 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchical Loss And Geometric Mask Refinement For Multilabel Ribs Segmentation
May 24, 2024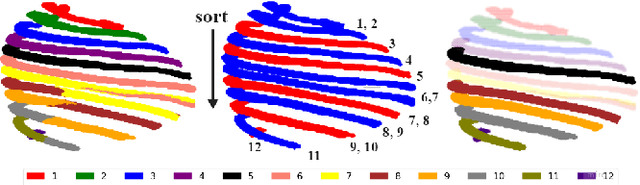
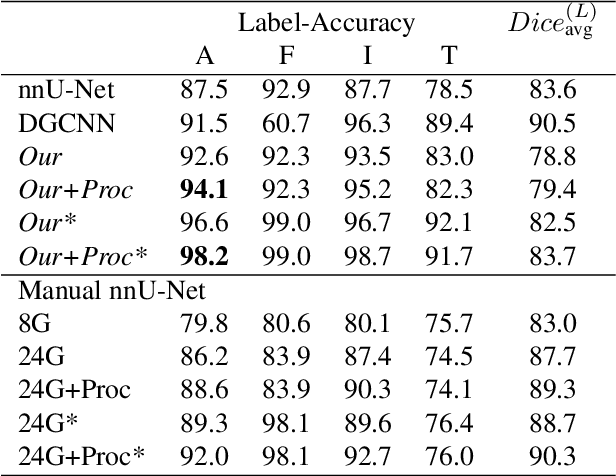
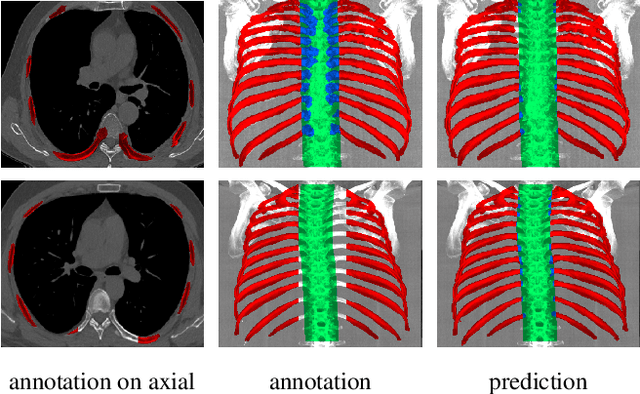

Automatic ribs segmentation and numeration can increase computed tomography assessment speed and reduce radiologists mistakes. We introduce a model for multilabel ribs segmentation with hierarchical loss function, which enable to improve multilabel segmentation quality. Also we propose postprocessing technique to further increase labeling quality. Our model achieved new state-of-the-art 98.2% label accuracy on public RibSeg v2 dataset, surpassing previous result by 6.7%.
Neural Machine Translation for Malayalam Paraphrase Generation
Jan 31, 2024This study explores four methods of generating paraphrases in Malayalam, utilizing resources available for English paraphrasing and pre-trained Neural Machine Translation (NMT) models. We evaluate the resulting paraphrases using both automated metrics, such as BLEU, METEOR, and cosine similarity, as well as human annotation. Our findings suggest that automated evaluation measures may not be fully appropriate for Malayalam, as they do not consistently align with human judgment. This discrepancy underscores the need for more nuanced paraphrase evaluation approaches especially for highly agglutinative languages.
Toloka Visual Question Answering Benchmark
Sep 28, 2023In this paper, we present Toloka Visual Question Answering, a new crowdsourced dataset allowing comparing performance of machine learning systems against human level of expertise in the grounding visual question answering task. In this task, given an image and a textual question, one has to draw the bounding box around the object correctly responding to that question. Every image-question pair contains the response, with only one correct response per image. Our dataset contains 45,199 pairs of images and questions in English, provided with ground truth bounding boxes, split into train and two test subsets. Besides describing the dataset and releasing it under a CC BY license, we conducted a series of experiments on open source zero-shot baseline models and organized a multi-phase competition at WSDM Cup that attracted 48 participants worldwide. However, by the time of paper submission, no machine learning model outperformed the non-expert crowdsourcing baseline according to the intersection over union evaluation score.