 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhanced Simultaneous Machine Translation with Word-level Policies
Oct 25, 2023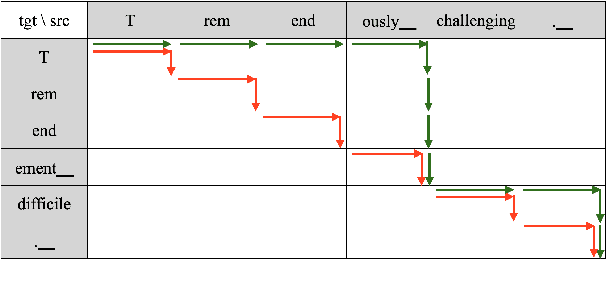
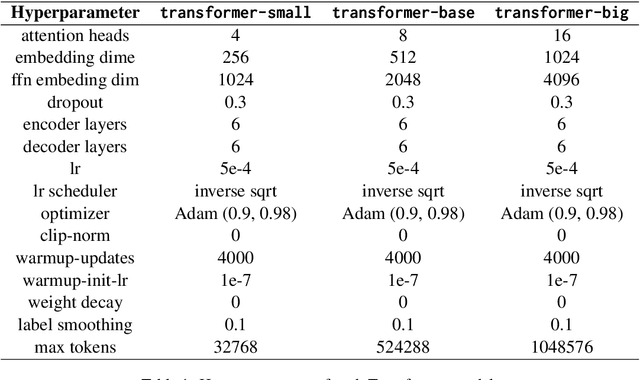

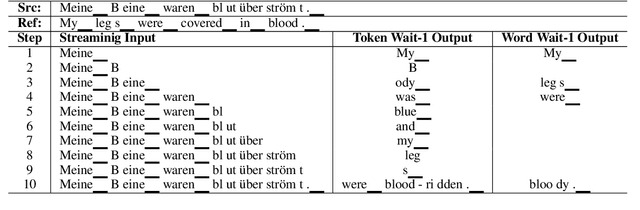
Recent years have seen remarkable advances in the field of Simultaneous Machine Translation (SiMT) due to the introduction of innovative policies that dictate whether to READ or WRITE at each step of the translation process. However, a common assumption in many existing studies is that operations are carried out at the subword level, even though the standard unit for input and output in most practical scenarios is typically at the word level. This paper demonstrates that policies devised and validated at the subword level are surpassed by those operating at the word level, which process multiple subwords to form a complete word in a single step. Additionally, we suggest a method to boost SiMT models using language models (LMs), wherein the proposed word-level policy plays a vital role in addressing the subword disparity between LMs and SiMT models. Code is available at https://github.com/xl8-ai/WordSiMT.
Online Extrinsic Camera Calibration for Temporally Consistent IPM Using Lane Boundary Observations with a Lane Width Prior
Aug 09, 2020
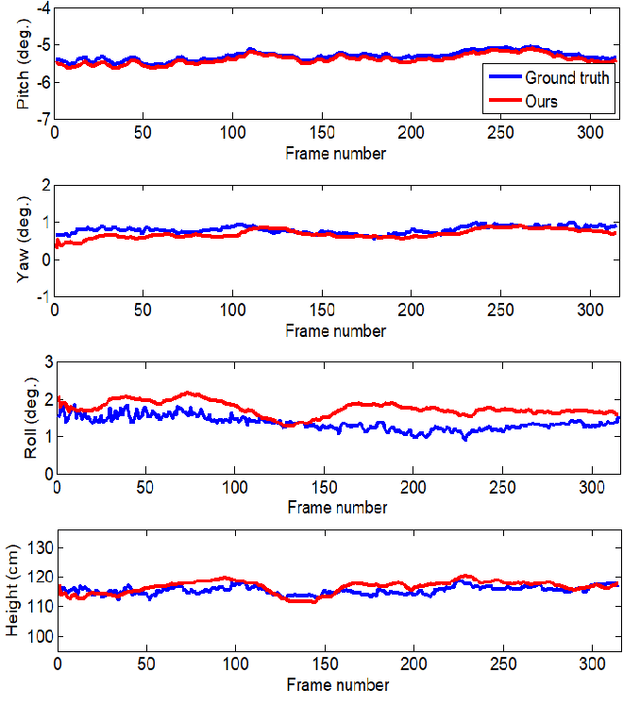

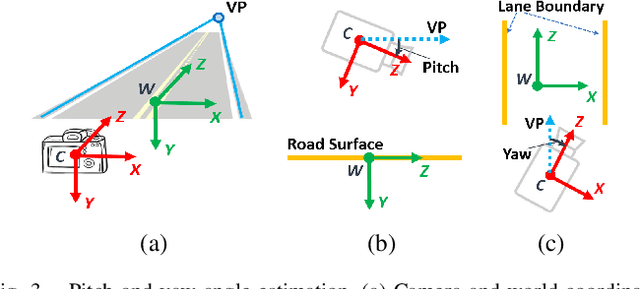
In this paper, we propose a method for online extrinsic camera calibration, i.e., estimating pitch, yaw, roll angles and camera height from road surface in sequential driving scene images. The proposed method estimates the extrinsic camera parameters in two steps: 1) pitch and yaw angles are estimated simultaneously using a vanishing point computed from a set of lane boundary observations, and then 2) roll angle and camera height are computed by minimizing difference between lane width observations and a lane width prior. The extrinsic camera parameters are sequentially updated using extended Kalman filtering (EKF) and are finally used to generate a temporally consistent bird-eye-view (BEV) image by inverse perspective mapping (IPM). We demonstrate the superiority of the proposed method in synthetic and real-world datasets.
1-Point RANSAC-Based Method for Ground Object Pose Estimation
Aug 09, 2020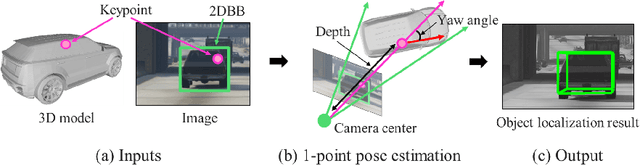
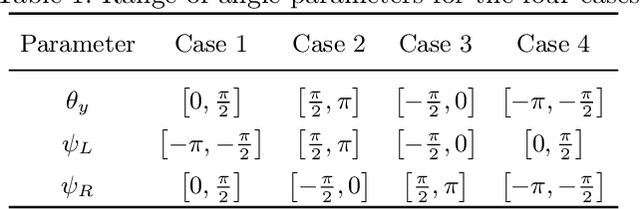
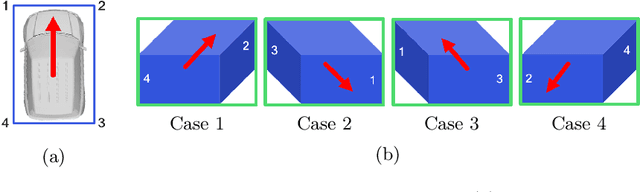
Solving Perspective-n-Point (PnP) problems is a traditional way of estimating object poses. Given outlier-contaminated data, a pose of an object is calculated with PnP algorithms of n = {3, 4} in the RANSAC-based scheme. However, the computational complexity considerably increases along with n and the high complexity imposes a severe strain on devices which should estimate multiple object poses in real time. In this paper, we propose an efficient method based on 1-point RANSAC for estimating a pose of an object on the ground. In the proposed method, a pose is calculated with 1-DoF parameterization by using a ground object assumption and a 2D object bounding box as an additional observation, thereby achieving the fastest performance among the RANSAC-based methods. In addition, since the method suffers from the errors of the additional information, we propose a hierarchical robust estimation method for polishing a rough pose estimate and discovering more inliers in a coarse-to-fine manner. The experiments in synthetic and real-world datasets demonstrate the superiority of the proposed method.