 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToken Warping Helps MLLMs Look from Nearby Viewpoints
Apr 03, 2026Can warping tokens, rather than pixels, help multimodal large language models (MLLMs) understand how a scene appears from a nearby viewpoint? While MLLMs perform well on visual reasoning, they remain fragile to viewpoint changes, as pixel-wise warping is highly sensitive to small depth errors and often introduces geometric distortions. Drawing on theories of mental imagery that posit part-level structural representations as the basis for human perspective transformation, we examine whether image tokens in ViT-based MLLMs serve as an effective substrate for viewpoint changes. We compare forward and backward warping, finding that backward token warping, which defines a dense grid on the target view and retrieves a corresponding source-view token for each grid point, achieves greater stability and better preserves semantic coherence under viewpoint shifts. Experiments on our proposed ViewBench benchmark demonstrate that token-level warping enables MLLMs to reason reliably from nearby viewpoints, consistently outperforming all baselines including pixel-wise warping approaches, spatially fine-tuned MLLMs, and a generative warping method.
DiffusionRollout: Uncertainty-Aware Rollout Planning in Long-Horizon PDE Solving
Feb 14, 2026We propose DiffusionRollout, a novel selective rollout planning strategy for autoregressive diffusion models, aimed at mitigating error accumulation in long-horizon predictions of physical systems governed by partial differential equations (PDEs). Building on the recently validated probabilistic approach to PDE solving, we further explore its ability to quantify predictive uncertainty and demonstrate a strong correlation between prediction errors and standard deviations computed over multiple samples-supporting their use as a proxy for the model's predictive confidence. Based on this observation, we introduce a mechanism that adaptively selects step sizes during autoregressive rollouts, improving long-term prediction reliability by reducing the compounding effect of conditioning on inaccurate prior outputs. Extensive evaluation on long-trajectory PDE prediction benchmarks validates the effectiveness of the proposed uncertainty measure and adaptive planning strategy, as evidenced by lower prediction errors and longer predicted trajectories that retain a high correlation with their ground truths.
BézierFlow: Learning Bézier Stochastic Interpolant Schedulers for Few-Step Generation
Dec 28, 2025We introduce BézierFlow, a lightweight training approach for few-step generation with pretrained diffusion and flow models. BézierFlow achieves a 2-3x performance improvement for sampling with $\leq$ 10 NFEs while requiring only 15 minutes of training. Recent lightweight training approaches have shown promise by learning optimal timesteps, but their scope remains restricted to ODE discretizations. To broaden this scope, we propose learning the optimal transformation of the sampling trajectory by parameterizing stochastic interpolant (SI) schedulers. The main challenge lies in designing a parameterization that satisfies critical desiderata, including boundary conditions, differentiability, and monotonicity of the SNR. To effectively meet these requirements, we represent scheduler functions as Bézier functions, where control points naturally enforce these properties. This reduces the problem to learning an ordered set of points in the time range, while the interpretation of the points changes from ODE timesteps to Bézier control points. Across a range of pretrained diffusion and flow models, BézierFlow consistently outperforms prior timestep-learning methods, demonstrating the effectiveness of expanding the search space from discrete timesteps to Bézier-based trajectory transformations.
PairFlow: Closed-Form Source-Target Coupling for Few-Step Generation in Discrete Flow Models
Dec 23, 2025We introduce $\texttt{PairFlow}$, a lightweight preprocessing step for training Discrete Flow Models (DFMs) to achieve few-step sampling without requiring a pretrained teacher. DFMs have recently emerged as a new class of generative models for discrete data, offering strong performance. However, they suffer from slow sampling due to their iterative nature. Existing acceleration methods largely depend on finetuning, which introduces substantial additional training overhead. $\texttt{PairFlow}$ addresses this issue with a lightweight preprocessing step. Inspired by ReFlow and its extension to DFMs, we train DFMs from coupled samples of source and target distributions, without requiring any pretrained teacher. At the core of our approach is a closed-form inversion for DFMs, which allows efficient construction of paired source-target samples. Despite its extremely low cost, taking only up to 1.7% of the compute needed for full model training, $\texttt{PairFlow}$ matches or even surpasses the performance of two-stage training involving finetuning. Furthermore, models trained with our framework provide stronger base models for subsequent distillation, yielding further acceleration after finetuning. Experiments on molecular data as well as binary and RGB images demonstrate the broad applicability and effectiveness of our approach.
BézierFlow: Bézier Stochastic Interpolant Schedulers for Few-Step Generation
Dec 15, 2025We introduce BézierFlow, a lightweight training approach for few-step generation with pretrained diffusion and flow models. BézierFlow achieves a 2-3x performance improvement for sampling with $\leq$ 10 NFEs while requiring only 15 minutes of training. Recent lightweight training approaches have shown promise by learning optimal timesteps, but their scope remains restricted to ODE discretizations. To broaden this scope, we propose learning the optimal transformation of the sampling trajectory by parameterizing stochastic interpolant (SI) schedulers. The main challenge lies in designing a parameterization that satisfies critical desiderata, including boundary conditions, differentiability, and monotonicity of the SNR. To effectively meet these requirements, we represent scheduler functions as Bézier functions, where control points naturally enforce these properties. This reduces the problem to learning an ordered set of points in the time range, while the interpretation of the points changes from ODE timesteps to Bézier control points. Across a range of pretrained diffusion and flow models, BézierFlow consistently outperforms prior timestep-learning methods, demonstrating the effectiveness of expanding the search space from discrete timesteps to Bézier-based trajectory transformations.
Neural Pose Representation Learning for Generating and Transferring Non-Rigid Object Poses
Jun 14, 2024



We propose a novel method for learning representations of poses for 3D deformable objects, which specializes in 1) disentangling pose information from the object's identity, 2) facilitating the learning of pose variations, and 3) transferring pose information to other object identities. Based on these properties, our method enables the generation of 3D deformable objects with diversity in both identities and poses, using variations of a single object. It does not require explicit shape parameterization such as skeletons or joints, point-level or shape-level correspondence supervision, or variations of the target object for pose transfer. To achieve pose disentanglement, compactness for generative models, and transferability, we first design the pose extractor to represent the pose as a keypoint-based hybrid representation and the pose applier to learn an implicit deformation field. To better distill pose information from the object's geometry, we propose the implicit pose applier to output an intrinsic mesh property, the face Jacobian. Once the extracted pose information is transferred to the target object, the pose applier is fine-tuned in a self-supervised manner to better describe the target object's shapes with pose variations. The extracted poses are also used to train a cascaded diffusion model to enable the generation of novel poses. Our experiments with the DeformThings4D and Human datasets demonstrate state-of-the-art performance in pose transfer and the ability to generate diverse deformed shapes with various objects and poses.
As-Plausible-As-Possible: Plausibility-Aware Mesh Deformation Using 2D Diffusion Priors
Nov 28, 2023



We present As-Plausible-as-Possible (APAP) mesh deformation technique that leverages 2D diffusion priors to preserve the plausibility of a mesh under user-controlled deformation. Our framework uses per-face Jacobians to represent mesh deformations, where mesh vertex coordinates are computed via a differentiable Poisson Solve. The deformed mesh is rendered, and the resulting 2D image is used in the Score Distillation Sampling (SDS) process, which enables extracting meaningful plausibility priors from a pretrained 2D diffusion model. To better preserve the identity of the edited mesh, we fine-tune our 2D diffusion model with LoRA. Gradients extracted by SDS and a user-prescribed handle displacement are then backpropagated to the per-face Jacobians, and we use iterative gradient descent to compute the final deformation that balances between the user edit and the output plausibility. We evaluate our method with 2D and 3D meshes and demonstrate qualitative and quantitative improvements when using plausibility priors over geometry-preservation or distortion-minimization priors used by previous techniques.
SALAD: Part-Level Latent Diffusion for 3D Shape Generation and Manipulation
Mar 21, 2023



We present a cascaded diffusion model based on a part-level implicit 3D representation. Our model achieves state-of-the-art generation quality and also enables part-level shape editing and manipulation without any additional training in conditional setup. Diffusion models have demonstrated impressive capabilities in data generation as well as zero-shot completion and editing via a guided reverse process. Recent research on 3D diffusion models has focused on improving their generation capabilities with various data representations, while the absence of structural information has limited their capability in completion and editing tasks. We thus propose our novel diffusion model using a part-level implicit representation. To effectively learn diffusion with high-dimensional embedding vectors of parts, we propose a cascaded framework, learning diffusion first on a low-dimensional subspace encoding extrinsic parameters of parts and then on the other high-dimensional subspace encoding intrinsic attributes. In the experiments, we demonstrate the outperformance of our method compared with the previous ones both in generation and part-level completion and manipulation tasks.
Online Extrinsic Camera Calibration for Temporally Consistent IPM Using Lane Boundary Observations with a Lane Width Prior
Aug 09, 2020
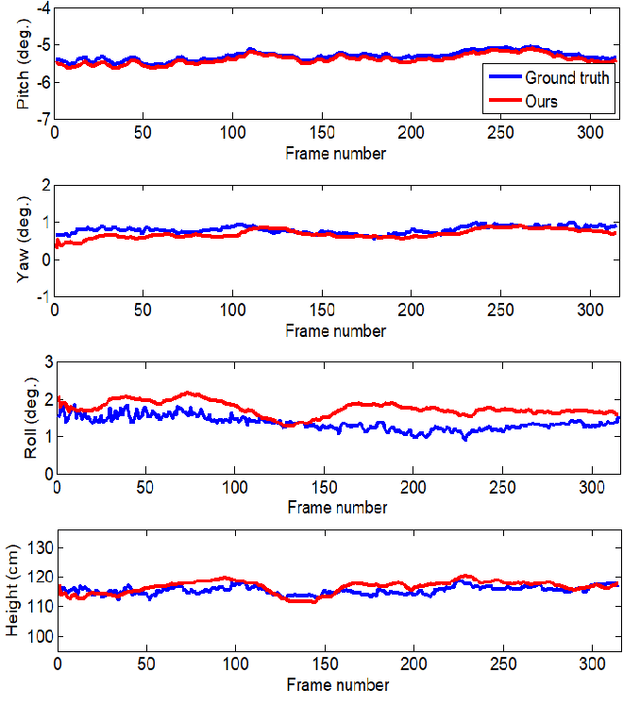

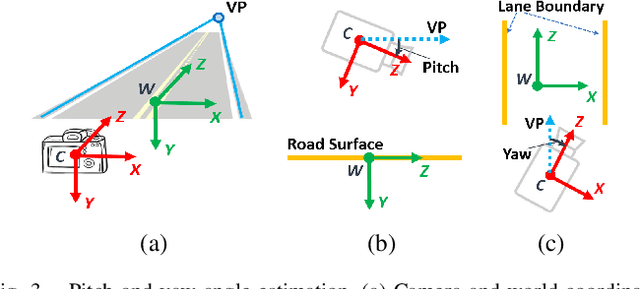
In this paper, we propose a method for online extrinsic camera calibration, i.e., estimating pitch, yaw, roll angles and camera height from road surface in sequential driving scene images. The proposed method estimates the extrinsic camera parameters in two steps: 1) pitch and yaw angles are estimated simultaneously using a vanishing point computed from a set of lane boundary observations, and then 2) roll angle and camera height are computed by minimizing difference between lane width observations and a lane width prior. The extrinsic camera parameters are sequentially updated using extended Kalman filtering (EKF) and are finally used to generate a temporally consistent bird-eye-view (BEV) image by inverse perspective mapping (IPM). We demonstrate the superiority of the proposed method in synthetic and real-world datasets.
End-to-End Lane Marker Detection via Row-wise Classification
May 06, 2020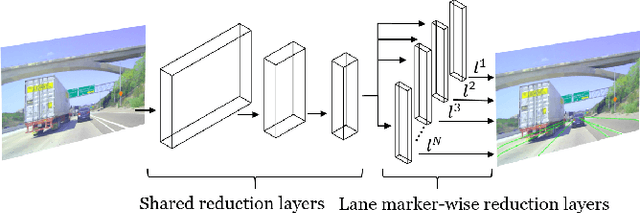
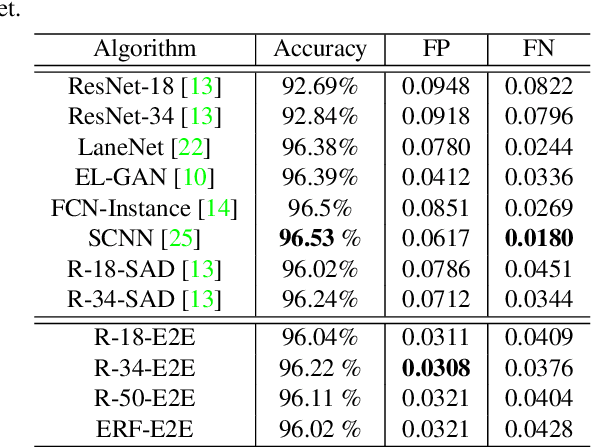
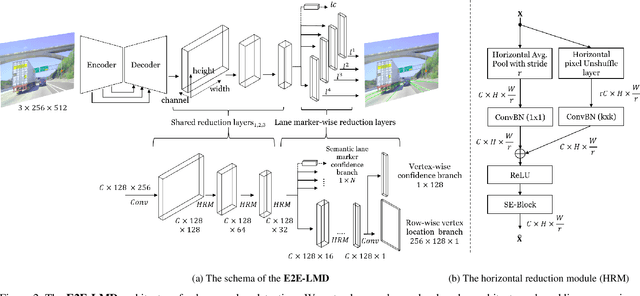
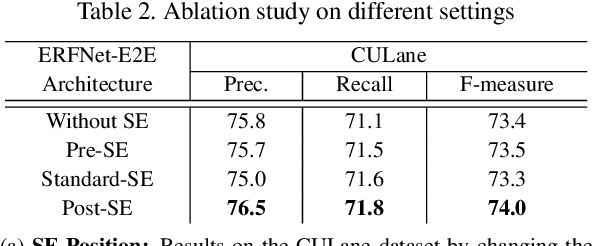
In autonomous driving, detecting reliable and accurate lane marker positions is a crucial yet challenging task. The conventional approaches for the lane marker detection problem perform a pixel-level dense prediction task followed by sophisticated post-processing that is inevitable since lane markers are typically represented by a collection of line segments without thickness. In this paper, we propose a method performing direct lane marker vertex prediction in an end-to-end manner, i.e., without any post-processing step that is required in the pixel-level dense prediction task. Specifically, we translate the lane marker detection problem into a row-wise classification task, which takes advantage of the innate shape of lane markers but, surprisingly, has not been explored well. In order to compactly extract sufficient information about lane markers which spread from the left to the right in an image, we devise a novel layer, which is utilized to successively compress horizontal components so enables an end-to-end lane marker detection system where the final lane marker positions are simply obtained via argmax operations in testing time. Experimental results demonstrate the effectiveness of the proposed method, which is on par or outperforms the state-of-the-art methods on two popular lane marker detection benchmarks, i.e., TuSimple and CULane.