 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToloka Visual Question Answering Benchmark
Sep 28, 2023In this paper, we present Toloka Visual Question Answering, a new crowdsourced dataset allowing comparing performance of machine learning systems against human level of expertise in the grounding visual question answering task. In this task, given an image and a textual question, one has to draw the bounding box around the object correctly responding to that question. Every image-question pair contains the response, with only one correct response per image. Our dataset contains 45,199 pairs of images and questions in English, provided with ground truth bounding boxes, split into train and two test subsets. Besides describing the dataset and releasing it under a CC BY license, we conducted a series of experiments on open source zero-shot baseline models and organized a multi-phase competition at WSDM Cup that attracted 48 participants worldwide. However, by the time of paper submission, no machine learning model outperformed the non-expert crowdsourcing baseline according to the intersection over union evaluation score.
Clustering Without Knowing How To: Application and Evaluation
Sep 21, 2022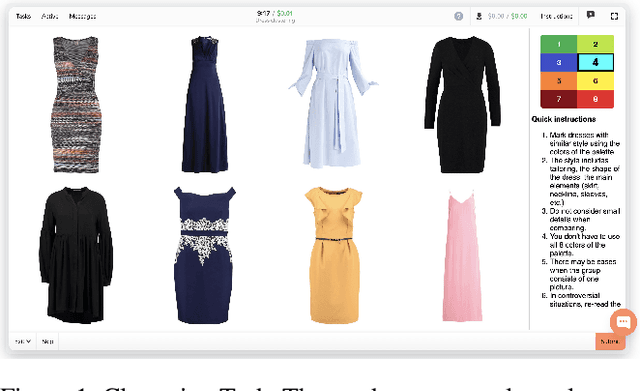
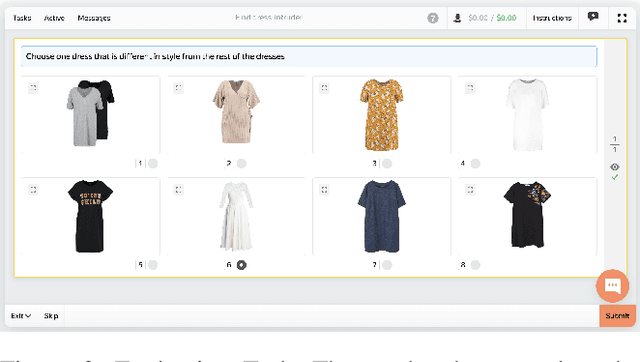
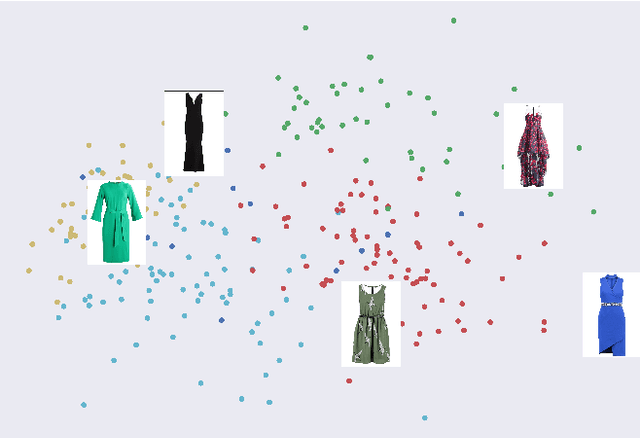
Crowdsourcing allows running simple human intelligence tasks on a large crowd of workers, enabling solving problems for which it is difficult to formulate an algorithm or train a machine learning model in reasonable time. One of such problems is data clustering by an under-specified criterion that is simple for humans, but difficult for machines. In this demonstration paper, we build a crowdsourced system for image clustering and release its code under a free license at https://github.com/Toloka/crowdclustering. Our experiments on two different image datasets, dresses from Zalando's FEIDEGGER and shoes from the Toloka Shoes Dataset, confirm that one can yield meaningful clusters with no machine learning algorithms purely with crowdsourcing.