 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDifferentially Private Synthetic Data via Foundation Model APIs 1: Images
Paper and Code


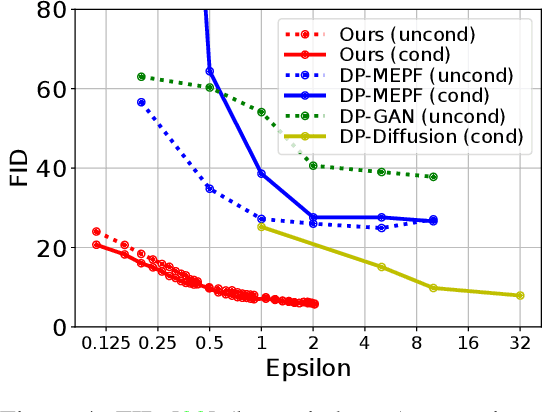

Generating differentially private (DP) synthetic data that closely resembles the original private data without leaking sensitive user information is a scalable way to mitigate privacy concerns in the current data-driven world. In contrast to current practices that train customized models for this task, we aim to generate DP Synthetic Data via APIs (DPSDA), where we treat foundation models as blackboxes and only utilize their inference APIs. Such API-based, training-free approaches are easier to deploy as exemplified by the recent surge in the number of API-based apps. These approaches can also leverage the power of large foundation models which are accessible via their inference APIs while the model weights are unreleased. However, this comes with greater challenges due to strictly more restrictive model access and the additional need to protect privacy from the API provider. In this paper, we present a new framework called Private Evolution (PE) to solve this problem and show its initial promise on synthetic images. Surprisingly, PE can match or even outperform state-of-the-art (SOTA) methods without any model training. For example, on CIFAR10 (with ImageNet as the public data), we achieve FID<=7.9 with privacy cost epsilon=0.67, significantly improving the previous SOTA from epsilon=32. We further demonstrate the promise of applying PE on large foundation models such as Stable Diffusion to tackle challenging private datasets with a small number of high-resolution images.