 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Exploratory Study of AI System Risk Assessment from the Lens of Data Distribution and Uncertainty
Dec 13, 2022Deep learning (DL) has become a driving force and has been widely adopted in many domains and applications with competitive performance. In practice, to solve the nontrivial and complicated tasks in real-world applications, DL is often not used standalone, but instead contributes as a piece of gadget of a larger complex AI system. Although there comes a fast increasing trend to study the quality issues of deep neural networks (DNNs) at the model level, few studies have been performed to investigate the quality of DNNs at both the unit level and the potential impacts on the system level. More importantly, it also lacks systematic investigation on how to perform the risk assessment for AI systems from unit level to system level. To bridge this gap, this paper initiates an early exploratory study of AI system risk assessment from both the data distribution and uncertainty angles to address these issues. We propose a general framework with an exploratory study for analyzing AI systems. After large-scale (700+ experimental configurations and 5000+ GPU hours) experiments and in-depth investigations, we reached a few key interesting findings that highlight the practical need and opportunities for more in-depth investigations into AI systems.
Verifying Attention Robustness of Deep Neural Networks against Semantic Perturbations
Jul 13, 2022


It is known that deep neural networks (DNNs) classify an input image by paying particular attention to certain specific pixels; a graphical representation of the magnitude of attention to each pixel is called a saliency-map. Saliency-maps are used to check the validity of the classification decision basis, e.g., it is not a valid basis for classification if a DNN pays more attention to the background rather than the subject of an image. Semantic perturbations can significantly change the saliency-map. In this work, we propose the first verification method for attention robustness, i.e., the local robustness of the changes in the saliency-map against combinations of semantic perturbations. Specifically, our method determines the range of the perturbation parameters (e.g., the brightness change) that maintains the difference between the actual saliency-map change and the expected saliency-map change below a given threshold value. Our method is based on activation region traversals, focusing on the outermost robust boundary for scalability on larger DNNs. Experimental results demonstrate that our method can show the extent to which DNNs can classify with the same basis regardless of semantic perturbations and report on performance and performance factors of activation region traversals.
NeuRecover: Regression-Controlled Repair of Deep Neural Networks with Training History
Mar 04, 2022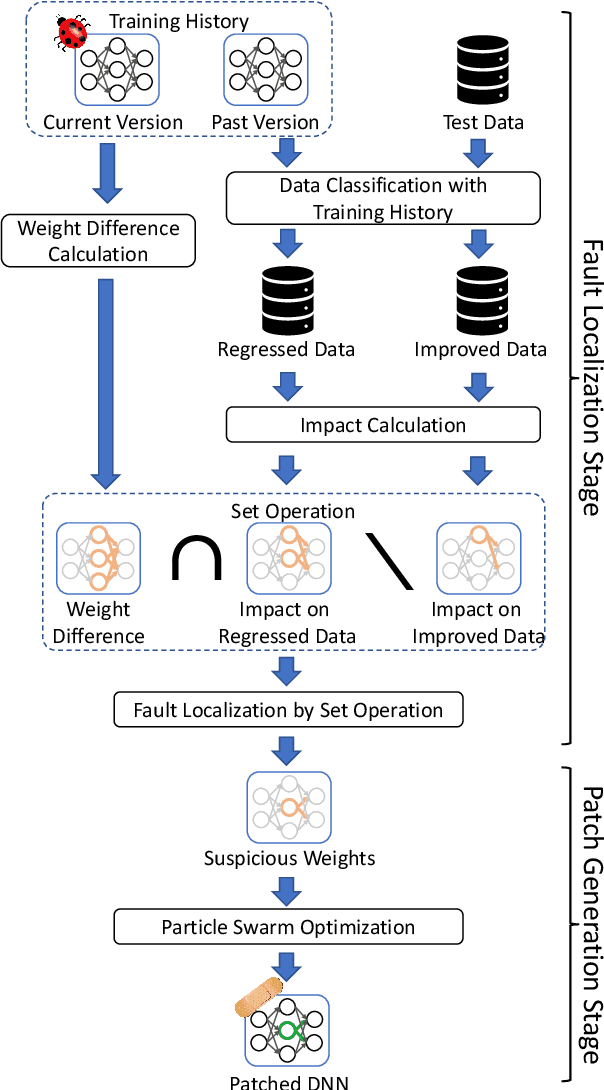
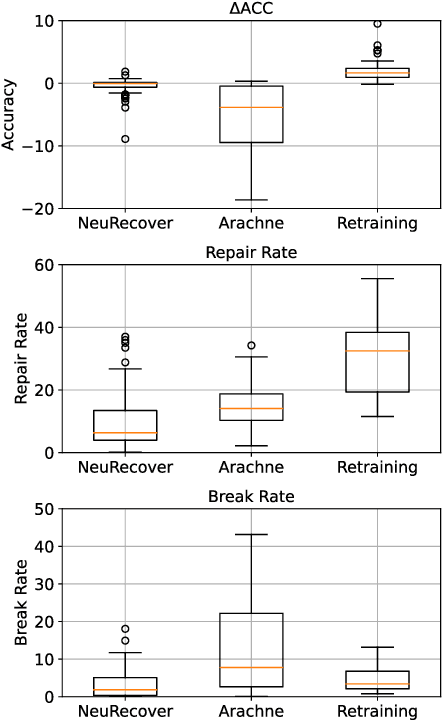
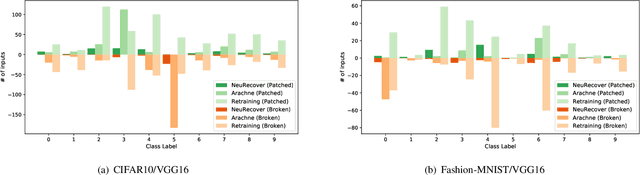
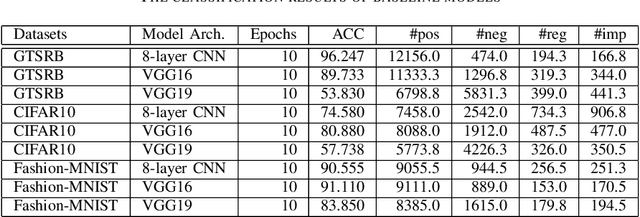
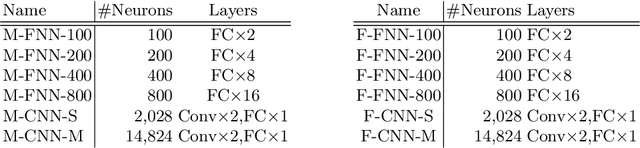
Systematic techniques to improve quality of deep neural networks (DNNs) are critical given the increasing demand for practical applications including safety-critical ones. The key challenge comes from the little controllability in updating DNNs. Retraining to fix some behavior often has a destructive impact on other behavior, causing regressions, i.e., the updated DNN fails with inputs correctly handled by the original one. This problem is crucial when engineers are required to investigate failures in intensive assurance activities for safety or trust. Search-based repair techniques for DNNs have potentials to tackle this challenge by enabling localized updates only on "responsible parameters" inside the DNN. However, the potentials have not been explored to realize sufficient controllability to suppress regressions in DNN repair tasks. In this paper, we propose a novel DNN repair method that makes use of the training history for judging which DNN parameters should be changed or not to suppress regressions. We implemented the method into a tool called NeuRecover and evaluated it with three datasets. Our method outperformed the existing method by achieving often less than a quarter, even a tenth in some cases, number of regressions. Our method is especially effective when the repair requirements are tight to fix specific failure types. In such cases, our method showed stably low rates (<2%) of regressions, which were in many cases a tenth of regressions caused by retraining.
AugmentedCode: Examining the Effects of Natural Language Resources in Code Retrieval Models
Oct 16, 2021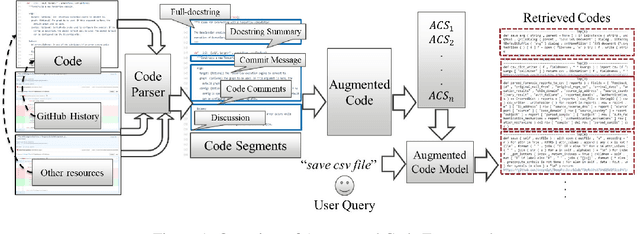

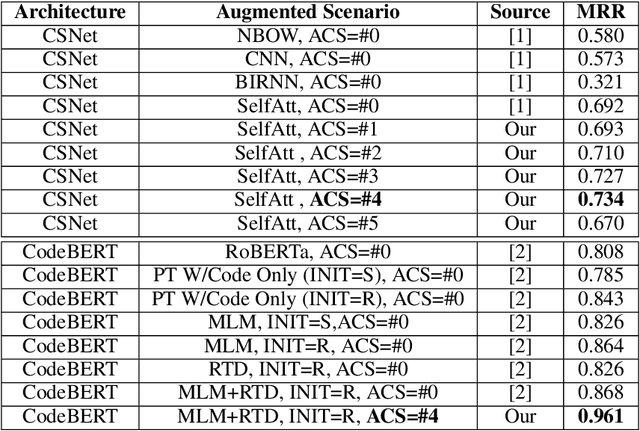
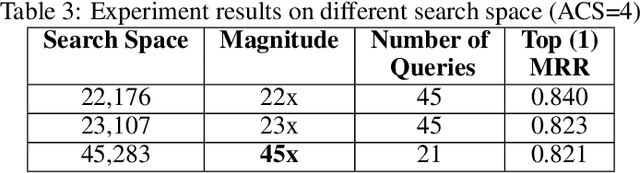
Code retrieval is allowing software engineers to search codes through a natural language query, which relies on both natural language processing and software engineering techniques. There have been several attempts on code retrieval from searching snippet codes to function codes. In this paper, we introduce Augmented Code (AugmentedCode) retrieval which takes advantage of existing information within the code and constructs augmented programming language to improve the code retrieval models' performance. We curated a large corpus of Python and showcased the the framework and the results of augmented programming language which outperforms on CodeSearchNet and CodeBERT with a Mean Reciprocal Rank (MRR) of 0.73 and 0.96, respectively. The outperformed fine-tuned augmented code retrieval model is published in HuggingFace at https://huggingface.co/Fujitsu/AugCode and a demonstration video is available at: https://youtu.be/mnZrUTANjGs .