 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Using Certified Training towards Empirical Robustness
Oct 02, 2024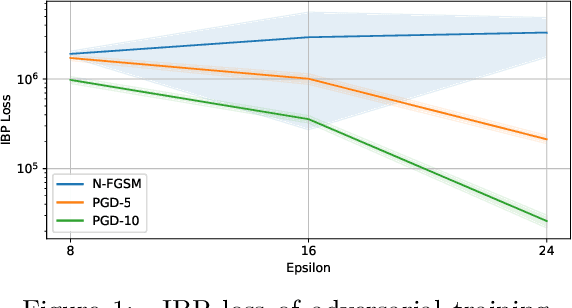
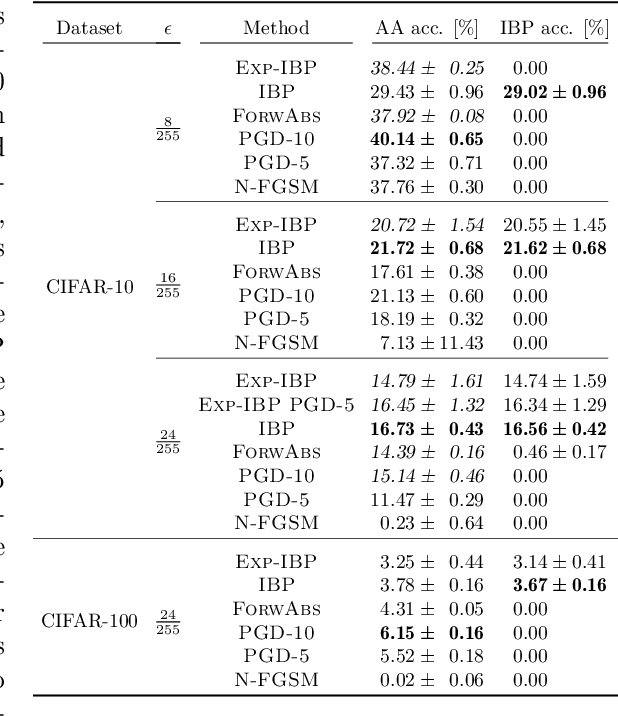
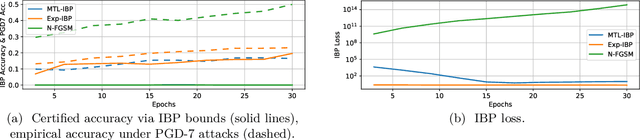

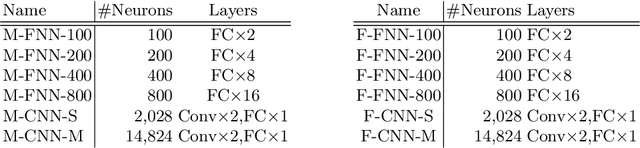
Adversarial training is arguably the most popular way to provide empirical robustness against specific adversarial examples. While variants based on multi-step attacks incur significant computational overhead, single-step variants are vulnerable to a failure mode known as catastrophic overfitting, which hinders their practical utility for large perturbations. A parallel line of work, certified training, has focused on producing networks amenable to formal guarantees of robustness against any possible attack. However, the wide gap between the best-performing empirical and certified defenses has severely limited the applicability of the latter. Inspired by recent developments in certified training, which rely on a combination of adversarial attacks with network over-approximations, and by the connections between local linearity and catastrophic overfitting, we present experimental evidence on the practical utility and limitations of using certified training towards empirical robustness. We show that, when tuned for the purpose, a recent certified training algorithm can prevent catastrophic overfitting on single-step attacks, and that it can bridge the gap to multi-step baselines under appropriate experimental settings. Finally, we present a novel regularizer for network over-approximations that can achieve similar effects while markedly reducing runtime.
Verifying Attention Robustness of Deep Neural Networks against Semantic Perturbations
Jul 13, 2022


It is known that deep neural networks (DNNs) classify an input image by paying particular attention to certain specific pixels; a graphical representation of the magnitude of attention to each pixel is called a saliency-map. Saliency-maps are used to check the validity of the classification decision basis, e.g., it is not a valid basis for classification if a DNN pays more attention to the background rather than the subject of an image. Semantic perturbations can significantly change the saliency-map. In this work, we propose the first verification method for attention robustness, i.e., the local robustness of the changes in the saliency-map against combinations of semantic perturbations. Specifically, our method determines the range of the perturbation parameters (e.g., the brightness change) that maintains the difference between the actual saliency-map change and the expected saliency-map change below a given threshold value. Our method is based on activation region traversals, focusing on the outermost robust boundary for scalability on larger DNNs. Experimental results demonstrate that our method can show the extent to which DNNs can classify with the same basis regardless of semantic perturbations and report on performance and performance factors of activation region traversals.
A Review of Formal Methods applied to Machine Learning
Apr 21, 2021


We review state-of-the-art formal methods applied to the emerging field of the verification of machine learning systems. Formal methods can provide rigorous correctness guarantees on hardware and software systems. Thanks to the availability of mature tools, their use is well established in the industry, and in particular to check safety-critical applications as they undergo a stringent certification process. As machine learning is becoming more popular, machine-learned components are now considered for inclusion in critical systems. This raises the question of their safety and their verification. Yet, established formal methods are limited to classic, i.e. non machine-learned software. Applying formal methods to verify systems that include machine learning has only been considered recently and poses novel challenges in soundness, precision, and scalability. We first recall established formal methods and their current use in an exemplar safety-critical field, avionic software, with a focus on abstract interpretation based techniques as they provide a high level of scalability. This provides a golden standard and sets high expectations for machine learning verification. We then provide a comprehensive and detailed review of the formal methods developed so far for machine learning, highlighting their strengths and limitations. The large majority of them verify trained neural networks and employ either SMT, optimization, or abstract interpretation techniques. We also discuss methods for support vector machines and decision tree ensembles, as well as methods targeting training and data preparation, which are critical but often neglected aspects of machine learning. Finally, we offer perspectives for future research directions towards the formal verification of machine learning systems.
Fair Training of Decision Tree Classifiers
Jan 04, 2021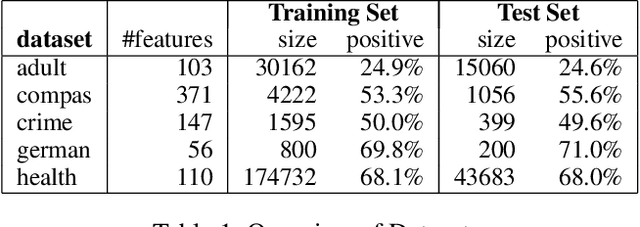
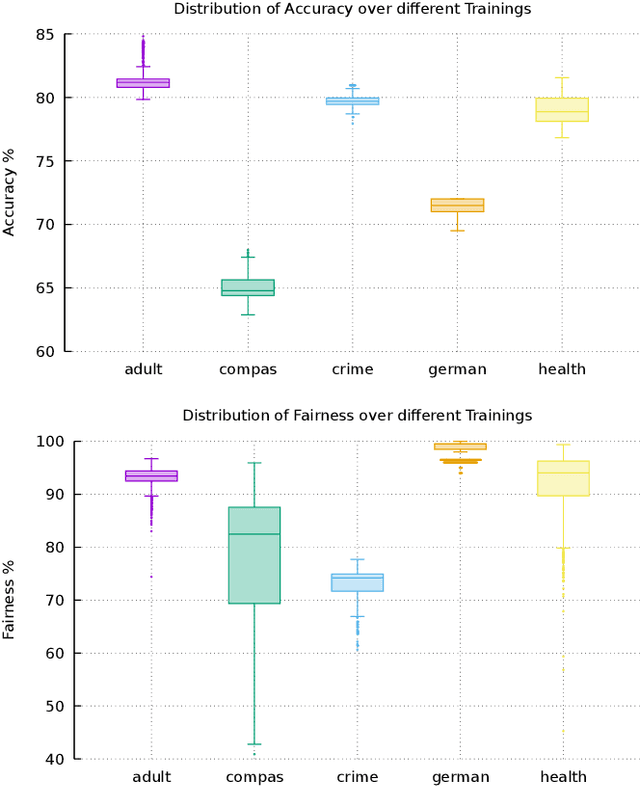
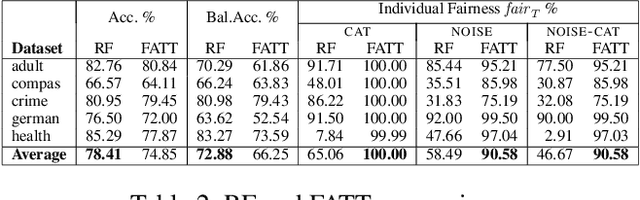
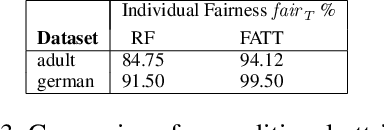
We study the problem of formally verifying individual fairness of decision tree ensembles, as well as training tree models which maximize both accuracy and individual fairness. In our approach, fairness verification and fairness-aware training both rely on a notion of stability of a classification model, which is a variant of standard robustness under input perturbations used in adversarial machine learning. Our verification and training methods leverage abstract interpretation, a well established technique for static program analysis which is able to automatically infer assertions about stability properties of decision trees. By relying on a tool for adversarial training of decision trees, our fairness-aware learning method has been implemented and experimentally evaluated on the reference datasets used to assess fairness properties. The experimental results show that our approach is able to train tree models exhibiting a high degree of individual fairness w.r.t. the natural state-of-the-art CART trees and random forests. Moreover, as a by-product, these fair decision trees turn out to be significantly compact, thus enhancing the interpretability of their fairness properties.