 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFour Generations of Quantum Biomedical Sensors
Apr 02, 2026Quantum sensing technologies offer transformative potential for ultra-sensitive biomedical sensing, yet their clinical translation remains constrained by classical noise limits and a reliance on macroscopic ensembles. We propose a unifying generational framework to organize the evolving landscape of quantum biosensors based on their utilization of quantum resources. First-generation devices utilize discrete energy levels for signal transduction but follow classical scaling laws. Second-generation sensors exploit quantum coherence to reach the standard quantum limit, while third-generation architectures leverage entanglement and spin squeezing to approach Heisenberg-limited precision. We further define an emerging fourth generation characterized by the end-to-end integration of quantum sensing with quantum learning and variational circuits, enabling adaptive inference directly within the quantum domain. By analyzing critical parameters such as bandwidth matching and sensor-tissue proximity, we identify key technological bottlenecks and propose a roadmap for transitioning from measuring physical observables to extracting structured biological information with quantum-enhanced intelligence.
InterSliceBoost: Identifying Tissue Layers in Three-dimensional Ultrasound Images for Chronic Lower Back Pain (cLBP) Assessment
Mar 25, 2025Available studies on chronic lower back pain (cLBP) typically focus on one or a few specific tissues rather than conducting a comprehensive layer-by-layer analysis. Since three-dimensional (3-D) images often contain hundreds of slices, manual annotation of these anatomical structures is both time-consuming and error-prone. We aim to develop and validate a novel approach called InterSliceBoost to enable the training of a segmentation model on a partially annotated dataset without compromising segmentation performance. The architecture of InterSliceBoost includes two components: an inter-slice generator and a segmentation model. The generator utilizes residual block-based encoders to extract features from adjacent image-mask pairs (IMPs). Differential features are calculated and input into a decoder to generate inter-slice IMPs. The segmentation model is trained on partially annotated datasets (e.g., skipping 1, 2, 3, or 7 images) and the generated inter-slice IMPs. To validate the performance of InterSliceBoost, we utilized a dataset of 76 B-mode ultrasound scans acquired on 29 subjects enrolled in an ongoing cLBP study. InterSliceBoost, trained on only 33% of the image slices, achieved a mean Dice coefficient of 80.84% across all six layers on the independent test set, with Dice coefficients of 73.48%, 61.11%, 81.87%, 95.74%, 83.52% and 88.74% for segmenting dermis, superficial fat, superficial fascial membrane, deep fat, deep fascial membrane, and muscle. This performance is significantly higher than the conventional model trained on fully annotated images (p<0.05). InterSliceBoost can effectively segment the six tissue layers depicted on 3-D B-model ultrasound images in settings with partial annotations.
Segmentation-Aware Generative Reinforcement Network (GRN) for Tissue Layer Segmentation in 3-D Ultrasound Images for Chronic Low-back Pain (cLBP) Assessment
Jan 29, 2025We introduce a novel segmentation-aware joint training framework called generative reinforcement network (GRN) that integrates segmentation loss feedback to optimize both image generation and segmentation performance in a single stage. An image enhancement technique called segmentation-guided enhancement (SGE) is also developed, where the generator produces images tailored specifically for the segmentation model. Two variants of GRN were also developed, including GRN for sample-efficient learning (GRN-SEL) and GRN for semi-supervised learning (GRN-SSL). GRN's performance was evaluated using a dataset of 69 fully annotated 3D ultrasound scans from 29 subjects. The annotations included six anatomical structures: dermis, superficial fat, superficial fascial membrane (SFM), deep fat, deep fascial membrane (DFM), and muscle. Our results show that GRN-SEL with SGE reduces labeling efforts by up to 70% while achieving a 1.98% improvement in the Dice Similarity Coefficient (DSC) compared to models trained on fully labeled datasets. GRN-SEL alone reduces labeling efforts by 60%, GRN-SSL with SGE decreases labeling requirements by 70%, and GRN-SSL alone by 60%, all while maintaining performance comparable to fully supervised models. These findings suggest the effectiveness of the GRN framework in optimizing segmentation performance with significantly less labeled data, offering a scalable and efficient solution for ultrasound image analysis and reducing the burdens associated with data annotation.
Enhanced Simultaneous Machine Translation with Word-level Policies
Oct 25, 2023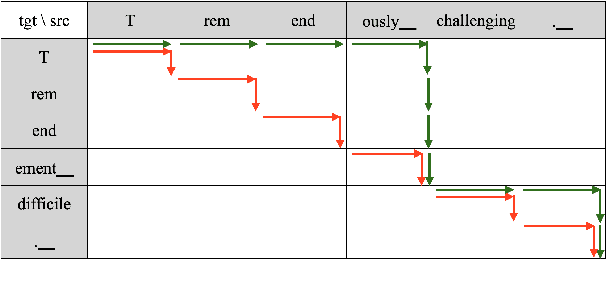
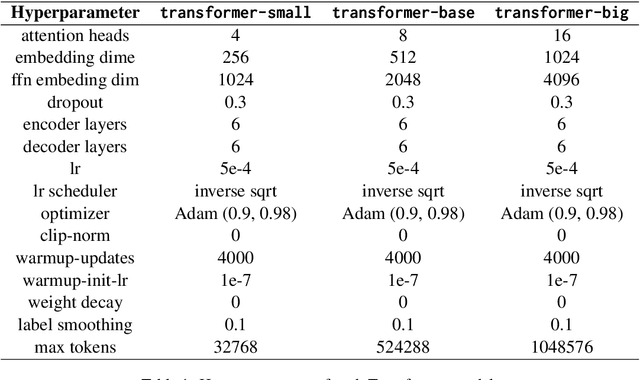

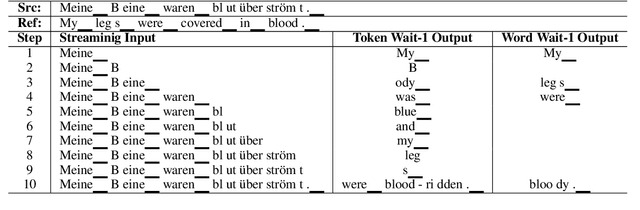
Recent years have seen remarkable advances in the field of Simultaneous Machine Translation (SiMT) due to the introduction of innovative policies that dictate whether to READ or WRITE at each step of the translation process. However, a common assumption in many existing studies is that operations are carried out at the subword level, even though the standard unit for input and output in most practical scenarios is typically at the word level. This paper demonstrates that policies devised and validated at the subword level are surpassed by those operating at the word level, which process multiple subwords to form a complete word in a single step. Additionally, we suggest a method to boost SiMT models using language models (LMs), wherein the proposed word-level policy plays a vital role in addressing the subword disparity between LMs and SiMT models. Code is available at https://github.com/xl8-ai/WordSiMT.
Quantitative Prediction on the Enantioselectivity of Multiple Chiral Iodoarene Scaffolds Based on Whole Geometry
Mar 25, 2021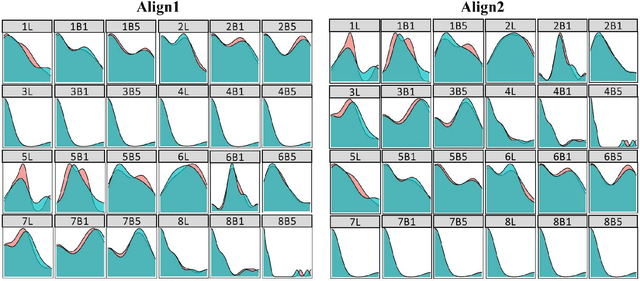
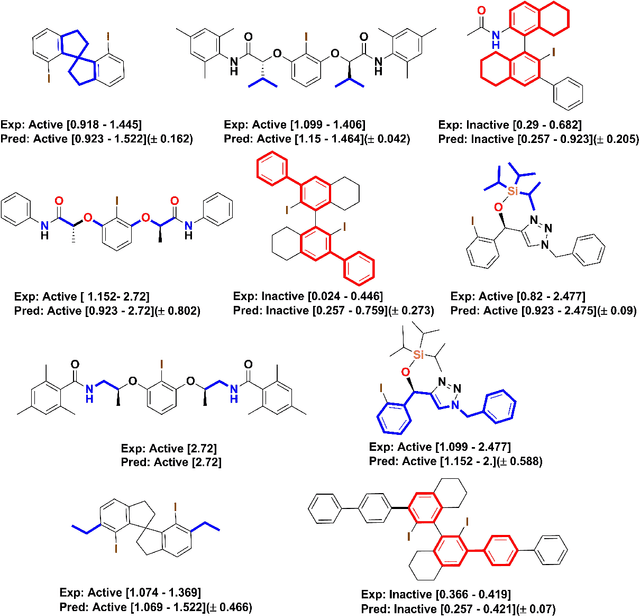
The mechanistic underpinnings of asymmetric catalysis at atomic levels provide shortcuts for developing the potential value of chiral catalysts beyond the current state-of-the-art. In the enantioselective redox transformations, the present intuition-driven studies require a systematic approach to support their intuitive idea. Arguably, the most systematic approach would be based on the reliable quantitative structure-selectivity relationship of diverse and dissimilar chiral scaffolds in an optimal feature space that is universally applied to reactions. Here, we introduce a predictive workflow for the extension of the reaction scope of chiral catalysts across name reactions. For this purpose, whole geometry descriptors were encoded from DFT optimized 3D structures of multiple catalyst scaffolds, 113 catalysts in 9 clusters. The molecular descriptors were verified by the statistical comparison of the enantioselective predictive classification models built from each descriptors of chiral iodoarenes. More notably, capturing the whole molecular geometry through one hot encoding of split three-dimensional molecular fingerprints presented reliable enantioselective predictive regression models for three different name reactions by recycling the data and metadata obtained across reactions. The potential use value of this workflow and the advantages of recyclability, compatibility, and generality proved that the workflow can be applied for name reactions other than the aforementioned name reactions (out of samples). Furthermore, for the consensus prediction of ensemble models, this global descriptor can be compared with sterimol parameters and noncovalent interaction vectors. This study is one case showing how to overcome the sparsity of experimental data in organic reactions, especially asymmetric catalysis.
1-Point RANSAC-Based Method for Ground Object Pose Estimation
Aug 09, 2020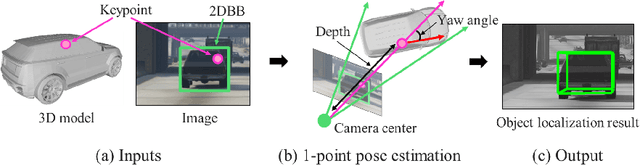
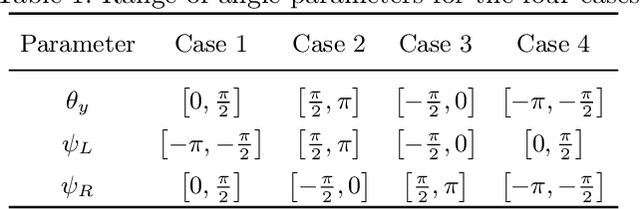
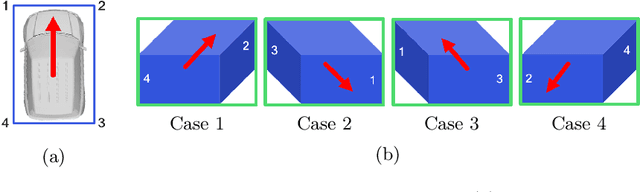
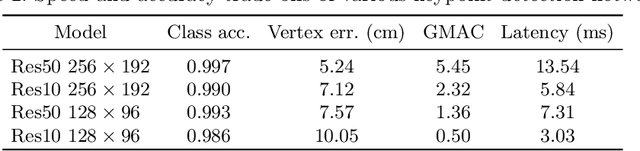
Solving Perspective-n-Point (PnP) problems is a traditional way of estimating object poses. Given outlier-contaminated data, a pose of an object is calculated with PnP algorithms of n = {3, 4} in the RANSAC-based scheme. However, the computational complexity considerably increases along with n and the high complexity imposes a severe strain on devices which should estimate multiple object poses in real time. In this paper, we propose an efficient method based on 1-point RANSAC for estimating a pose of an object on the ground. In the proposed method, a pose is calculated with 1-DoF parameterization by using a ground object assumption and a 2D object bounding box as an additional observation, thereby achieving the fastest performance among the RANSAC-based methods. In addition, since the method suffers from the errors of the additional information, we propose a hierarchical robust estimation method for polishing a rough pose estimate and discovering more inliers in a coarse-to-fine manner. The experiments in synthetic and real-world datasets demonstrate the superiority of the proposed method.
Probabilistic Anchor Assignment with IoU Prediction for Object Detection
Jul 16, 2020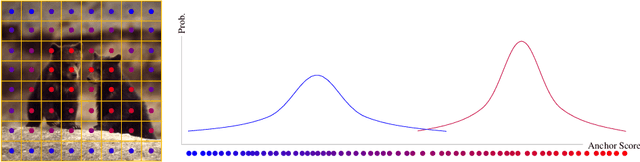
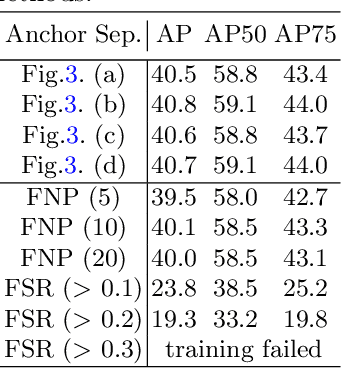
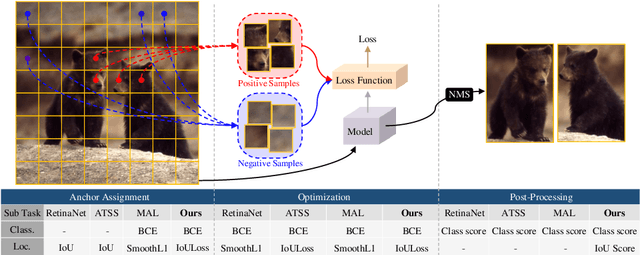
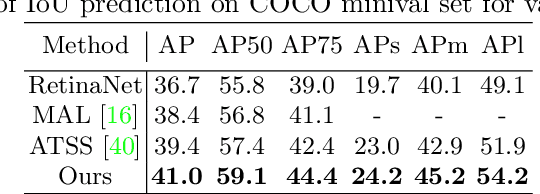
In object detection, determining which anchors to assign as positive or negative samples, known as anchor assignment, has been revealed as a core procedure that can significantly affect a model's performance. In this paper we propose a novel anchor assignment strategy that adaptively separates anchors into positive and negative samples for a ground truth bounding box according to the model's learning status such that it is able to reason about the separation in a probabilistic manner. To do so we first calculate the scores of anchors conditioned on the model and fit a probability distribution to these scores. The model is then trained with anchors separated into positive and negative samples according to their probabilities. Moreover, we investigate the gap between the training and testing objectives and propose to predict the Intersection-over-Unions of detected boxes as a measure of localization quality to reduce the discrepancy. The combined score of classification and localization qualities serving as a box selection metric in non-maximum suppression well aligns with the proposed anchor assignment strategy and leads significant performance improvements. The proposed methods only add a single convolutional layer to RetinaNet baseline and does not require multiple anchors per location, so are efficient. Experimental results verify the effectiveness of the proposed methods. Especially, our models set new records for single-stage detectors on MS COCO test-dev dataset with various backbones. Code is available at https://github.com/kkhoot/PAA.
Simultaneous Traffic Sign Detection and Boundary Estimation using Convolutional Neural Network
Feb 27, 2018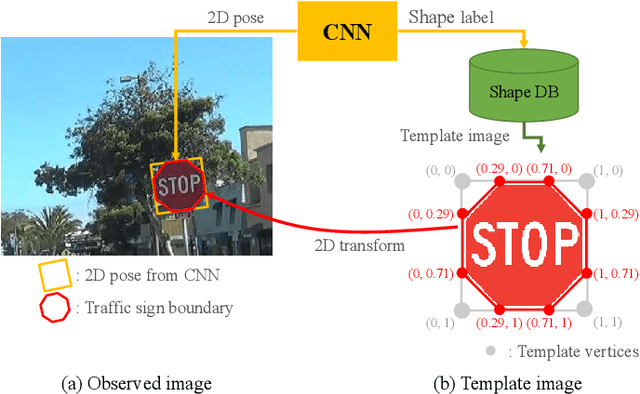
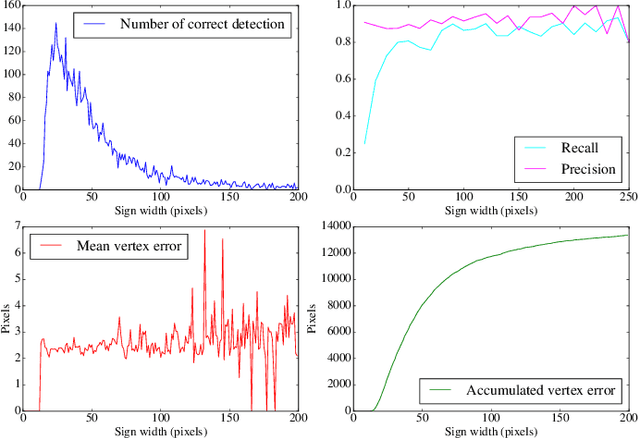


We propose a novel traffic sign detection system that simultaneously estimates the location and precise boundary of traffic signs using convolutional neural network (CNN). Estimating the precise boundary of traffic signs is important in navigation systems for intelligent vehicles where traffic signs can be used as 3D landmarks for road environment. Previous traffic sign detection systems, including recent methods based on CNN, only provide bounding boxes of traffic signs as output, and thus requires additional processes such as contour estimation or image segmentation to obtain the precise sign boundary. In this work, the boundary estimation of traffic signs is formulated as a 2D pose and shape class prediction problem, and this is effectively solved by a single CNN. With the predicted 2D pose and the shape class of a target traffic sign in an input image, we estimate the actual boundary of the target sign by projecting the boundary of a corresponding template sign image into the input image plane. By formulating the boundary estimation problem as a CNN-based pose and shape prediction task, our method is end-to-end trainable, and more robust to occlusion and small targets than other boundary estimation methods that rely on contour estimation or image segmentation. The proposed method with architectural optimization provides an accurate traffic sign boundary estimation which is also efficient in compute, showing a detection frame rate higher than 7 frames per second on low-power mobile platforms.