 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDifferentially Private Set Union
Feb 22, 2020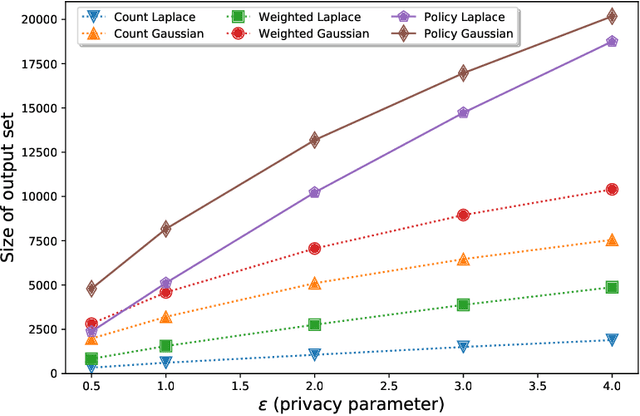



We study the basic operation of set union in the global model of differential privacy. In this problem, we are given a universe $U$ of items, possibly of infinite size, and a database $D$ of users. Each user $i$ contributes a subset $W_i \subseteq U$ of items. We want an ($\epsilon$,$\delta$)-differentially private algorithm which outputs a subset $S \subset \cup_i W_i$ such that the size of $S$ is as large as possible. The problem arises in countless real world applications; it is particularly ubiquitous in natural language processing (NLP) applications as vocabulary extraction. For example, discovering words, sentences, $n$-grams etc., from private text data belonging to users is an instance of the set union problem. Known algorithms for this problem proceed by collecting a subset of items from each user, taking the union of such subsets, and disclosing the items whose noisy counts fall above a certain threshold. Crucially, in the above process, the contribution of each individual user is always independent of the items held by other users, resulting in a wasteful aggregation process, where some item counts happen to be way above the threshold. We deviate from the above paradigm by allowing users to contribute their items in a $\textit{dependent fashion}$, guided by a $\textit{policy}$. In this new setting ensuring privacy is significantly delicate. We prove that any policy which has certain $\textit{contractive}$ properties would result in a differentially private algorithm. We design two new algorithms, one using Laplace noise and other Gaussian noise, as specific instances of policies satisfying the contractive properties. Our experiments show that the new algorithms significantly outperform previously known mechanisms for the problem.