 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData-Driven Reachability analysis and Support set Estimation with Christoffel Functions
Dec 18, 2021
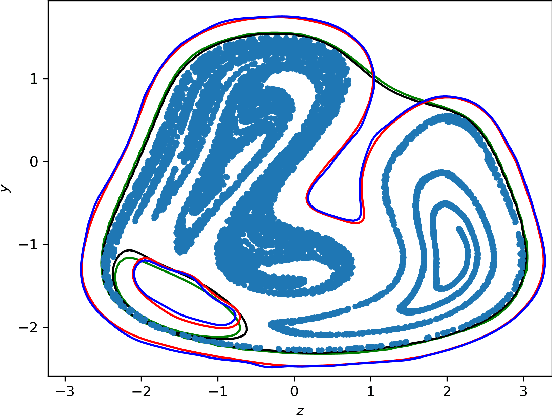
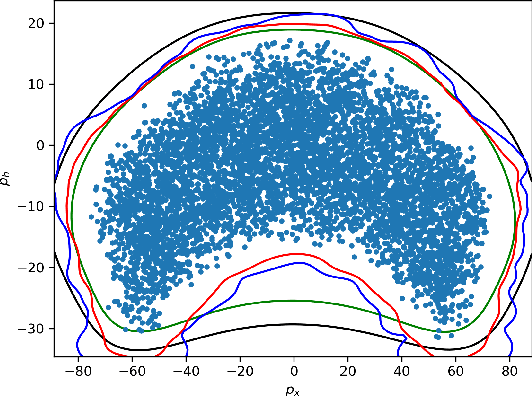
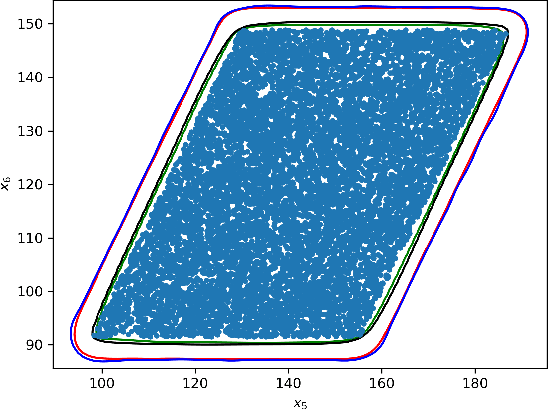
We present algorithms for estimating the forward reachable set of a dynamical system using only a finite collection of independent and identically distributed samples. The produced estimate is the sublevel set of a function called an empirical inverse Christoffel function: empirical inverse Christoffel functions are known to provide good approximations to the support of probability distributions. In addition to reachability analysis, the same approach can be applied to general problems of estimating the support of a random variable, which has applications in data science towards detection of novelties and outliers in data sets. In applications where safety is a concern, having a guarantee of accuracy that holds on finite data sets is critical. In this paper, we prove such bounds for our algorithms under the Probably Approximately Correct (PAC) framework. In addition to applying classical Vapnik-Chervonenkis (VC) dimension bound arguments, we apply the PAC-Bayes theorem by leveraging a formal connection between kernelized empirical inverse Christoffel functions and Gaussian process regression models. The bound based on PAC-Bayes applies to a more general class of Christoffel functions than the VC dimension argument, and achieves greater sample efficiency in experiments.
Fairness with Overlapping Groups
Jun 24, 2020
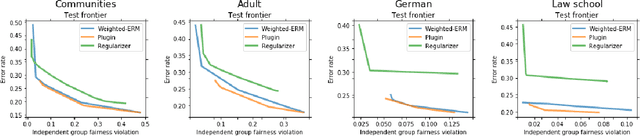

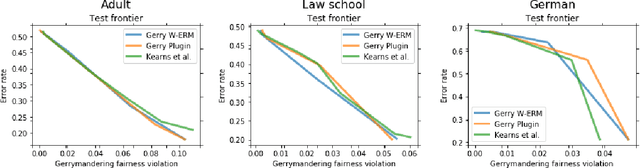
In algorithmically fair prediction problems, a standard goal is to ensure the equality of fairness metrics across multiple overlapping groups simultaneously. We reconsider this standard fair classification problem using a probabilistic population analysis, which, in turn, reveals the Bayes-optimal classifier. Our approach unifies a variety of existing group-fair classification methods and enables extensions to a wide range of non-decomposable multiclass performance metrics and fairness measures. The Bayes-optimal classifier further inspires consistent procedures for algorithmically fair classification with overlapping groups. On a variety of real datasets, the proposed approach outperforms baselines in terms of its fairness-performance tradeoff.
On the Consistency of Top-k Surrogate Losses
Jan 30, 2019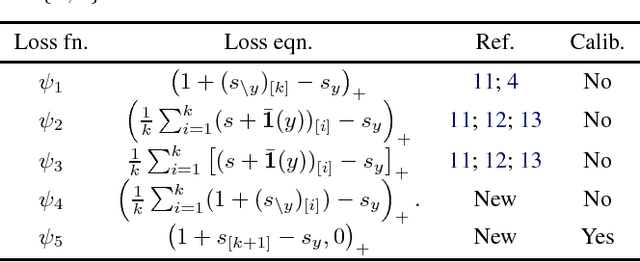

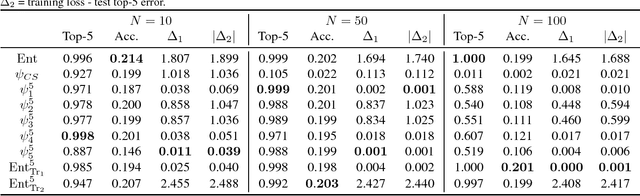
The top-$k$ error is often employed to evaluate performance for challenging classification tasks in computer vision as it is designed to compensate for ambiguity in ground truth labels. This practical success motivates our theoretical analysis of consistent top-$k$ classification. To this end, we define top-$k$ calibration as a necessary and sufficient condition for consistency, for bounded below loss functions. Unlike prior work, our analysis of top-$k$ calibration handles non-uniqueness of the predictor scores, and extends calibration to consistency -- providing a theoretically sound basis for analysis of this topic. Based on the top-$k$ calibration analysis, we propose a rich class of top-$k$ calibrated Bregman divergence surrogates. Our analysis continues by showing previously proposed hinge-like top-$k$ surrogate losses are not top-$k$ calibrated and thus inconsistent. On the other hand, we propose two new hinge-like losses, one which is similarly inconsistent, and one which is consistent. Our empirical results highlight theoretical claims, confirming our analysis of the consistency of these losses.
Kernel-based Outlier Detection using the Inverse Christoffel Function
Jun 18, 2018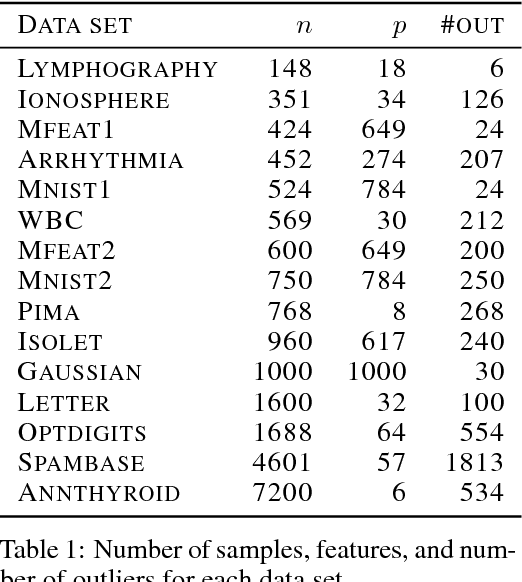
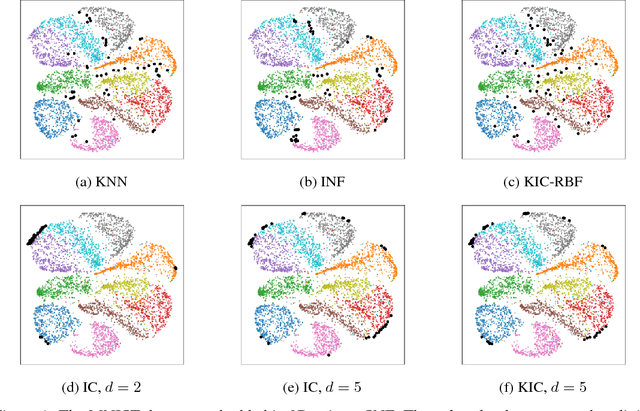
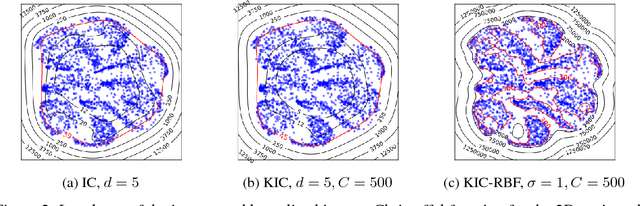
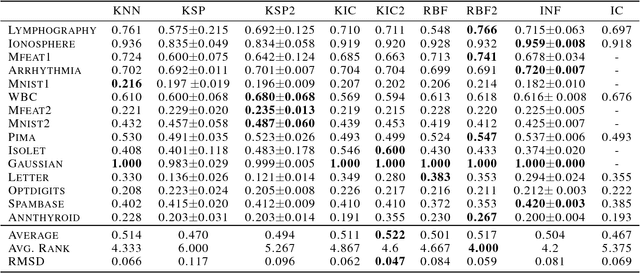
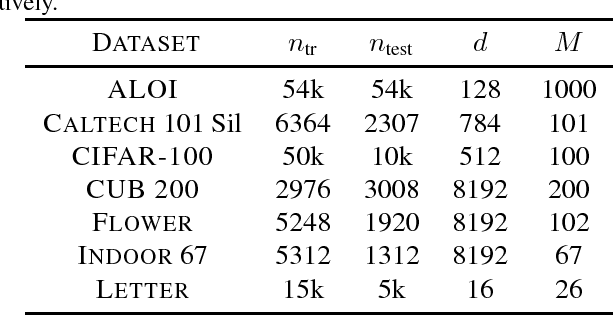
Outlier detection methods have become increasingly relevant in recent years due to increased security concerns and because of its vast application to different fields. Recently, Pauwels and Lasserre (2016) noticed that the sublevel sets of the inverse Christoffel function accurately depict the shape of a cloud of data using a sum-of-squares polynomial and can be used to perform outlier detection. In this work, we propose a kernelized variant of the inverse Christoffel function that makes it computationally tractable for data sets with a large number of features. We compare our approach to current methods on 15 different data sets and achieve the best average area under the precision recall curve (AUPRC) score, the best average rank and the lowest root mean square deviation.