 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge500+ Times Faster Than Deep Learning (A Case Study Exploring Faster Methods for Text Mining StackOverflow)
Paper and Code
Feb 14, 2018


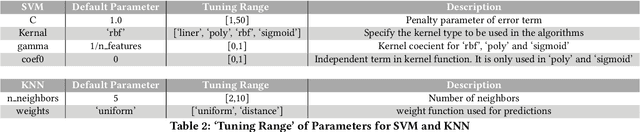
Deep learning methods are useful for high-dimensional data and are becoming widely used in many areas of software engineering. Deep learners utilizes extensive computational power and can take a long time to train-- making it difficult to widely validate and repeat and improve their results. Further, they are not the best solution in all domains. For example, recent results show that for finding related Stack Overflow posts, a tuned SVM performs similarly to a deep learner, but is significantly faster to train. This paper extends that recent result by clustering the dataset, then tuning very learners within each cluster. This approach is over 500 times faster than deep learning (and over 900 times faster if we use all the cores on a standard laptop computer). Significantly, this faster approach generates classifiers nearly as good (within 2\% F1 Score) as the much slower deep learning method. Hence we recommend this faster methods since it is much easier to reproduce and utilizes far fewer CPU resources. More generally, we recommend that before researchers release research results, that they compare their supposedly sophisticated methods against simpler alternatives (e.g applying simpler learners to build local models).