 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVariance Reduction in Deep Learning: More Momentum is All You Need
Paper and Code
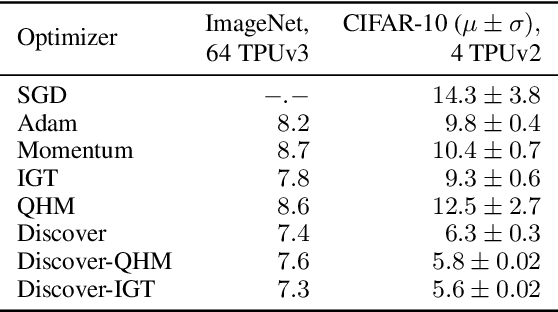
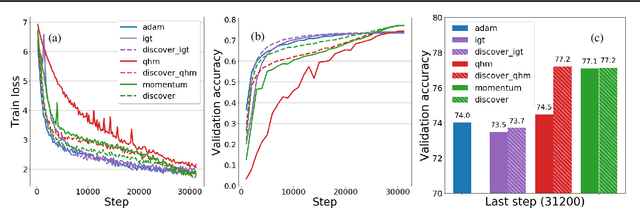
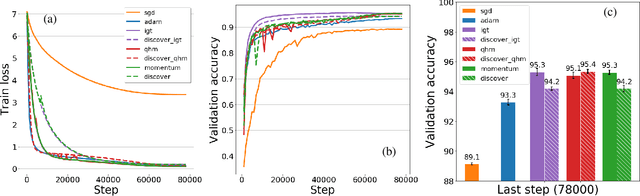
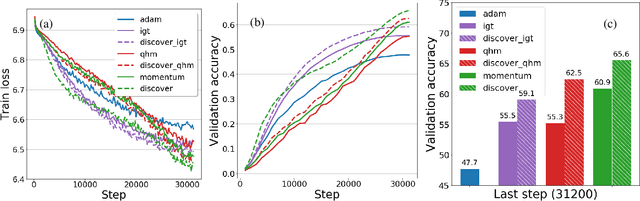
Variance reduction (VR) techniques have contributed significantly to accelerating learning with massive datasets in the smooth and strongly convex setting (Schmidt et al., 2017; Johnson & Zhang, 2013; Roux et al., 2012). However, such techniques have not yet met the same success in the realm of large-scale deep learning due to various factors such as the use of data augmentation or regularization methods like dropout (Defazio & Bottou, 2019). This challenge has recently motivated the design of novel variance reduction techniques tailored explicitly for deep learning (Arnold et al., 2019; Ma & Yarats, 2018). This work is an additional step in this direction. In particular, we exploit the ubiquitous clustering structure of rich datasets used in deep learning to design a family of scalable variance reduced optimization procedures by combining existing optimizers (e.g., SGD+Momentum, Quasi Hyperbolic Momentum, Implicit Gradient Transport) with a multi-momentum strategy (Yuan et al., 2019). Our proposal leads to faster convergence than vanilla methods on standard benchmark datasets (e.g., CIFAR and ImageNet). It is robust to label noise and amenable to distributed optimization. We provide a parallel implementation in JAX.