 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Using Certified Training towards Empirical Robustness
Oct 02, 2024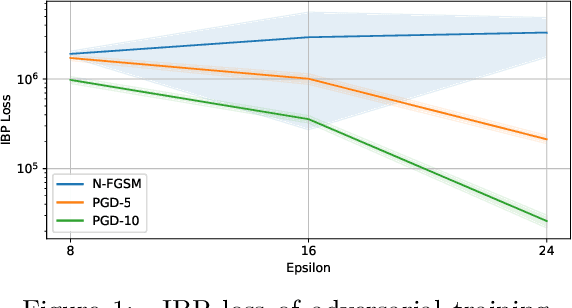
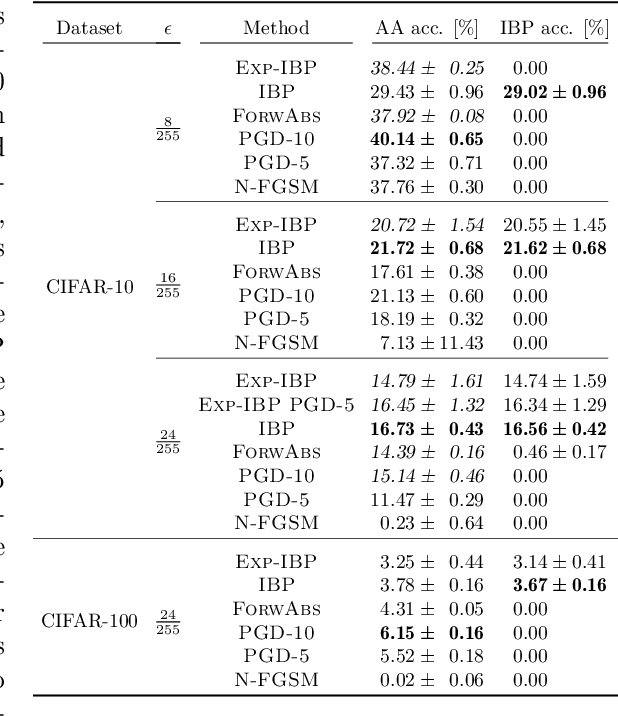
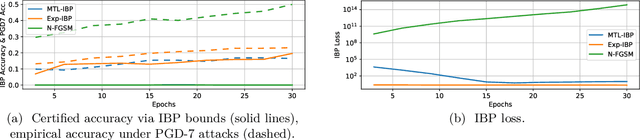

Adversarial training is arguably the most popular way to provide empirical robustness against specific adversarial examples. While variants based on multi-step attacks incur significant computational overhead, single-step variants are vulnerable to a failure mode known as catastrophic overfitting, which hinders their practical utility for large perturbations. A parallel line of work, certified training, has focused on producing networks amenable to formal guarantees of robustness against any possible attack. However, the wide gap between the best-performing empirical and certified defenses has severely limited the applicability of the latter. Inspired by recent developments in certified training, which rely on a combination of adversarial attacks with network over-approximations, and by the connections between local linearity and catastrophic overfitting, we present experimental evidence on the practical utility and limitations of using certified training towards empirical robustness. We show that, when tuned for the purpose, a recent certified training algorithm can prevent catastrophic overfitting on single-step attacks, and that it can bridge the gap to multi-step baselines under appropriate experimental settings. Finally, we present a novel regularizer for network over-approximations that can achieve similar effects while markedly reducing runtime.
CaBRNet, an open-source library for developing and evaluating Case-Based Reasoning Models
Sep 25, 2024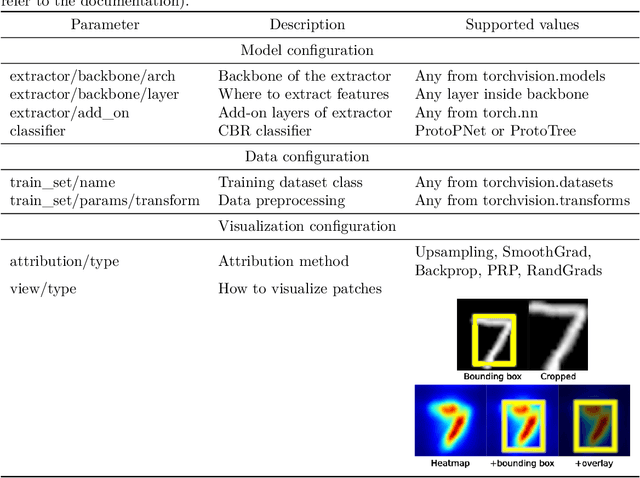
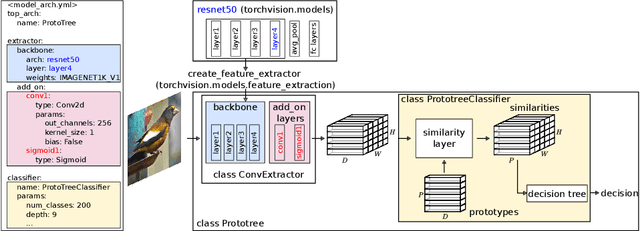
In the field of explainable AI, a vibrant effort is dedicated to the design of self-explainable models, as a more principled alternative to post-hoc methods that attempt to explain the decisions after a model opaquely makes them. However, this productive line of research suffers from common downsides: lack of reproducibility, unfeasible comparison, diverging standards. In this paper, we propose CaBRNet, an open-source, modular, backward-compatible framework for Case-Based Reasoning Networks: https://github.com/aiser-team/cabrnet.
PARTICUL: Part Identification with Confidence measure using Unsupervised Learning
Jun 27, 2022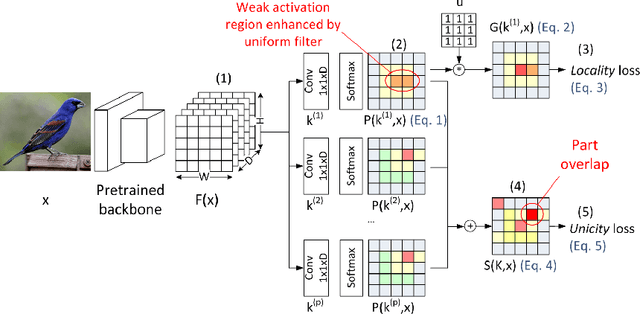
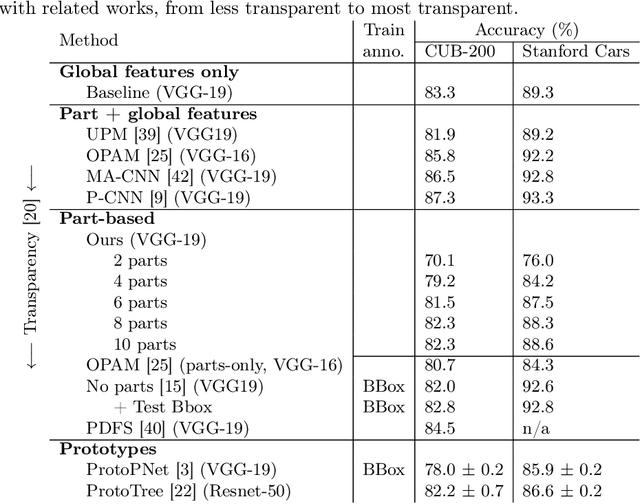
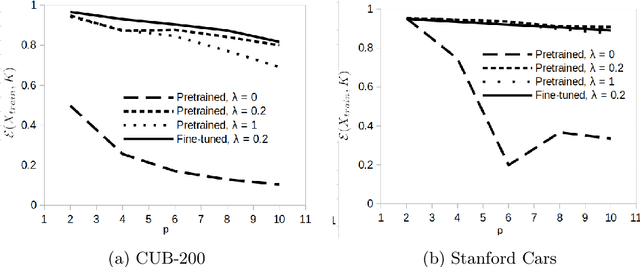

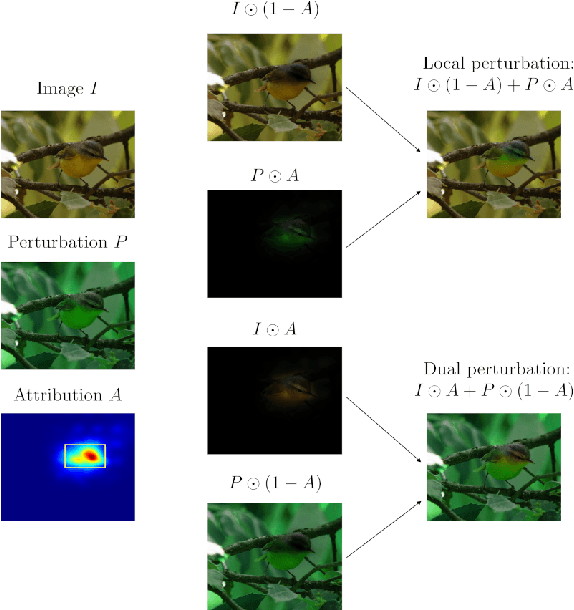
In this paper, we present PARTICUL, a novel algorithm for unsupervised learning of part detectors from datasets used in fine-grained recognition. It exploits the macro-similarities of all images in the training set in order to mine for recurring patterns in the feature space of a pre-trained convolutional neural network. We propose new objective functions enforcing the locality and unicity of the detected parts. Additionally, we embed our detectors with a confidence measure based on correlation scores, allowing the system to estimate the visibility of each part. We apply our method on two public fine-grained datasets (Caltech-UCSD Bird 200 and Stanford Cars) and show that our detectors can consistently highlight parts of the object while providing a good measure of the confidence in their prediction. We also demonstrate that these detectors can be directly used to build part-based fine-grained classifiers that provide a good compromise between the transparency of prototype-based approaches and the performance of non-interpretable methods.
CAISAR: A platform for Characterizing Artificial Intelligence Safety and Robustness
Jun 07, 2022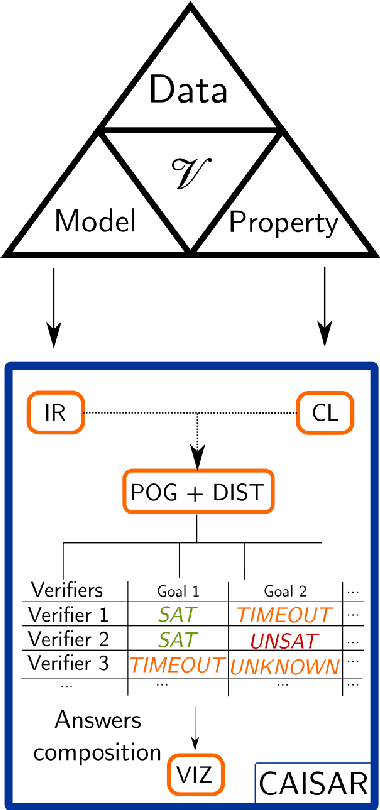
We present CAISAR, an open-source platform under active development for the characterization of AI systems' robustness and safety. CAISAR provides a unified entry point for defining verification problems by using WhyML, the mature and expressive language of the Why3 verification platform. Moreover, CAISAR orchestrates and composes state-of-the-art machine learning verification tools which, individually, are not able to efficiently handle all problems but, collectively, can cover a growing number of properties. Our aim is to assist, on the one hand, the V\&V process by reducing the burden of choosing the methodology tailored to a given verification problem, and on the other hand the tools developers by factorizing useful features-visualization, report generation, property description-in one platform. CAISAR will soon be available at https://git.frama-c.com/pub/caisar.
DISCO Verification: Division of Input Space into COnvex polytopes for neural network verification
May 17, 2021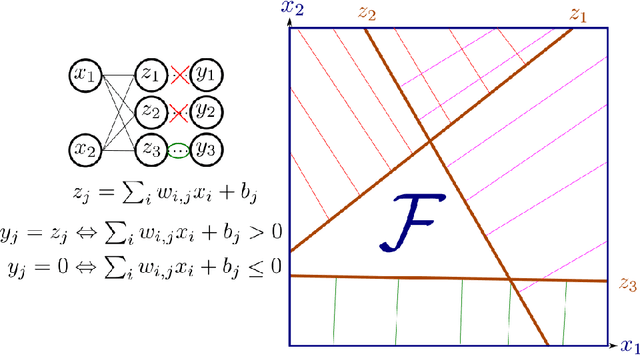

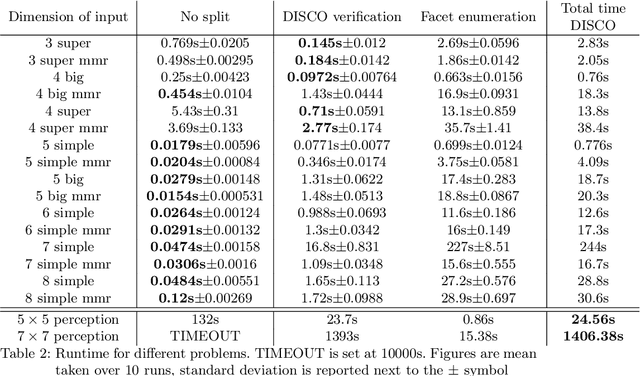
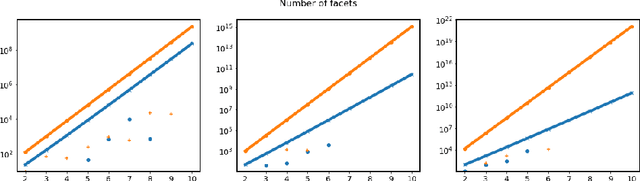
The impressive results of modern neural networks partly come from their non linear behaviour. Unfortunately, this property makes it very difficult to apply formal verification tools, even if we restrict ourselves to networks with a piecewise linear structure. However, such networks yields subregions that are linear and thus simpler to analyse independently. In this paper, we propose a method to simplify the verification problem by operating a partitionning into multiple linear subproblems. To evaluate the feasibility of such an approach, we perform an empirical analysis of neural networks to estimate the number of linear regions, and compare them to the bounds currently known. We also present the impact of a technique aiming at reducing the number of linear regions during training.
CAMUS: A Framework to Build Formal Specifications for Deep Perception Systems Using Simulators
Nov 25, 2019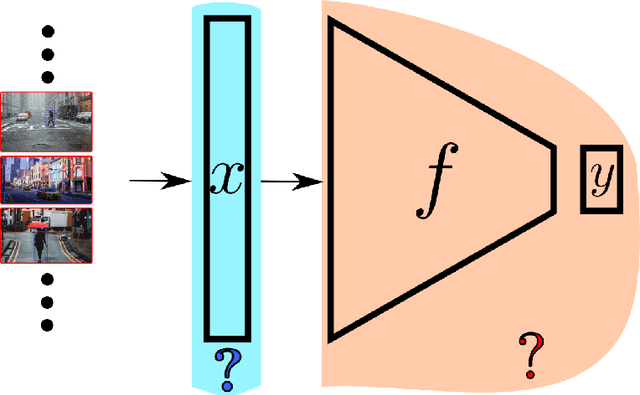
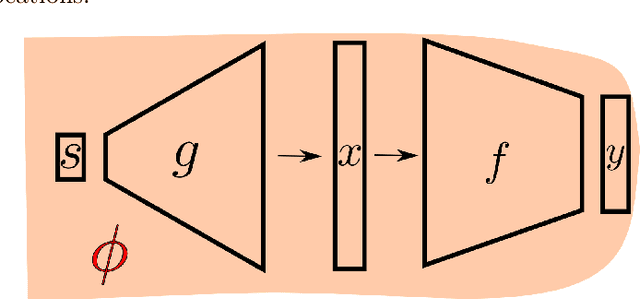
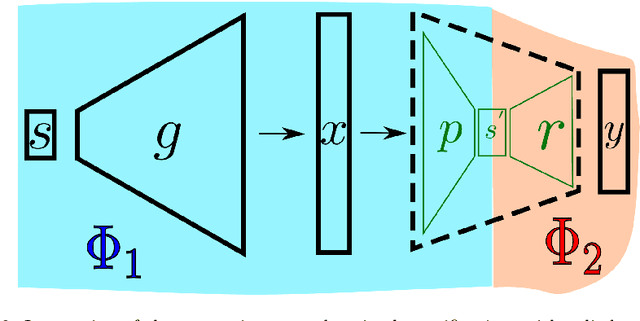

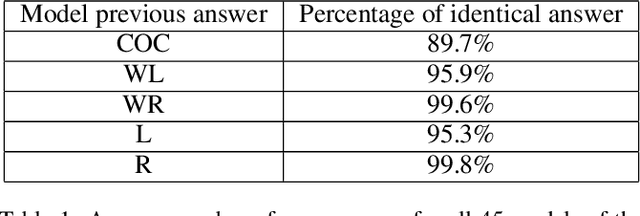
The topic of provable deep neural network robustness has raised considerable interest in recent years. Most research has focused on adversarial robustness, which studies the robustness of perceptive models in the neighbourhood of particular samples. However, other works have proved global properties of smaller neural networks. Yet, formally verifying perception remains uncharted. This is due notably to the lack of relevant properties to verify, as the distribution of possible inputs cannot be formally specified. We propose to take advantage of the simulators often used either to train machine learning models or to check them with statistical tests, a growing trend in industry. Our formulation allows us to formally express and verify safety properties on perception units, covering all cases that could ever be generated by the simulator, to the difference of statistical tests which cover only seen examples. Along with this theoretical formulation , we provide a tool to translate deep learning models into standard logical formulae. As a proof of concept, we train a toy example mimicking an autonomous car perceptive unit, and we formally verify that it will never fail to capture the relevant information in the provided inputs.