 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEditCrafter: Tuning-free High-Resolution Image Editing via Pretrained Diffusion Model
Apr 11, 2026We propose EditCrafter, a high-resolution image editing method that operates without tuning, leveraging pretrained text-to-image (T2I) diffusion models to process images at resolutions significantly exceeding those used during training. Leveraging the generative priors of large-scale T2I diffusion models enables the development of a wide array of novel generation and editing applications. Although numerous image editing methods have been proposed based on diffusion models and exhibit high-quality editing results, they are difficult to apply to images with arbitrary aspect ratios or higher resolutions since they only work at the training resolutions (512x512 or 1024x1024). Naively applying patch-wise editing fails with unrealistic object structures and repetition. To address these challenges, we introduce EditCrafter, a simple yet effective editing pipeline. EditCrafter operates by first performing tiled inversion, which preserves the original identity of the input high-resolution image. We further propose a noise-damped manifold-constrained classifier-free guidance (NDCFG++) that is tailored for high resolution image editing from the inverted latent. Our experiments show that the our EditCrafter can achieve impressive editing results across various resolutions without fine-tuning and optimization.
Fine-tuning Small Language Models as Efficient Enterprise Search Relevance Labelers
Jan 06, 2026In enterprise search, building high-quality datasets at scale remains a central challenge due to the difficulty of acquiring labeled data. To resolve this challenge, we propose an efficient approach to fine-tune small language models (SLMs) for accurate relevance labeling, enabling high-throughput, domain-specific labeling comparable or even better in quality to that of state-of-the-art large language models (LLMs). To overcome the lack of high-quality and accessible datasets in the enterprise domain, our method leverages on synthetic data generation. Specifically, we employ an LLM to synthesize realistic enterprise queries from a seed document, apply BM25 to retrieve hard negatives, and use a teacher LLM to assign relevance scores. The resulting dataset is then distilled into an SLM, producing a compact relevance labeler. We evaluate our approach on a high-quality benchmark consisting of 923 enterprise query-document pairs annotated by trained human annotators, and show that the distilled SLM achieves agreement with human judgments on par with or better than the teacher LLM. Furthermore, our fine-tuned labeler substantially improves throughput, achieving 17 times increase while also being 19 times more cost-effective. This approach enables scalable and cost-effective relevance labeling for enterprise-scale retrieval applications, supporting rapid offline evaluation and iteration in real-world settings.
As-Plausible-As-Possible: Plausibility-Aware Mesh Deformation Using 2D Diffusion Priors
Nov 28, 2023



We present As-Plausible-as-Possible (APAP) mesh deformation technique that leverages 2D diffusion priors to preserve the plausibility of a mesh under user-controlled deformation. Our framework uses per-face Jacobians to represent mesh deformations, where mesh vertex coordinates are computed via a differentiable Poisson Solve. The deformed mesh is rendered, and the resulting 2D image is used in the Score Distillation Sampling (SDS) process, which enables extracting meaningful plausibility priors from a pretrained 2D diffusion model. To better preserve the identity of the edited mesh, we fine-tune our 2D diffusion model with LoRA. Gradients extracted by SDS and a user-prescribed handle displacement are then backpropagated to the per-face Jacobians, and we use iterative gradient descent to compute the final deformation that balances between the user edit and the output plausibility. We evaluate our method with 2D and 3D meshes and demonstrate qualitative and quantitative improvements when using plausibility priors over geometry-preservation or distortion-minimization priors used by previous techniques.
SyncDiffusion: Coherent Montage via Synchronized Joint Diffusions
Jun 08, 2023



The remarkable capabilities of pretrained image diffusion models have been utilized not only for generating fixed-size images but also for creating panoramas. However, naive stitching of multiple images often results in visible seams. Recent techniques have attempted to address this issue by performing joint diffusions in multiple windows and averaging latent features in overlapping regions. However, these approaches, which focus on seamless montage generation, often yield incoherent outputs by blending different scenes within a single image. To overcome this limitation, we propose SyncDiffusion, a plug-and-play module that synchronizes multiple diffusions through gradient descent from a perceptual similarity loss. Specifically, we compute the gradient of the perceptual loss using the predicted denoised images at each denoising step, providing meaningful guidance for achieving coherent montages. Our experimental results demonstrate that our method produces significantly more coherent outputs compared to previous methods (66.35% vs. 33.65% in our user study) while still maintaining fidelity (as assessed by GIQA) and compatibility with the input prompt (as measured by CLIP score).
Differentially Private n-gram Extraction
Aug 05, 2021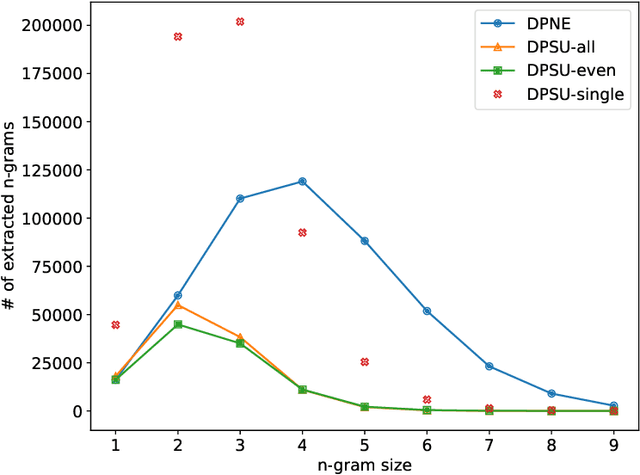


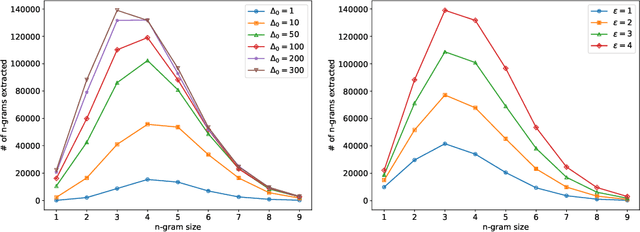
We revisit the problem of $n$-gram extraction in the differential privacy setting. In this problem, given a corpus of private text data, the goal is to release as many $n$-grams as possible while preserving user level privacy. Extracting $n$-grams is a fundamental subroutine in many NLP applications such as sentence completion, response generation for emails etc. The problem also arises in other applications such as sequence mining, and is a generalization of recently studied differentially private set union (DPSU). In this paper, we develop a new differentially private algorithm for this problem which, in our experiments, significantly outperforms the state-of-the-art. Our improvements stem from combining recent advances in DPSU, privacy accounting, and new heuristics for pruning in the tree-based approach initiated by Chen et al. (2012).