 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynFi: Automatic Synthetic Fingerprint Generation
Feb 16, 2020



Authentication and identification methods based on human fingerprints are ubiquitous in several systems ranging from government organizations to consumer products. The performance and reliability of such systems directly rely on the volume of data on which they have been verified. Unfortunately, a large volume of fingerprint databases is not publicly available due to many privacy and security concerns. In this paper, we introduce a new approach to automatically generate high-fidelity synthetic fingerprints at scale. Our approach relies on (i) Generative Adversarial Networks to estimate the probability distribution of human fingerprints and (ii) Super-Resolution methods to synthesize fine-grained textures. We rigorously test our system and show that our methodology is the first to generate fingerprints that are computationally indistinguishable from real ones, a task that prior art could not accomplish.
HEAX: High-Performance Architecture for Computation on Homomorphically Encrypted Data in the Cloud
Sep 20, 2019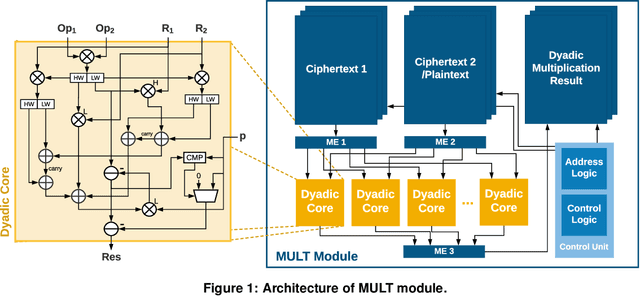
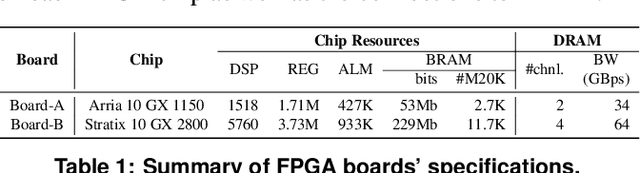
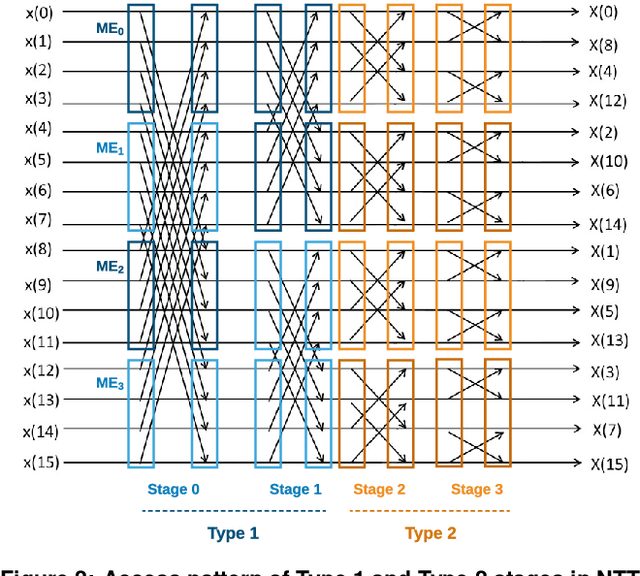

With the rapid increase in cloud computing, concerns surrounding data privacy, security, and confidentiality also have been increased significantly. Not only cloud providers are susceptible to internal and external hacks, but also in some scenarios, data owners cannot outsource the computation due to privacy laws such as GDPR, HIPAA, or CCPA. Fully Homomorphic Encryption (FHE) is a groundbreaking invention in cryptography that, unlike traditional cryptosystems, enables computation on encrypted data without ever decrypting it. However, the most critical obstacle in deploying FHE at large-scale is the enormous computation overhead. In this paper, we present HEAX, a novel hardware architecture for FHE that achieves unprecedented performance improvement. HEAX leverages multiple levels of parallelism, ranging from ciphertext-level to fine-grained modular arithmetic level. Our first contribution is a new highly-parallelizable architecture for number-theoretic transform (NTT) which can be of independent interest as NTT is frequently used in many lattice-based cryptography systems. Building on top of NTT engine, we design a novel architecture for computation on homomorphically encrypted data. We also introduce several techniques to enable an end-to-end, fully pipelined design as well as reducing on-chip memory consumption. Our implementation on reconfigurable hardware demonstrates 164-268x performance improvement for a wide range of FHE parameters.
SANNS: Scaling Up Secure Approximate k-Nearest Neighbors Search
Apr 03, 2019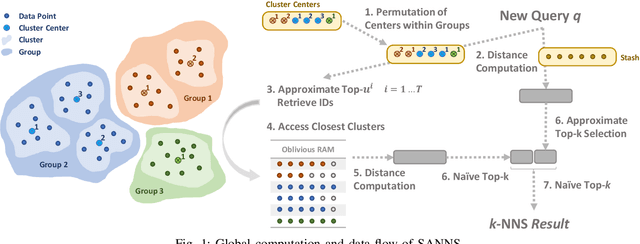
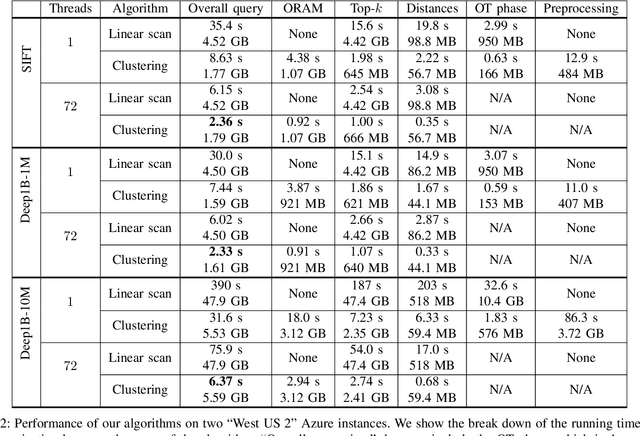

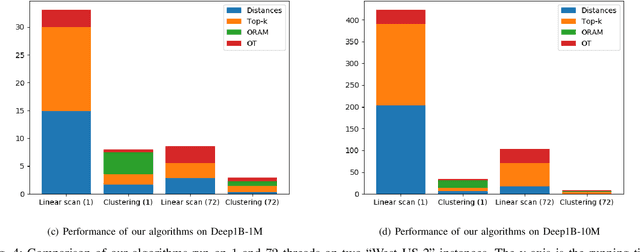
We present new secure protocols for approximate $k$-nearest neighbor search ($k$-NNS) over the Euclidean distance in the semi-honest model. Our implementation is able to handle massive datasets efficiently. On the algorithmic front, we show a new circuit for the approximate top-$k$ selection from $n$ numbers that is built from merely $O(n + \mathrm{poly}(k))$ comparators. Using this circuit as a subroutine, we design new approximate $k$-NNS algorithms and two corresponding secure protocols: 1) optimized linear scan; 2) clustering-based sublinear time algorithm. Our secure protocols utilize a combination of additively-homomorphic encryption, garbled circuit and Oblivious RAM. Along the way, we introduce various optimizations to these primitives, which drastically improve concrete efficiency. We evaluate the new protocols empirically and show that they are able to handle datasets that are significantly larger than in the prior work. For instance, running on two standard Azure instances within the same availability zone, for a dataset of $96$-dimensional descriptors of $10\,000\,000$ images, we can find $10$ nearest neighbors with average accuracy $0.9$ in under $10$ seconds improving upon prior work by at least two orders of magnitude.
Chameleon: A Hybrid Secure Computation Framework for Machine Learning Applications
Jan 10, 2018
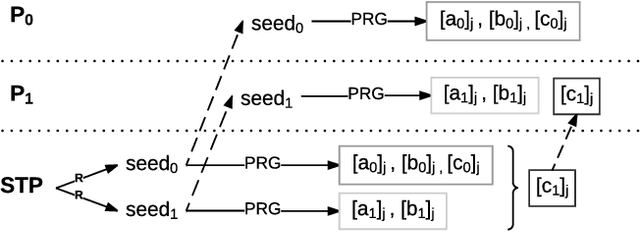

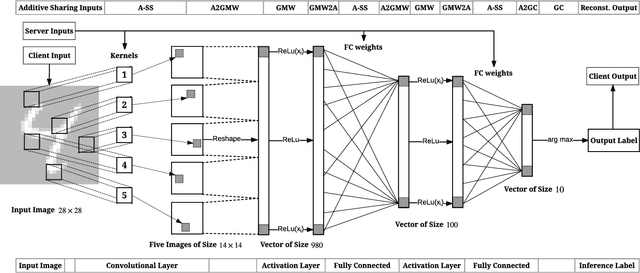
We present Chameleon, a novel hybrid (mixed-protocol) framework for secure function evaluation (SFE) which enables two parties to jointly compute a function without disclosing their private inputs. Chameleon combines the best aspects of generic SFE protocols with the ones that are based upon additive secret sharing. In particular, the framework performs linear operations in the ring $\mathbb{Z}_{2^l}$ using additively secret shared values and nonlinear operations using Yao's Garbled Circuits or the Goldreich-Micali-Wigderson protocol. Chameleon departs from the common assumption of additive or linear secret sharing models where three or more parties need to communicate in the online phase: the framework allows two parties with private inputs to communicate in the online phase under the assumption of a third node generating correlated randomness in an offline phase. Almost all of the heavy cryptographic operations are precomputed in an offline phase which substantially reduces the communication overhead. Chameleon is both scalable and significantly more efficient than the ABY framework (NDSS'15) it is based on. Our framework supports signed fixed-point numbers. In particular, Chameleon's vector dot product of signed fixed-point numbers improves the efficiency of mining and classification of encrypted data for algorithms based upon heavy matrix multiplications. Our evaluation of Chameleon on a 5 layer convolutional deep neural network shows 133x and 4.2x faster executions than Microsoft CryptoNets (ICML'16) and MiniONN (CCS'17), respectively.