 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCausal Effect of Group Diversity on Redundancy and Coverage in Peer-Reviewing
Nov 18, 2024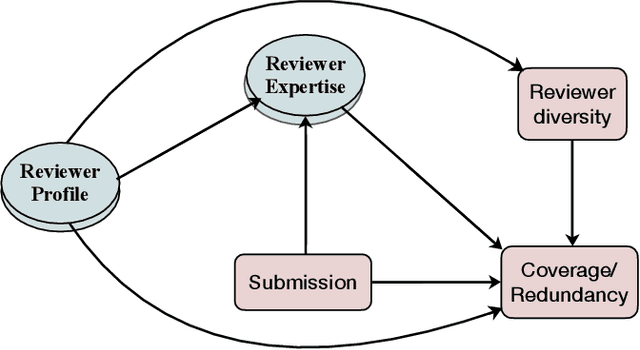

A large host of scientific journals and conferences solicit peer reviews from multiple reviewers for the same submission, aiming to gather a broader range of perspectives and mitigate individual biases. In this work, we reflect on the role of diversity in the slate of reviewers assigned to evaluate a submitted paper as a factor in diversifying perspectives and improving the utility of the peer-review process. We propose two measures for assessing review utility: review coverage -- reviews should cover most contents of the paper -- and review redundancy -- reviews should add information not already present in other reviews. We hypothesize that reviews from diverse reviewers will exhibit high coverage and low redundancy. We conduct a causal study of different measures of reviewer diversity on review coverage and redundancy using observational data from a peer-reviewed conference with approximately 5,000 submitted papers. Our study reveals disparate effects of different diversity measures on review coverage and redundancy. Our study finds that assigning a group of reviewers that are topically diverse, have different seniority levels, or have distinct publication networks leads to broader coverage of the paper or review criteria, but we find no evidence of an increase in coverage for reviewer slates with reviewers from diverse organizations or geographical locations. Reviewers from different organizations, seniority levels, topics, or publications networks (all except geographical diversity) lead to a decrease in redundancy in reviews. Furthermore, publication network-based diversity alone also helps bring in varying perspectives (that is, low redundancy), even within specific review criteria. Our study adopts a group decision-making perspective for reviewer assignments in peer review and suggests dimensions of diversity that can help guide the reviewer assignment process.
A Gold Standard Dataset for the Reviewer Assignment Problem
Mar 23, 2023Many peer-review venues are either using or looking to use algorithms to assign submissions to reviewers. The crux of such automated approaches is the notion of the "similarity score"--a numerical estimate of the expertise of a reviewer in reviewing a paper--and many algorithms have been proposed to compute these scores. However, these algorithms have not been subjected to a principled comparison, making it difficult for stakeholders to choose the algorithm in an evidence-based manner. The key challenge in comparing existing algorithms and developing better algorithms is the lack of the publicly available gold-standard data that would be needed to perform reproducible research. We address this challenge by collecting a novel dataset of similarity scores that we release to the research community. Our dataset consists of 477 self-reported expertise scores provided by 58 researchers who evaluated their expertise in reviewing papers they have read previously. We use this data to compare several popular algorithms employed in computer science conferences and come up with recommendations for stakeholders. Our main findings are as follows. First, all algorithms make a non-trivial amount of error. For the task of ordering two papers in terms of their relevance for a reviewer, the error rates range from 12%-30% in easy cases to 36%-43% in hard cases, highlighting the vital need for more research on the similarity-computation problem. Second, most existing algorithms are designed to work with titles and abstracts of papers, and in this regime the Specter+MFR algorithm performs best. Third, to improve performance, it may be important to develop modern deep-learning based algorithms that can make use of the full texts of papers: the classical TD-IDF algorithm enhanced with full texts of papers is on par with the deep-learning based Specter+MFR that cannot make use of this information.
How do Authors' Perceptions of their Papers Compare with Co-authors' Perceptions and Peer-review Decisions?
Nov 22, 2022



How do author perceptions match up to the outcomes of the peer-review process and perceptions of others? In a top-tier computer science conference (NeurIPS 2021) with more than 23,000 submitting authors and 9,000 submitted papers, we survey the authors on three questions: (i) their predicted probability of acceptance for each of their papers, (ii) their perceived ranking of their own papers based on scientific contribution, and (iii) the change in their perception about their own papers after seeing the reviews. The salient results are: (1) Authors have roughly a three-fold overestimate of the acceptance probability of their papers: The median prediction is 70% for an approximately 25% acceptance rate. (2) Female authors exhibit a marginally higher (statistically significant) miscalibration than male authors; predictions of authors invited to serve as meta-reviewers or reviewers are similarly calibrated, but better than authors who were not invited to review. (3) Authors' relative ranking of scientific contribution of two submissions they made generally agree (93%) with their predicted acceptance probabilities, but there is a notable 7% responses where authors think their better paper will face a worse outcome. (4) The author-provided rankings disagreed with the peer-review decisions about a third of the time; when co-authors ranked their jointly authored papers, co-authors disagreed at a similar rate -- about a third of the time. (5) At least 30% of respondents of both accepted and rejected papers said that their perception of their own paper improved after the review process. The stakeholders in peer review should take these findings into account in setting their expectations from peer review.
ASQA: Factoid Questions Meet Long-Form Answers
Apr 12, 2022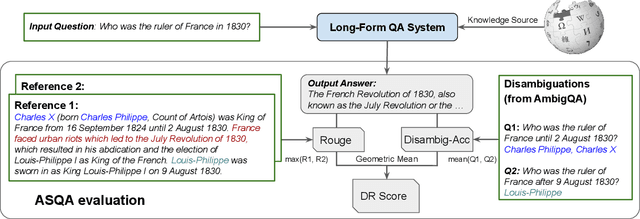

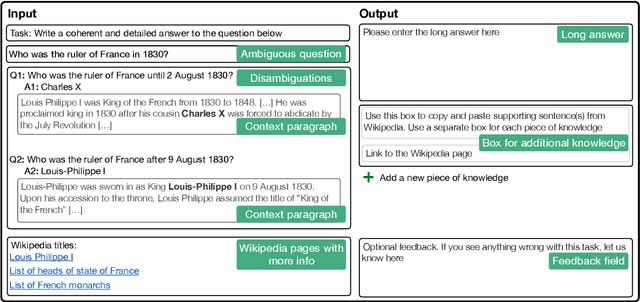
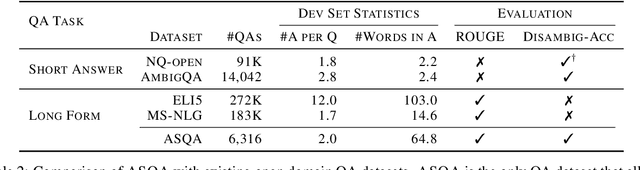
An abundance of datasets and availability of reliable evaluation metrics have resulted in strong progress in factoid question answering (QA). This progress, however, does not easily transfer to the task of long-form QA, where the goal is to answer questions that require in-depth explanations. The hurdles include (i) a lack of high-quality data, and (ii) the absence of a well-defined notion of the answer's quality. In this work, we address these problems by (i) releasing a novel dataset and a task that we call ASQA (Answer Summaries for Questions which are Ambiguous); and (ii) proposing a reliable metric for measuring performance on ASQA. Our task focuses on factoid questions that are ambiguous, that is, have different correct answers depending on interpretation. Answers to ambiguous questions should synthesize factual information from multiple sources into a long-form summary that resolves the ambiguity. In contrast to existing long-form QA tasks (such as ELI5), ASQA admits a clear notion of correctness: a user faced with a good summary should be able to answer different interpretations of the original ambiguous question. We use this notion of correctness to define an automated metric of performance for ASQA. Our analysis demonstrates an agreement between this metric and human judgments, and reveals a considerable gap between human performance and strong baselines.
Vox Populi, Vox DIY: Benchmark Dataset for Crowdsourced Audio Transcription
Jul 02, 2021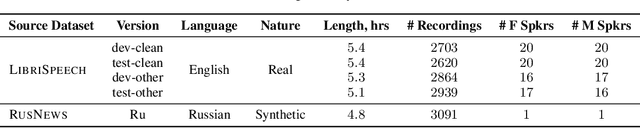
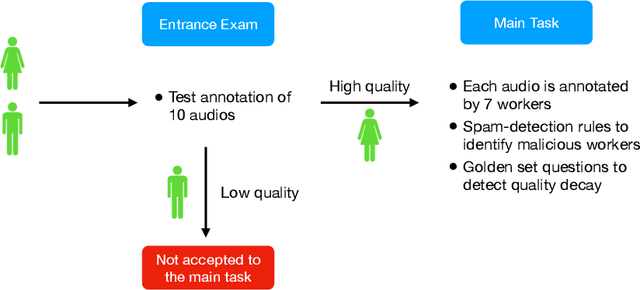
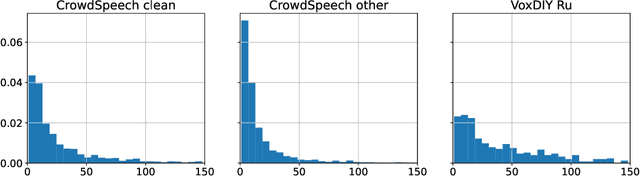
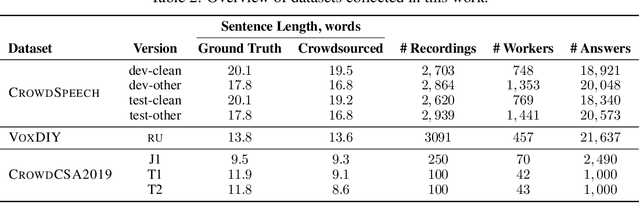
Domain-specific data is the crux of the successful transfer of machine learning systems from benchmarks to real life. Crowdsourcing has become one of the standard tools for cheap and time-efficient data collection for simple problems such as image classification: thanks in large part to advances in research on aggregation methods. However, the applicability of crowdsourcing to more complex tasks (e.g., speech recognition) remains limited due to the lack of principled aggregation methods for these modalities. The main obstacle towards designing advanced aggregation methods is the absence of training data, and in this work, we focus on bridging this gap in speech recognition. For this, we collect and release CrowdSpeech -- the first publicly available large-scale dataset of crowdsourced audio transcriptions. Evaluation of existing aggregation methods on our data shows room for improvement, suggesting that our work may entail the design of better algorithms. At a higher level, we also contribute to the more general challenge of collecting high-quality datasets using crowdsourcing: we develop a principled pipeline for constructing datasets of crowdsourced audio transcriptions in any novel domain. We show its applicability on an under-resourced language by constructing VoxDIY -- a counterpart of CrowdSpeech for the Russian language. We also release the code that allows a full replication of our data collection pipeline and share various insights on best practices of data collection via crowdsourcing.
Debiasing Evaluations That are Biased by Evaluations
Dec 01, 2020It is common to evaluate a set of items by soliciting people to rate them. For example, universities ask students to rate the teaching quality of their instructors, and conference organizers ask authors of submissions to evaluate the quality of the reviews. However, in these applications, students often give a higher rating to a course if they receive higher grades in a course, and authors often give a higher rating to the reviews if their papers are accepted to the conference. In this work, we call these external factors the "outcome" experienced by people, and consider the problem of mitigating these outcome-induced biases in the given ratings when some information about the outcome is available. We formulate the information about the outcome as a known partial ordering on the bias. We propose a debiasing method by solving a regularized optimization problem under this ordering constraint, and also provide a carefully designed cross-validation method that adaptively chooses the appropriate amount of regularization. We provide theoretical guarantees on the performance of our algorithm, as well as experimental evaluations.
A Large Scale Randomized Controlled Trial on Herding in Peer-Review Discussions
Nov 30, 2020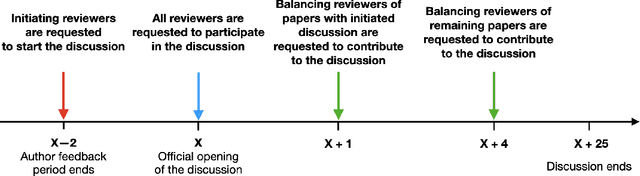


Peer review is the backbone of academia and humans constitute a cornerstone of this process, being responsible for reviewing papers and making the final acceptance/rejection decisions. Given that human decision making is known to be susceptible to various cognitive biases, it is important to understand which (if any) biases are present in the peer-review process and design the pipeline such that the impact of these biases is minimized. In this work, we focus on the dynamics of between-reviewers discussions and investigate the presence of herding behaviour therein. In that, we aim to understand whether reviewers and more senior decision makers get disproportionately influenced by the first argument presented in the discussion when (in case of reviewers) they form an independent opinion about the paper before discussing it with others. Specifically, in conjunction with the review process of ICML 2020 -- a large, top tier machine learning conference -- we design and execute a randomized controlled trial with the goal of testing for the conditional causal effect of the discussion initiator's opinion on the outcome of a paper.
A Novice-Reviewer Experiment to Address Scarcity of Qualified Reviewers in Large Conferences
Nov 30, 2020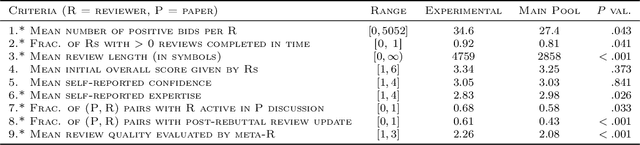
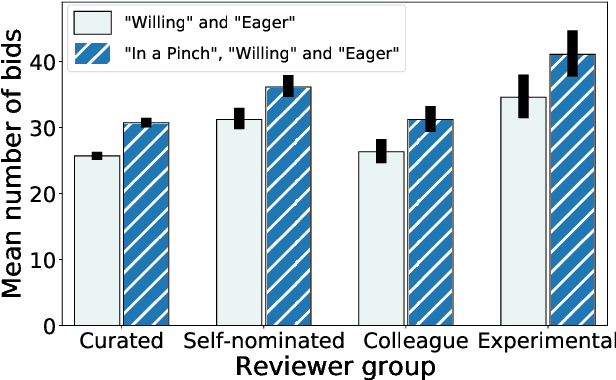
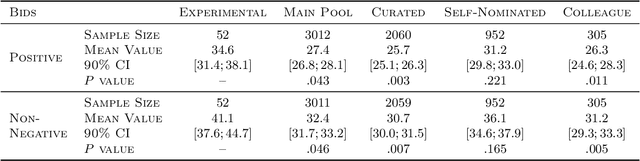
Conference peer review constitutes a human-computation process whose importance cannot be overstated: not only it identifies the best submissions for acceptance, but, ultimately, it impacts the future of the whole research area by promoting some ideas and restraining others. A surge in the number of submissions received by leading AI conferences has challenged the sustainability of the review process by increasing the burden on the pool of qualified reviewers which is growing at a much slower rate. In this work, we consider the problem of reviewer recruiting with a focus on the scarcity of qualified reviewers in large conferences. Specifically, we design a procedure for (i) recruiting reviewers from the population not typically covered by major conferences and (ii) guiding them through the reviewing pipeline. In conjunction with ICML 2020 -- a large, top-tier machine learning conference -- we recruit a small set of reviewers through our procedure and compare their performance with the general population of ICML reviewers. Our experiment reveals that a combination of the recruiting and guiding mechanisms allows for a principled enhancement of the reviewer pool and results in reviews of superior quality compared to the conventional pool of reviews as evaluated by senior members of the program committee (meta-reviewers).
Prior and Prejudice: The Novice Reviewers' Bias against Resubmissions in Conference Peer Review
Nov 30, 2020



Modern machine learning and computer science conferences are experiencing a surge in the number of submissions that challenges the quality of peer review as the number of competent reviewers is growing at a much slower rate. To curb this trend and reduce the burden on reviewers, several conferences have started encouraging or even requiring authors to declare the previous submission history of their papers. Such initiatives have been met with skepticism among authors, who raise the concern about a potential bias in reviewers' recommendations induced by this information. In this work, we investigate whether reviewers exhibit a bias caused by the knowledge that the submission under review was previously rejected at a similar venue, focusing on a population of novice reviewers who constitute a large fraction of the reviewer pool in leading machine learning and computer science conferences. We design and conduct a randomized controlled trial closely replicating the relevant components of the peer-review pipeline with $133$ reviewers (master's, junior PhD students, and recent graduates of top US universities) writing reviews for $19$ papers. The analysis reveals that reviewers indeed become negatively biased when they receive a signal about paper being a resubmission, giving almost 1 point lower overall score on a 10-point Likert item ($\Delta = -0.78, \ 95\% \ \text{CI} = [-1.30, -0.24]$) than reviewers who do not receive such a signal. Looking at specific criteria scores (originality, quality, clarity and significance), we observe that novice reviewers tend to underrate quality the most.
Catch Me if I Can: Detecting Strategic Behaviour in Peer Assessment
Oct 08, 2020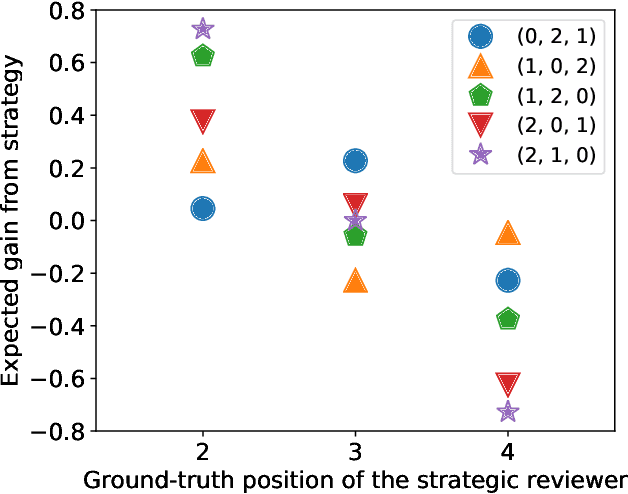
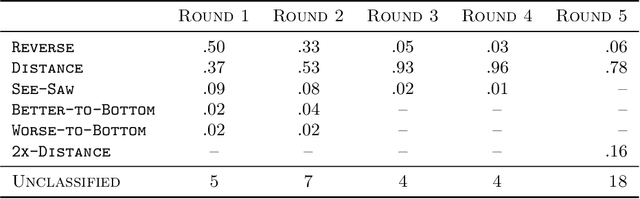


We consider the issue of strategic behaviour in various peer-assessment tasks, including peer grading of exams or homeworks and peer review in hiring or promotions. When a peer-assessment task is competitive (e.g., when students are graded on a curve), agents may be incentivized to misreport evaluations in order to improve their own final standing. Our focus is on designing methods for detection of such manipulations. Specifically, we consider a setting in which agents evaluate a subset of their peers and output rankings that are later aggregated to form a final ordering. In this paper, we investigate a statistical framework for this problem and design a principled test for detecting strategic behaviour. We prove that our test has strong false alarm guarantees and evaluate its detection ability in practical settings. For this, we design and execute an experiment that elicits strategic behaviour from subjects and release a dataset of patterns of strategic behaviour that may be of independent interest. We then use the collected data to conduct a series of real and semi-synthetic evaluations that demonstrate a strong detection power of our test.