 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePARTICUL: Part Identification with Confidence measure using Unsupervised Learning
Jun 27, 2022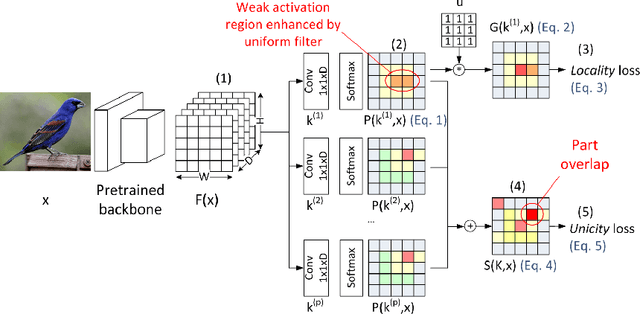
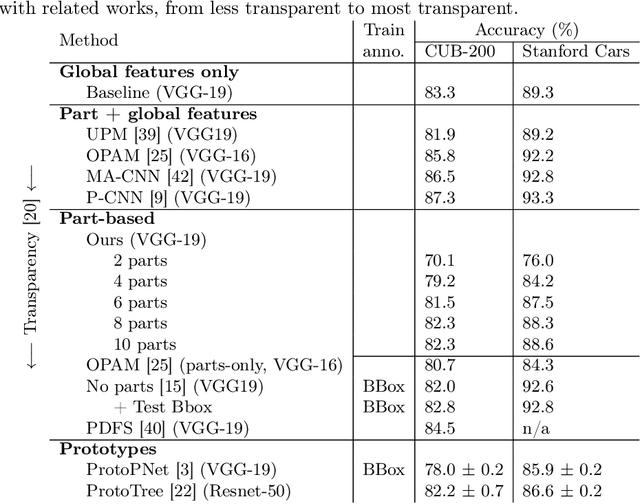
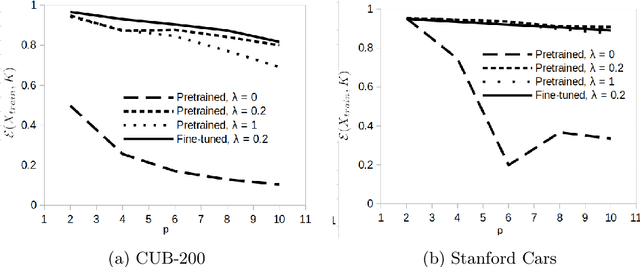

In this paper, we present PARTICUL, a novel algorithm for unsupervised learning of part detectors from datasets used in fine-grained recognition. It exploits the macro-similarities of all images in the training set in order to mine for recurring patterns in the feature space of a pre-trained convolutional neural network. We propose new objective functions enforcing the locality and unicity of the detected parts. Additionally, we embed our detectors with a confidence measure based on correlation scores, allowing the system to estimate the visibility of each part. We apply our method on two public fine-grained datasets (Caltech-UCSD Bird 200 and Stanford Cars) and show that our detectors can consistently highlight parts of the object while providing a good measure of the confidence in their prediction. We also demonstrate that these detectors can be directly used to build part-based fine-grained classifiers that provide a good compromise between the transparency of prototype-based approaches and the performance of non-interpretable methods.
Coupled Ensembles of Neural Networks
Sep 18, 2017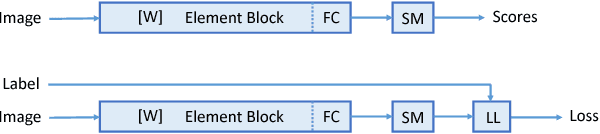
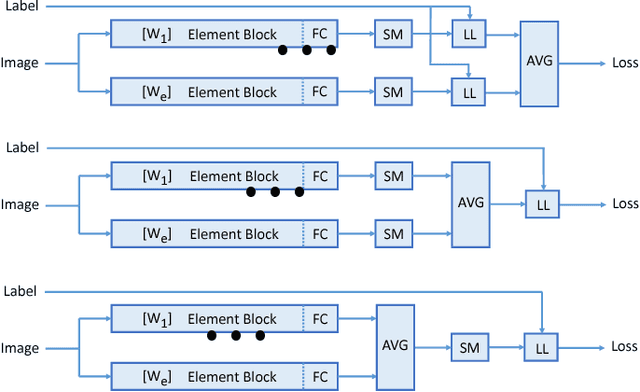
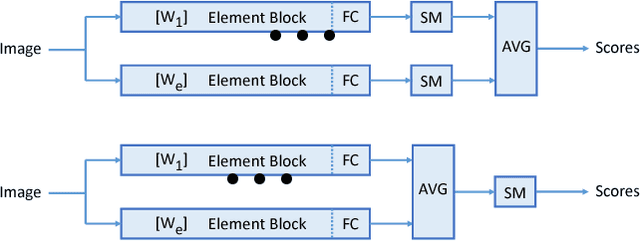
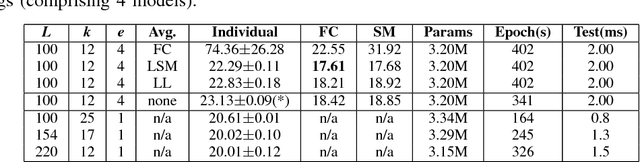
We investigate in this paper the architecture of deep convolutional networks. Building on existing state of the art models, we propose a reconfiguration of the model parameters into several parallel branches at the global network level, with each branch being a standalone CNN. We show that this arrangement is an efficient way to significantly reduce the number of parameters without losing performance or to significantly improve the performance with the same level of performance. The use of branches brings an additional form of regularization. In addition to the split into parallel branches, we propose a tighter coupling of these branches by placing the "fuse (averaging) layer" before the Log-Likelihood and SoftMax layers during training. This gives another significant performance improvement, the tighter coupling favouring the learning of better representations, even at the level of the individual branches. We refer to this branched architecture as "coupled ensembles". The approach is very generic and can be applied with almost any DCNN architecture. With coupled ensembles of DenseNet-BC and parameter budget of 25M, we obtain error rates of 2.92%, 15.68% and 1.50% respectively on CIFAR-10, CIFAR-100 and SVHN tasks. For the same budget, DenseNet-BC has error rate of 3.46%, 17.18%, and 1.8% respectively. With ensembles of coupled ensembles, of DenseNet-BC networks, with 50M total parameters, we obtain error rates of 2.72%, 15.13% and 1.42% respectively on these tasks.