 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEarly Life Cycle Software Defect Prediction. Why? How?
Paper and Code
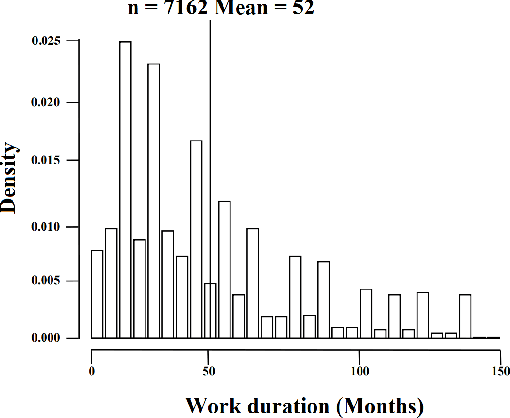
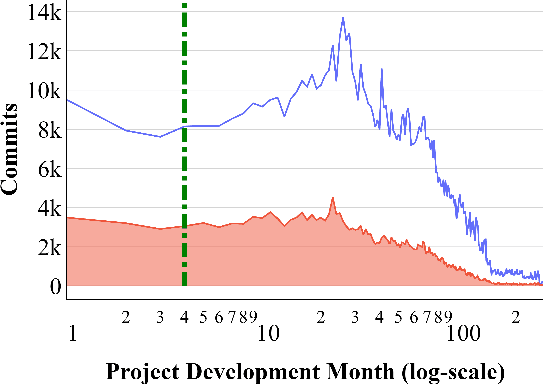
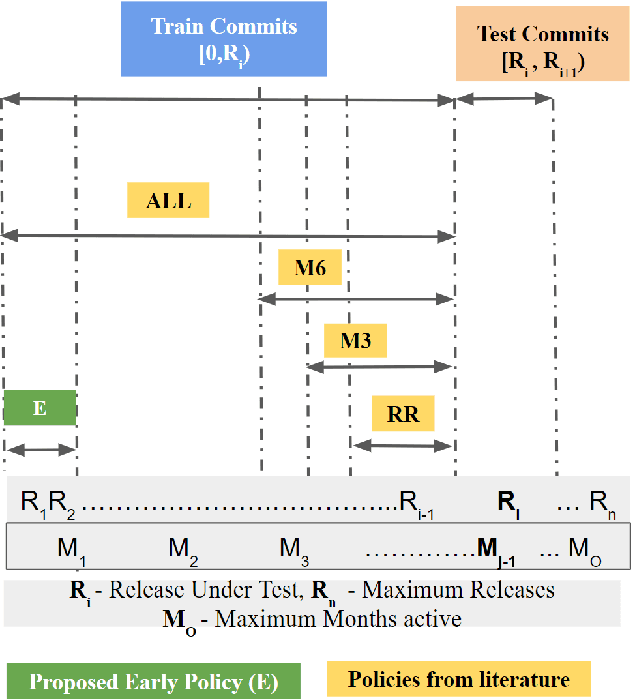
Many methods in defect prediction are "datahungry"; i.e. (1) given a choice of using more data, or some smaller sample, researchers assume that more is better; (2) when data is missing, researchers take elaborate steps to transfer data from another project; and (3) given a choice of older data or some more recent sample, researchers usually ignore older data. Based on the analysis of hundreds of popular Github projects (with 1.2 million commits), we suggest that for defect prediction, there is limited value in such data-hungry approaches. Data for our sample of projects last for 84 months and contains 3,728 commits (median values). Across these projects, most of the defects occur very early in their life cycle. Hence, defect predictors learned from the first 150 commits and four months perform just as well as anything else. This means that, contrary to the "data-hungry" approach, (1) small samples of data from these projects are all that is needed for defect prediction; (2) transfer learning has limited value since it is needed only for the first 4 of 84 months (i.e. just 4% of the life cycle); (3) after the first few months, we need not continually update our defect prediction models. We hope these results inspire other researchers to adopt a "simplicity-first" approach to their work. Certainly, there are domains that require a complex and data-hungry analysis. But before assuming complexity, it is prudent to check the raw data looking for "short cuts" that simplify the whole analysis.