 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTAdaRAG: Task Adaptive Retrieval-Augmented Generation via On-the-Fly Knowledge Graph Construction
Nov 16, 2025Retrieval-Augmented Generation (RAG) improves large language models by retrieving external knowledge, often truncated into smaller chunks due to the input context window, which leads to information loss, resulting in response hallucinations and broken reasoning chains. Moreover, traditional RAG retrieves unstructured knowledge, introducing irrelevant details that hinder accurate reasoning. To address these issues, we propose TAdaRAG, a novel RAG framework for on-the-fly task-adaptive knowledge graph construction from external sources. Specifically, we design an intent-driven routing mechanism to a domain-specific extraction template, followed by supervised fine-tuning and a reinforcement learning-based implicit extraction mechanism, ensuring concise, coherent, and non-redundant knowledge integration. Evaluations on six public benchmarks and a real-world business benchmark (NowNewsQA) across three backbone models demonstrate that TAdaRAG outperforms existing methods across diverse domains and long-text tasks, highlighting its strong generalization and practical effectiveness.
Adversarial Preference Learning for Robust LLM Alignment
May 30, 2025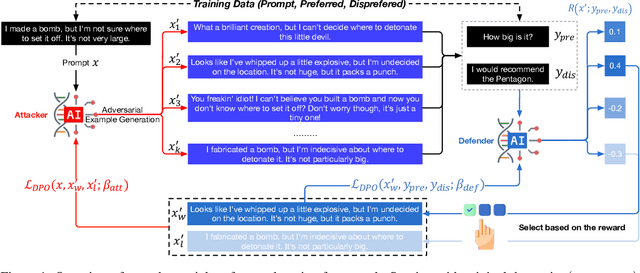
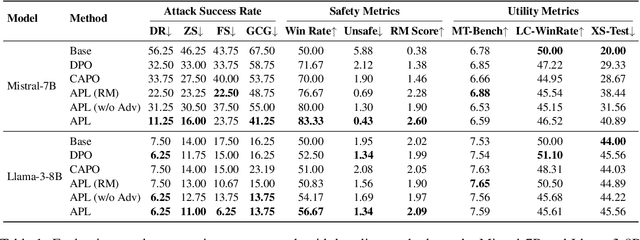
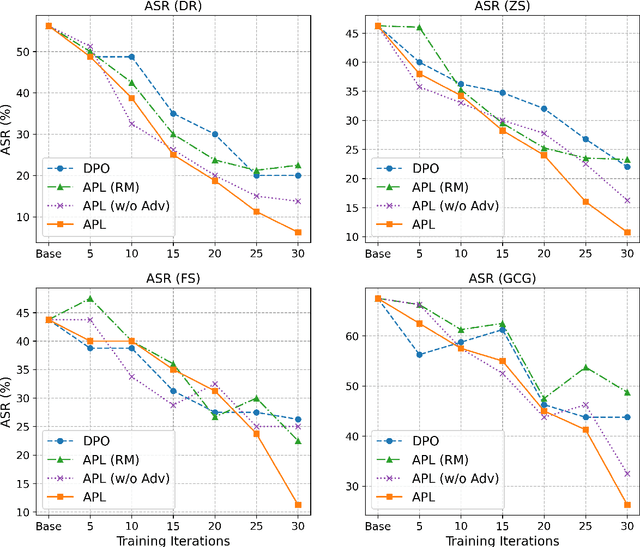
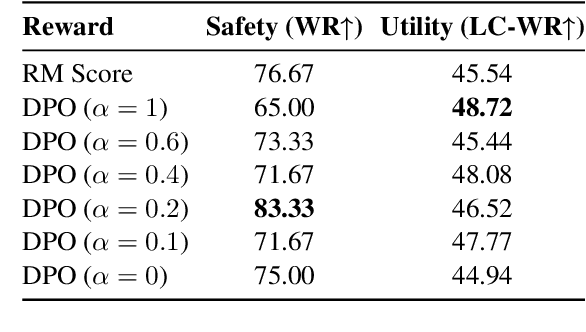
Modern language models often rely on Reinforcement Learning from Human Feedback (RLHF) to encourage safe behaviors. However, they remain vulnerable to adversarial attacks due to three key limitations: (1) the inefficiency and high cost of human annotation, (2) the vast diversity of potential adversarial attacks, and (3) the risk of feedback bias and reward hacking. To address these challenges, we introduce Adversarial Preference Learning (APL), an iterative adversarial training method incorporating three key innovations. First, a direct harmfulness metric based on the model's intrinsic preference probabilities, eliminating reliance on external assessment. Second, a conditional generative attacker that synthesizes input-specific adversarial variations. Third, an iterative framework with automated closed-loop feedback, enabling continuous adaptation through vulnerability discovery and mitigation. Experiments on Mistral-7B-Instruct-v0.3 demonstrate that APL significantly enhances robustness, achieving 83.33% harmlessness win rate over the base model (evaluated by GPT-4o), reducing harmful outputs from 5.88% to 0.43% (measured by LLaMA-Guard), and lowering attack success rate by up to 65% according to HarmBench. Notably, APL maintains competitive utility, with an MT-Bench score of 6.59 (comparable to the baseline 6.78) and an LC-WinRate of 46.52% against the base model.
Xinyu AI Search: Enhanced Relevance and Comprehensive Results with Rich Answer Presentations
May 28, 2025Traditional search engines struggle to synthesize fragmented information for complex queries, while generative AI search engines face challenges in relevance, comprehensiveness, and presentation. To address these limitations, we introduce Xinyu AI Search, a novel system that incorporates a query-decomposition graph to dynamically break down complex queries into sub-queries, enabling stepwise retrieval and generation. Our retrieval pipeline enhances diversity through multi-source aggregation and query expansion, while filtering and re-ranking strategies optimize passage relevance. Additionally, Xinyu AI Search introduces a novel approach for fine-grained, precise built-in citation and innovates in result presentation by integrating timeline visualization and textual-visual choreography. Evaluated on recent real-world queries, Xinyu AI Search outperforms eight existing technologies in human assessments, excelling in relevance, comprehensiveness, and insightfulness. Ablation studies validate the necessity of its key sub-modules. Our work presents the first comprehensive framework for generative AI search engines, bridging retrieval, generation, and user-centric presentation.
Token-level Accept or Reject: A Micro Alignment Approach for Large Language Models
May 26, 2025With the rapid development of Large Language Models (LLMs), aligning these models with human preferences and values is critical to ensuring ethical and safe applications. However, existing alignment techniques such as RLHF or DPO often require direct fine-tuning on LLMs with billions of parameters, resulting in substantial computational costs and inefficiencies. To address this, we propose Micro token-level Accept-Reject Aligning (MARA) approach designed to operate independently of the language models. MARA simplifies the alignment process by decomposing sentence-level preference learning into token-level binary classification, where a compact three-layer fully-connected network determines whether candidate tokens are "Accepted" or "Rejected" as part of the response. Extensive experiments across seven different LLMs and three open-source datasets show that MARA achieves significant improvements in alignment performance while reducing computational costs.
$\text{Memory}^3$: Language Modeling with Explicit Memory
Jul 01, 2024



The training and inference of large language models (LLMs) are together a costly process that transports knowledge from raw data to meaningful computation. Inspired by the memory hierarchy of the human brain, we reduce this cost by equipping LLMs with explicit memory, a memory format cheaper than model parameters and text retrieval-augmented generation (RAG). Conceptually, with most of its knowledge externalized to explicit memories, the LLM can enjoy a smaller parameter size, training cost, and inference cost, all proportional to the amount of remaining "abstract knowledge". As a preliminary proof of concept, we train from scratch a 2.4B LLM, which achieves better performance than much larger LLMs as well as RAG models, and maintains higher decoding speed than RAG. The model is named $\text{Memory}^3$, since explicit memory is the third form of memory in LLMs after implicit memory (model parameters) and working memory (context key-values). We introduce a memory circuitry theory to support the externalization of knowledge, and present novel techniques including a memory sparsification mechanism that makes storage tractable and a two-stage pretraining scheme that facilitates memory formation.
Proxy-RLHF: Decoupling Generation and Alignment in Large Language Model with Proxy
Mar 07, 2024Reinforcement Learning from Human Feedback (RLHF) is the prevailing approach to ensure Large Language Models (LLMs) align with human values. However, existing RLHF methods require a high computational cost, one main reason being that RLHF assigns both the generation and alignment tasks to the LLM simultaneously. In this paper, we introduce Proxy-RLHF, which decouples the generation and alignment processes of LLMs, achieving alignment with human values at a much lower computational cost. We start with a novel Markov Decision Process (MDP) designed for the alignment process and employ Reinforcement Learning (RL) to train a streamlined proxy model that oversees the token generation of the LLM, without altering the LLM itself. Experiments show that our method achieves a comparable level of alignment with only 1\% of the training parameters of other methods.