 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAugmentedCode: Examining the Effects of Natural Language Resources in Code Retrieval Models
Oct 16, 2021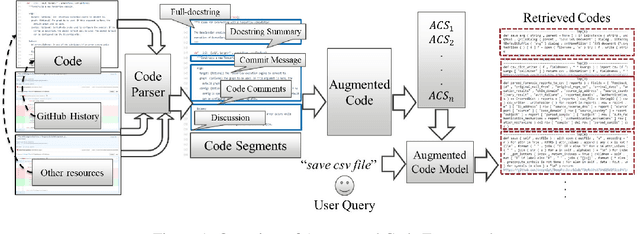

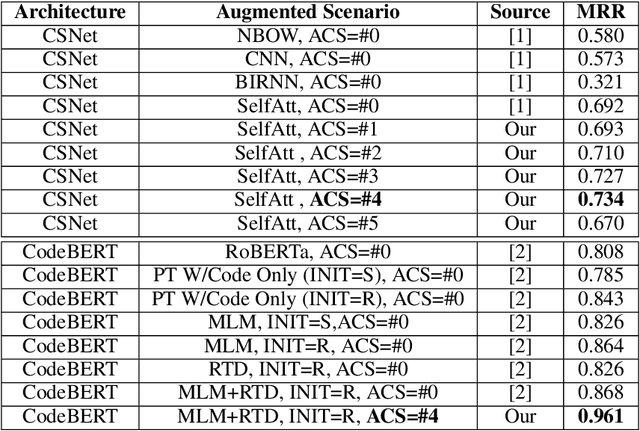
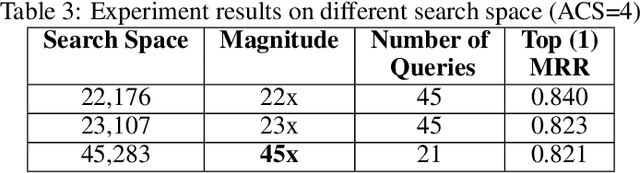
Code retrieval is allowing software engineers to search codes through a natural language query, which relies on both natural language processing and software engineering techniques. There have been several attempts on code retrieval from searching snippet codes to function codes. In this paper, we introduce Augmented Code (AugmentedCode) retrieval which takes advantage of existing information within the code and constructs augmented programming language to improve the code retrieval models' performance. We curated a large corpus of Python and showcased the the framework and the results of augmented programming language which outperforms on CodeSearchNet and CodeBERT with a Mean Reciprocal Rank (MRR) of 0.73 and 0.96, respectively. The outperformed fine-tuned augmented code retrieval model is published in HuggingFace at https://huggingface.co/Fujitsu/AugCode and a demonstration video is available at: https://youtu.be/mnZrUTANjGs .
The Early Bird Catches the Worm: Better Early Life Cycle Defect Predictors
May 24, 2021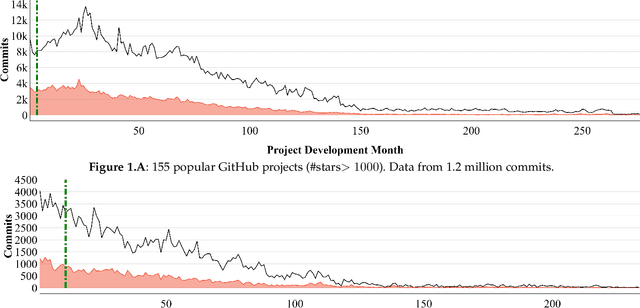
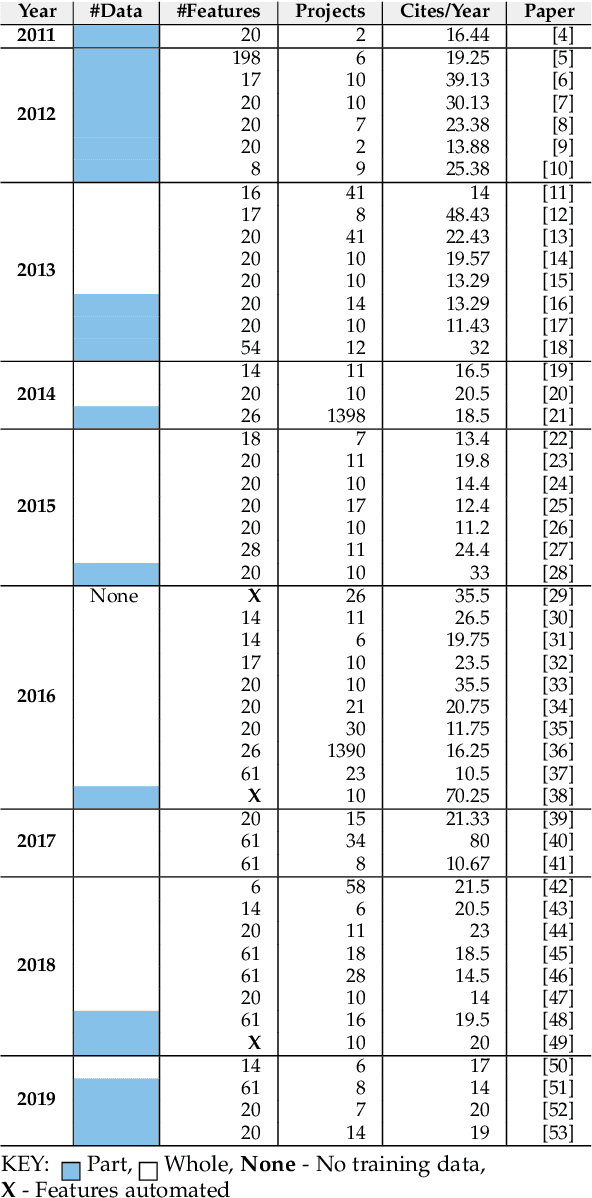

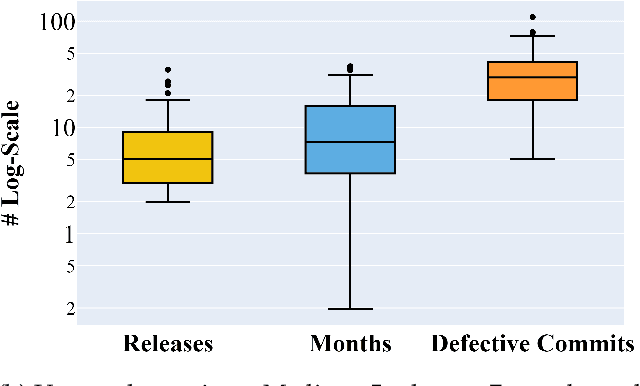
Before researchers rush to reason across all available data, they should first check if the information is densest within some small region. We say this since, in 240 GitHub projects, we find that the information in that data ``clumps'' towards the earliest parts of the project. In fact, a defect prediction model learned from just the first 150 commits works as well, or better than state-of-the-art alternatives. Using just this early life cycle data, we can build models very quickly (using weeks, not months, of CPU time). Also, we can find simple models (with just two features) that generalize to hundreds of software projects. Based on this experience, we warn that prior work on generalizing software engineering defect prediction models may have needlessly complicated an inherently simple process. Further, prior work that focused on later-life cycle data now needs to be revisited since their conclusions were drawn from relatively uninformative regions. Replication note: all our data and scripts are online at https://github.com/snaraya7/early-defect-prediction-tse.
Early Life Cycle Software Defect Prediction. Why? How?
Nov 26, 2020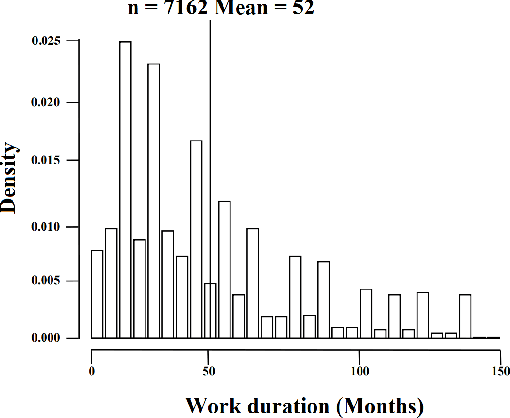
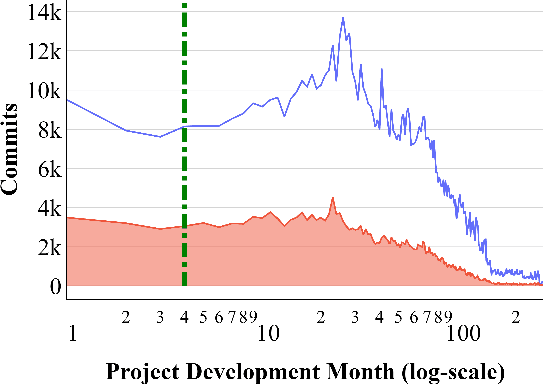
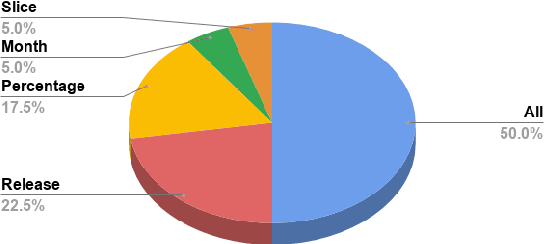
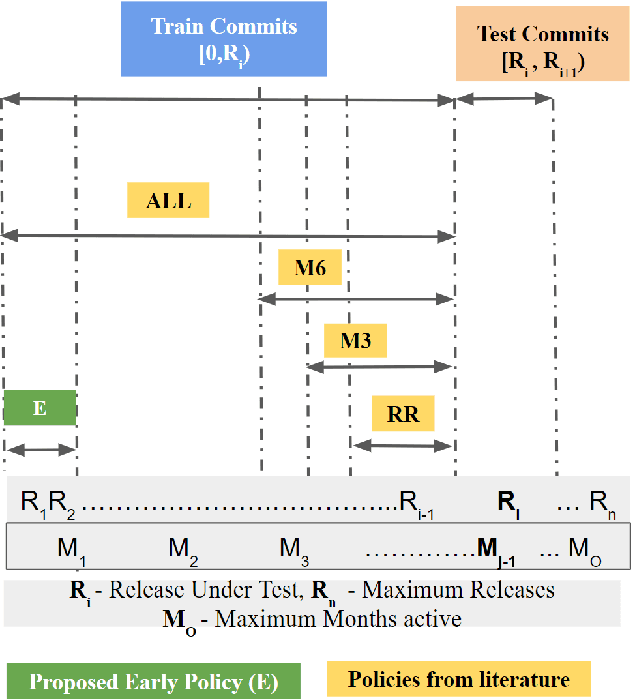
Many methods in defect prediction are "datahungry"; i.e. (1) given a choice of using more data, or some smaller sample, researchers assume that more is better; (2) when data is missing, researchers take elaborate steps to transfer data from another project; and (3) given a choice of older data or some more recent sample, researchers usually ignore older data. Based on the analysis of hundreds of popular Github projects (with 1.2 million commits), we suggest that for defect prediction, there is limited value in such data-hungry approaches. Data for our sample of projects last for 84 months and contains 3,728 commits (median values). Across these projects, most of the defects occur very early in their life cycle. Hence, defect predictors learned from the first 150 commits and four months perform just as well as anything else. This means that, contrary to the "data-hungry" approach, (1) small samples of data from these projects are all that is needed for defect prediction; (2) transfer learning has limited value since it is needed only for the first 4 of 84 months (i.e. just 4% of the life cycle); (3) after the first few months, we need not continually update our defect prediction models. We hope these results inspire other researchers to adopt a "simplicity-first" approach to their work. Certainly, there are domains that require a complex and data-hungry analysis. But before assuming complexity, it is prudent to check the raw data looking for "short cuts" that simplify the whole analysis.