible) to satisfy all fairness metrics. In summary, to simplify the fairness testing problem, we recommend the following steps: (1) determine what type of fairness is desirable (and we offer a handful of such types); then (2) lookup those types in our clusters; then (3) just test for one item per cluster. To support that processing, all our scripts (and example datasets) are available at https://github.com/Repoanonymous/Fairness\_Metrics.
Bias in Machine Learning Software: Why? How? What to do?
May 31, 2021Increasingly, software is making autonomous decisions in case of criminal sentencing, approving credit cards, hiring employees, and so on. Some of these decisions show bias and adversely affect certain social groups (e.g. those defined by sex, race, age, marital status). Many prior works on bias mitigation take the following form: change the data or learners in multiple ways, then see if any of that improves fairness. Perhaps a better approach is to postulate root causes of bias and then applying some resolution strategy. This paper postulates that the root causes of bias are the prior decisions that affect- (a) what data was selected and (b) the labels assigned to those examples. Our Fair-SMOTE algorithm removes biased labels; and rebalances internal distributions such that based on sensitive attribute, examples are equal in both positive and negative classes. On testing, it was seen that this method was just as effective at reducing bias as prior approaches. Further, models generated via Fair-SMOTE achieve higher performance (measured in terms of recall and F1) than other state-of-the-art fairness improvement algorithms. To the best of our knowledge, measured in terms of number of analyzed learners and datasets, this study is one of the largest studies on bias mitigation yet presented in the literature.
Early Life Cycle Software Defect Prediction. Why? How?
Nov 26, 2020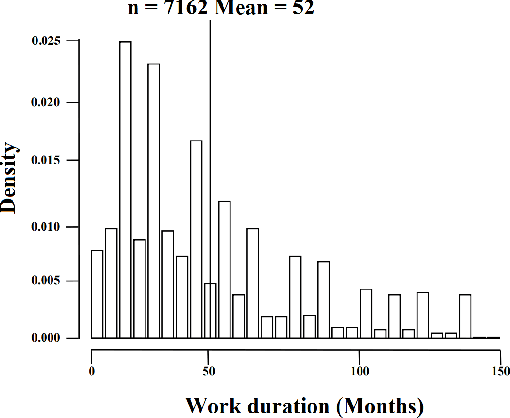
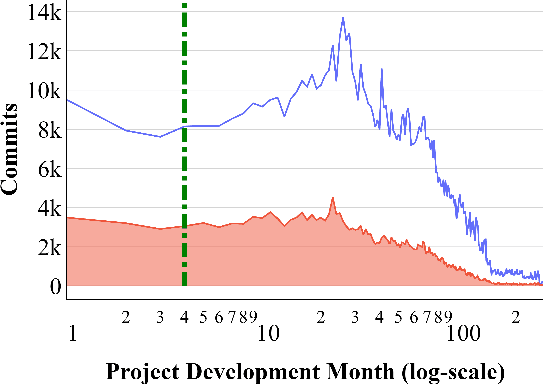
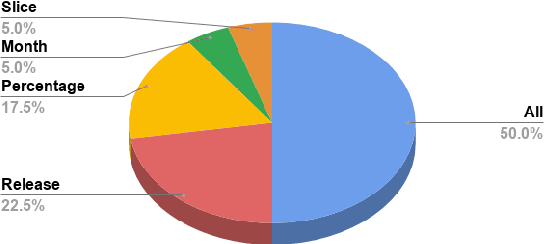
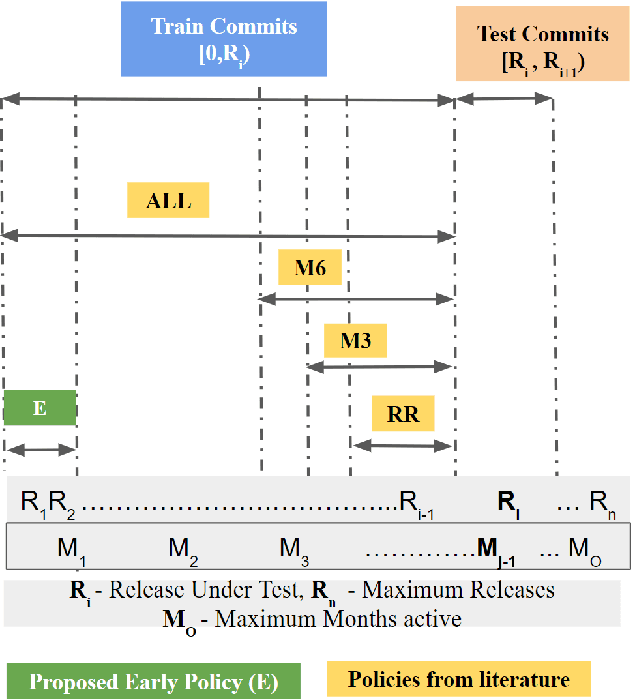
Many methods in defect prediction are "datahungry"; i.e. (1) given a choice of using more data, or some smaller sample, researchers assume that more is better; (2) when data is missing, researchers take elaborate steps to transfer data from another project; and (3) given a choice of older data or some more recent sample, researchers usually ignore older data. Based on the analysis of hundreds of popular Github projects (with 1.2 million commits), we suggest that for defect prediction, there is limited value in such data-hungry approaches. Data for our sample of projects last for 84 months and contains 3,728 commits (median values). Across these projects, most of the defects occur very early in their life cycle. Hence, defect predictors learned from the first 150 commits and four months perform just as well as anything else. This means that, contrary to the "data-hungry" approach, (1) small samples of data from these projects are all that is needed for defect prediction; (2) transfer learning has limited value since it is needed only for the first 4 of 84 months (i.e. just 4% of the life cycle); (3) after the first few months, we need not continually update our defect prediction models. We hope these results inspire other researchers to adopt a "simplicity-first" approach to their work. Certainly, there are domains that require a complex and data-hungry analysis. But before assuming complexity, it is prudent to check the raw data looking for "short cuts" that simplify the whole analysis.
Revisiting Process versus Product Metrics: a Large Scale Analysis
Aug 21, 2020


Numerous automated SE methods can build predictive models from software project data. But what methods and conclusions should we endorse as we move from analytics in-the small (dealing with a handful of projects) to analytics in-the-large (dealing with hundreds of projects)? To answer this question, we recheck prior small-scale results (about process versus product metrics for defect prediction) using 722,471 commits from 770 Github projects. We find that some analytics in-the-small conclusions still hold when scaling up to analytics in-the large. For example, like prior work, we see that process metrics are better predictors for defects than product metrics (best process/product-based learners respectively achieve recalls of 98%/44% and AUCs of 95%/54%, median values). However, we warn that it is unwise to trust metric importance results from analytics in-the-small studies since those change, dramatically when moving to analytics in-the-large. Also, when reasoning in-the-large about hundreds of projects, it is better to use predictions from multiple models (since single model predictions can become very confused and exhibit very high variance). Apart from the above specific conclusions, our more general point is that the SE community now needs to revisit many of the conclusions previously obtained via analytics in-the-small.
Learning GENERAL Principles from Hundreds of Software Projects
Nov 06, 2019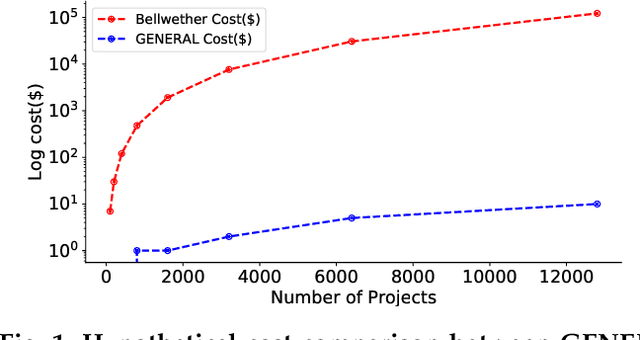
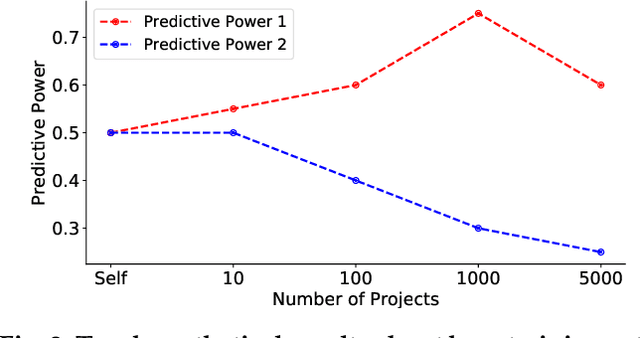

When one exemplar project, which we call the "bellwether", offers the best advice then it can be used to offer advice for many other projects. Such bellwethers can be used to make quality predictions about new projects, even before there is much experience with those new projects. But existing methods for bellwether transfer are very slow. When applied to the 697 projects studied here, they took 60 days of CPU to find and certify the bellwethers. Hence, we propose a GENERAL: a novel bellwether detection algorithm based on hierarchical clustering. At each level within a tree of clusters, one bellwether is computed from sibling projects, then promoted up the tree. This hierarchical method is a scalable approach to learning effective models from very large data sets. For example, for nearly 700 projects, the defect prediction models generated from GENERAL's bellwether were just as good as those found via standard methods.
500+ Times Faster Than Deep Learning (A Case Study Exploring Faster Methods for Text Mining StackOverflow)
Feb 14, 2018


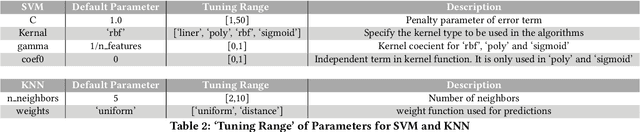
Deep learning methods are useful for high-dimensional data and are becoming widely used in many areas of software engineering. Deep learners utilizes extensive computational power and can take a long time to train-- making it difficult to widely validate and repeat and improve their results. Further, they are not the best solution in all domains. For example, recent results show that for finding related Stack Overflow posts, a tuned SVM performs similarly to a deep learner, but is significantly faster to train. This paper extends that recent result by clustering the dataset, then tuning very learners within each cluster. This approach is over 500 times faster than deep learning (and over 900 times faster if we use all the cores on a standard laptop computer). Significantly, this faster approach generates classifiers nearly as good (within 2\% F1 Score) as the much slower deep learning method. Hence we recommend this faster methods since it is much easier to reproduce and utilizes far fewer CPU resources. More generally, we recommend that before researchers release research results, that they compare their supposedly sophisticated methods against simpler alternatives (e.g applying simpler learners to build local models).