 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Experience Report on Regression-Free Repair of Deep Neural Network Model
Mar 10, 2025Systems based on Deep Neural Networks (DNNs) are increasingly being used in industry. In the process of system operation, DNNs need to be updated in order to improve their performance. When updating DNNs, systems used in companies that require high reliability must have as few regressions as possible. Since the update of DNNs has a data-driven nature, it is difficult to suppress regressions as expected by developers. This paper identifies the requirements for DNN updating in industry and presents a case study using techniques to meet those requirements. In the case study, we worked on satisfying the requirement to update models trained on car images collected in Fujitsu assuming security applications without regression for a specific class. We were able to suppress regression by customizing the objective function based on NeuRecover, a DNN repair technique. Moreover, we discuss some of the challenges identified in the case study.
An Exploratory Study of AI System Risk Assessment from the Lens of Data Distribution and Uncertainty
Dec 13, 2022Deep learning (DL) has become a driving force and has been widely adopted in many domains and applications with competitive performance. In practice, to solve the nontrivial and complicated tasks in real-world applications, DL is often not used standalone, but instead contributes as a piece of gadget of a larger complex AI system. Although there comes a fast increasing trend to study the quality issues of deep neural networks (DNNs) at the model level, few studies have been performed to investigate the quality of DNNs at both the unit level and the potential impacts on the system level. More importantly, it also lacks systematic investigation on how to perform the risk assessment for AI systems from unit level to system level. To bridge this gap, this paper initiates an early exploratory study of AI system risk assessment from both the data distribution and uncertainty angles to address these issues. We propose a general framework with an exploratory study for analyzing AI systems. After large-scale (700+ experimental configurations and 5000+ GPU hours) experiments and in-depth investigations, we reached a few key interesting findings that highlight the practical need and opportunities for more in-depth investigations into AI systems.
Practical Insights of Repairing Model Problems on Image Classification
May 14, 2022
Additional training of a deep learning model can cause negative effects on the results, turning an initially positive sample into a negative one (degradation). Such degradation is possible in real-world use cases due to the diversity of sample characteristics. That is, a set of samples is a mixture of critical ones which should not be missed and less important ones. Therefore, we cannot understand the performance by accuracy alone. While existing research aims to prevent a model degradation, insights into the related methods are needed to grasp their benefits and limitations. In this talk, we will present implications derived from a comparison of methods for reducing degradation. Especially, we formulated use cases for industrial settings in terms of arrangements of a data set. The results imply that a practitioner should care about better method continuously considering dataset availability and life cycle of an AI system because of a trade-off between accuracy and preventing degradation.
NeuRecover: Regression-Controlled Repair of Deep Neural Networks with Training History
Mar 04, 2022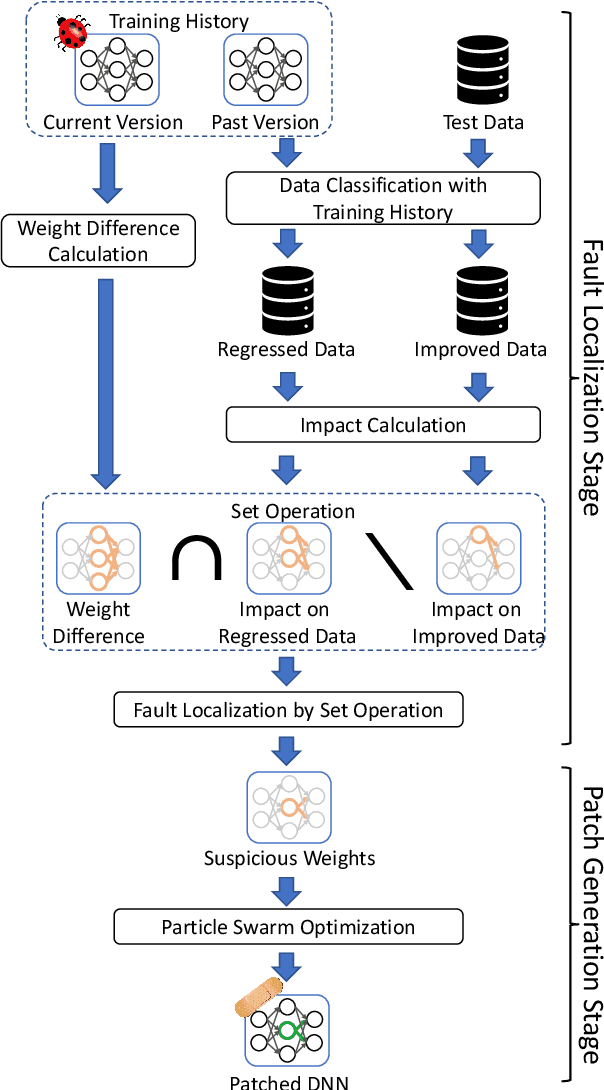
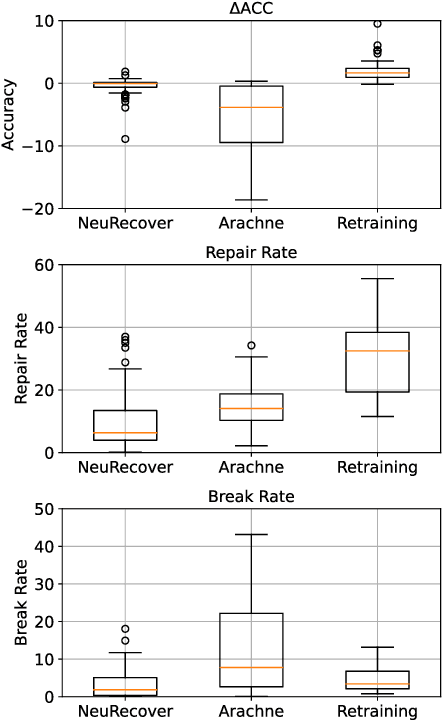
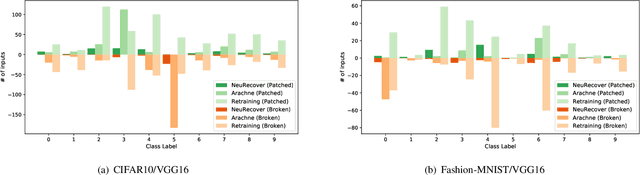
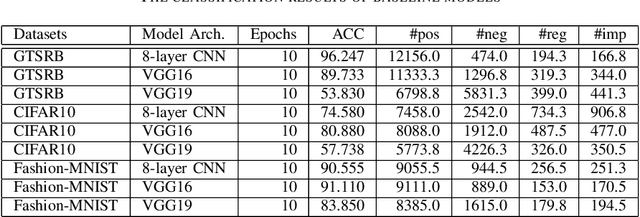
Systematic techniques to improve quality of deep neural networks (DNNs) are critical given the increasing demand for practical applications including safety-critical ones. The key challenge comes from the little controllability in updating DNNs. Retraining to fix some behavior often has a destructive impact on other behavior, causing regressions, i.e., the updated DNN fails with inputs correctly handled by the original one. This problem is crucial when engineers are required to investigate failures in intensive assurance activities for safety or trust. Search-based repair techniques for DNNs have potentials to tackle this challenge by enabling localized updates only on "responsible parameters" inside the DNN. However, the potentials have not been explored to realize sufficient controllability to suppress regressions in DNN repair tasks. In this paper, we propose a novel DNN repair method that makes use of the training history for judging which DNN parameters should be changed or not to suppress regressions. We implemented the method into a tool called NeuRecover and evaluated it with three datasets. Our method outperformed the existing method by achieving often less than a quarter, even a tenth in some cases, number of regressions. Our method is especially effective when the repair requirements are tight to fix specific failure types. In such cases, our method showed stably low rates (<2%) of regressions, which were in many cases a tenth of regressions caused by retraining.