 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMellum2 Technical Report
May 29, 2026We present Mellum 2, an open-weight 12B-parameter Mixture-of-Experts (MoE) language model with 2.5B active parameters per token. Mellum 2 is a general-purpose language model specialized in software engineering, spanning code generation and editing, debugging, multi-step reasoning, tool use and function calling, agentic coding, and conversational programming assistance, and it is the successor to the completion-focused 4B dense Mellum model. The architecture builds on the Mixture-of-Experts (64 experts, 8 active) and combines Grouped-Query Attention with 4 KV heads, Sliding Window Attention on three of every four layers, and a single Multi-Token Prediction head that doubles as both an auxiliary pre-training objective and a built-in draft model for speculative decoding; each choice was validated by ablation with inference efficiency on commodity GPUs as a design constraint. Pre-training spans approximately 10.6 trillion tokens through a three-phase curriculum that progressively shifts the mixture from diverse web data toward curated code and mathematical content, optimized with Muon under FP8 hybrid precision and a Warmup-Hold-Decay schedule with linear decay to zero. The pre-trained base is extended to a 128K context window via a layer-selective YaRN and then post-trained in two stages (supervised fine-tuning followed by RLVR), yielding two released variants: an Instruct model that answers directly and a Thinking model that emits an explicit reasoning trace before its final answer. Across code generation, math and reasoning, tool use, knowledge, and safety benchmarks, Mellum 2 is competitive with open-weight baselines in the 4B-14B range while running at the per-token compute of a 2.5B dense model. We release the base, instruct, and thinking checkpoints, together with this report on the architecture decisions, data pipeline, and training recipe behind them, under the Apache 2.0 license.
Toloka Visual Question Answering Benchmark
Sep 28, 2023In this paper, we present Toloka Visual Question Answering, a new crowdsourced dataset allowing comparing performance of machine learning systems against human level of expertise in the grounding visual question answering task. In this task, given an image and a textual question, one has to draw the bounding box around the object correctly responding to that question. Every image-question pair contains the response, with only one correct response per image. Our dataset contains 45,199 pairs of images and questions in English, provided with ground truth bounding boxes, split into train and two test subsets. Besides describing the dataset and releasing it under a CC BY license, we conducted a series of experiments on open source zero-shot baseline models and organized a multi-phase competition at WSDM Cup that attracted 48 participants worldwide. However, by the time of paper submission, no machine learning model outperformed the non-expert crowdsourcing baseline according to the intersection over union evaluation score.
Best Prompts for Text-to-Image Models and How to Find Them
Sep 23, 2022

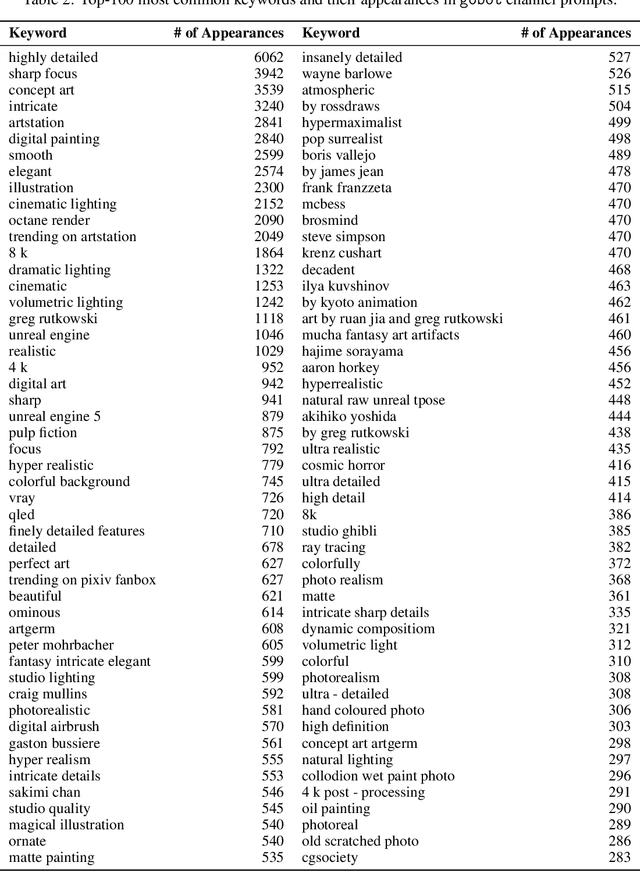

Recent progress in generative models, especially in text-guided diffusion models, has enabled the production of aesthetically-pleasing imagery resembling the works of professional human artists. However, one has to carefully compose the textual description, called the prompt, and augment it with a set of clarifying keywords. Since aesthetics are challenging to evaluate computationally, human feedback is needed to determine the optimal prompt formulation and keyword combination. In this paper, we present a human-in-the-loop approach to learning the most useful combination of prompt keywords using a genetic algorithm. We also show how such an approach can improve the aesthetic appeal of images depicting the same descriptions.
Vox Populi, Vox DIY: Benchmark Dataset for Crowdsourced Audio Transcription
Jul 02, 2021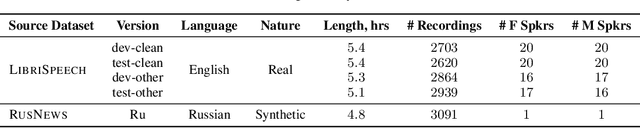
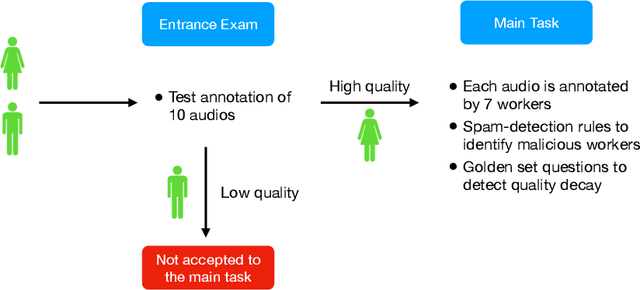
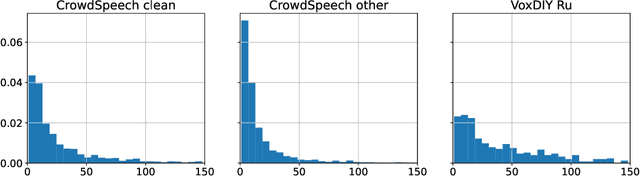
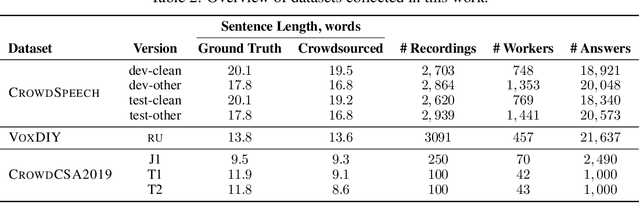
Domain-specific data is the crux of the successful transfer of machine learning systems from benchmarks to real life. Crowdsourcing has become one of the standard tools for cheap and time-efficient data collection for simple problems such as image classification: thanks in large part to advances in research on aggregation methods. However, the applicability of crowdsourcing to more complex tasks (e.g., speech recognition) remains limited due to the lack of principled aggregation methods for these modalities. The main obstacle towards designing advanced aggregation methods is the absence of training data, and in this work, we focus on bridging this gap in speech recognition. For this, we collect and release CrowdSpeech -- the first publicly available large-scale dataset of crowdsourced audio transcriptions. Evaluation of existing aggregation methods on our data shows room for improvement, suggesting that our work may entail the design of better algorithms. At a higher level, we also contribute to the more general challenge of collecting high-quality datasets using crowdsourcing: we develop a principled pipeline for constructing datasets of crowdsourced audio transcriptions in any novel domain. We show its applicability on an under-resourced language by constructing VoxDIY -- a counterpart of CrowdSpeech for the Russian language. We also release the code that allows a full replication of our data collection pipeline and share various insights on best practices of data collection via crowdsourcing.
Spherical convolutions on molecular graphs for protein model quality assessment
Nov 16, 2020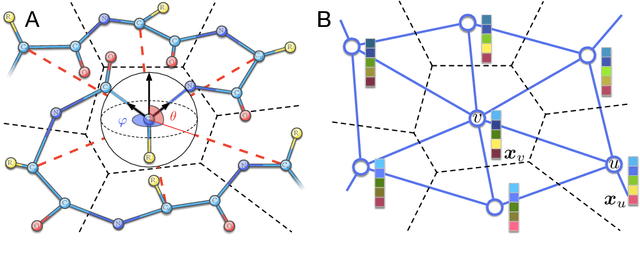
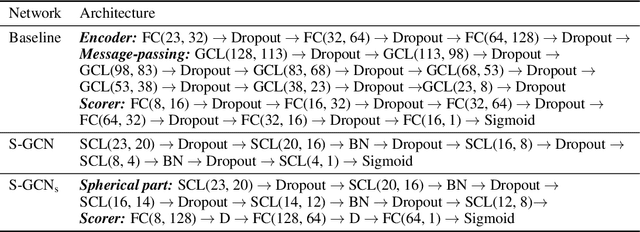


Processing information on 3D objects requires methods stable to rigid-body transformations, in particular rotations, of the input data. In image processing tasks, convolutional neural networks achieve this property using rotation-equivariant operations. However, contrary to images, graphs generally have irregular topology. This makes it challenging to define a rotation-equivariant convolution operation on these structures. In this work, we propose Spherical Graph Convolutional Network (S-GCN) that processes 3D models of proteins represented as molecular graphs. In a protein molecule, individual amino acids have common topological elements. This allows us to unambiguously associate each amino acid with a local coordinate system and construct rotation-equivariant spherical filters that operate on angular information between graph nodes. Within the framework of the protein model quality assessment problem, we demonstrate that the proposed spherical convolution method significantly improves the quality of model assessment compared to the standard message-passing approach. It is also comparable to state-of-the-art methods, as we demonstrate on Critical Assessment of Structure Prediction (CASP) benchmarks. The proposed technique operates only on geometric features of protein 3D models. This makes it universal and applicable to any other geometric-learning task where the graph structure allows constructing local coordinate systems.