 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Modal Attribute Extraction for E-Commerce
Mar 07, 2022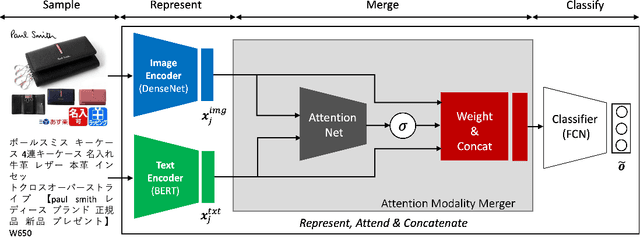
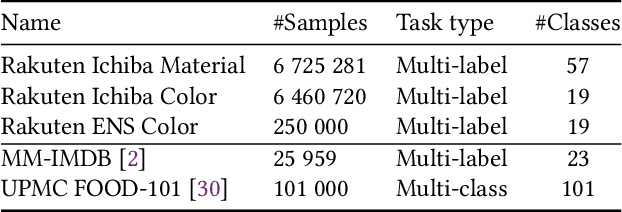

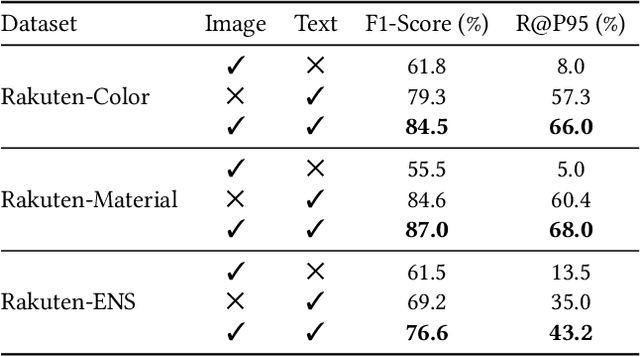
To improve users' experience as they navigate the myriad of options offered by online marketplaces, it is essential to have well-organized product catalogs. One key ingredient to that is the availability of product attributes such as color or material. However, on some marketplaces such as Rakuten-Ichiba, which we focus on, attribute information is often incomplete or even missing. One promising solution to this problem is to rely on deep models pre-trained on large corpora to predict attributes from unstructured data, such as product descriptive texts and images (referred to as modalities in this paper). However, we find that achieving satisfactory performance with this approach is not straightforward but rather the result of several refinements, which we discuss in this paper. We provide a detailed description of our approach to attribute extraction, from investigating strong single-modality methods, to building a solid multimodal model combining textual and visual information. One key component of our multimodal architecture is a novel approach to seamlessly combine modalities, which is inspired by our single-modality investigations. In practice, we notice that this new modality-merging method may suffer from a modality collapse issue, i.e., it neglects one modality. Hence, we further propose a mitigation to this problem based on a principled regularization scheme. Experiments on Rakuten-Ichiba data provide empirical evidence for the benefits of our approach, which has been also successfully deployed to Rakuten-Ichiba. We also report results on publicly available datasets showing that our model is competitive compared to several recent multimodal and unimodal baselines.
Coupled Ensembles of Neural Networks
Sep 18, 2017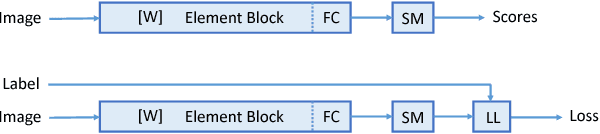
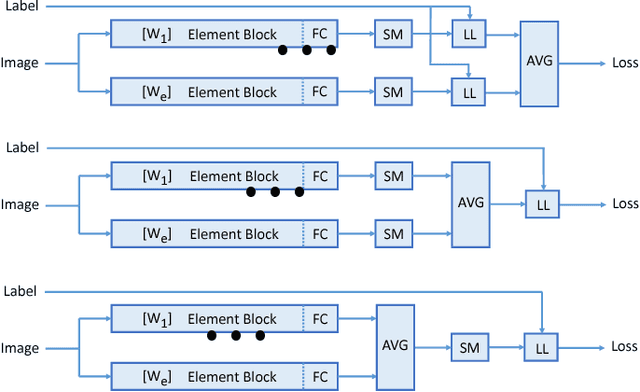
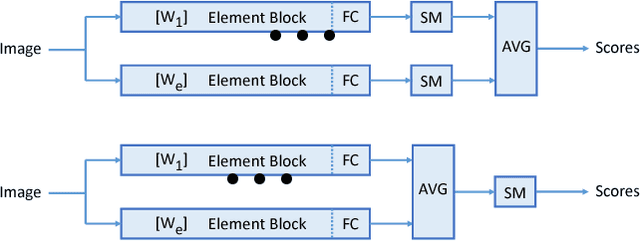
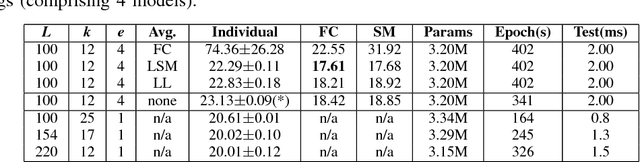
We investigate in this paper the architecture of deep convolutional networks. Building on existing state of the art models, we propose a reconfiguration of the model parameters into several parallel branches at the global network level, with each branch being a standalone CNN. We show that this arrangement is an efficient way to significantly reduce the number of parameters without losing performance or to significantly improve the performance with the same level of performance. The use of branches brings an additional form of regularization. In addition to the split into parallel branches, we propose a tighter coupling of these branches by placing the "fuse (averaging) layer" before the Log-Likelihood and SoftMax layers during training. This gives another significant performance improvement, the tighter coupling favouring the learning of better representations, even at the level of the individual branches. We refer to this branched architecture as "coupled ensembles". The approach is very generic and can be applied with almost any DCNN architecture. With coupled ensembles of DenseNet-BC and parameter budget of 25M, we obtain error rates of 2.92%, 15.68% and 1.50% respectively on CIFAR-10, CIFAR-100 and SVHN tasks. For the same budget, DenseNet-BC has error rate of 3.46%, 17.18%, and 1.8% respectively. With ensembles of coupled ensembles, of DenseNet-BC networks, with 50M total parameters, we obtain error rates of 2.72%, 15.13% and 1.42% respectively on these tasks.