 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTIDE-Bench: Task-Aware and Diagnostic Evaluation of Tool-Integrated Reasoning
May 10, 2026Tool-integrated reasoning has emerged as a promising paradigm for enhancing large language models with external computation, retrieval, and execution capabilities. However, the field still lacks a high-quality and unified evaluation benchmark, and existing TIR evaluations remain limited in dataset quality, task diversity, diagnostic comprehensiveness, and evaluation efficiency. In this work, we introduce TIDE-Bench, a holistic and efficient benchmark for evaluating TIR methods, featuring three key advantages. First, it provides diverse task settings, combining widely used mathematical reasoning and knowledge-intensive QA tasks with two newly designed tasks, namely the tool-grounded experimental design task and the dynamic interactive task, to probe models' abilities in complex tool invocation and multi-tool coordination. Second, TIDE-Bench adopts a comprehensive yet task-aware evaluation protocol, jointly measuring final answer quality, process reliability, tool-use efficiency, and inference cost across heterogeneous task settings. Third, TIDE-Bench constructs high-quality and discriminative evaluation sets by filtering low-discrimination instances from existing datasets, substantially reducing evaluation cost while focusing on more challenging samples. Extensive experiments on multiple foundation models and TIR methods reveal persistent bottlenecks in tool grounding, offering insights for future TIR research.
Multi-modal Test-time Adaptation via Adaptive Probabilistic Gaussian Calibration
Apr 21, 2026Multi-modal test-time adaptation (TTA) enhances the resilience of benchmark multi-modal models against distribution shifts by leveraging the unlabeled target data during inference. Despite the documented success, the advancement of multi-modal TTA methodologies has been impeded by a persistent limitation, i.e., the lack of explicit modeling of category-conditional distributions, which is crucial for yielding accurate predictions and reliable decision boundaries. Canonical Gaussian discriminant analysis (GDA) provides a vanilla modeling of category-conditional distributions and achieves moderate advancement in uni-modal contexts. However, in multi-modal TTA scenario, the inherent modality distribution asymmetry undermines the effectiveness of modeling the category-conditional distribution via the canonical GDA. To this end, we introduce a tailored probabilistic Gaussian model for multi-modal TTA to explicitly model the category-conditional distributions, and further propose an adaptive contrastive asymmetry rectification technique to counteract the adverse effects arising from modality asymmetry, thereby deriving calibrated predictions and reliable decision boundaries. Extensive experiments across diverse benchmarks demonstrate that our method achieves state-of-the-art performance under a wide range of distribution shifts. The code is available at https://github.com/XuJinglinn/AdaPGC.
Group Causal Policy Optimization for Post-Training Large Language Models
Aug 07, 2025Recent advances in large language models (LLMs) have broadened their applicability across diverse tasks, yet specialized domains still require targeted post training. Among existing methods, Group Relative Policy Optimization (GRPO) stands out for its efficiency, leveraging groupwise relative rewards while avoiding costly value function learning. However, GRPO treats candidate responses as independent, overlooking semantic interactions such as complementarity and contradiction. To address this challenge, we first introduce a Structural Causal Model (SCM) that reveals hidden dependencies among candidate responses induced by conditioning on a final integrated output forming a collider structure. Then, our causal analysis leads to two insights: (1) projecting responses onto a causally informed subspace improves prediction quality, and (2) this projection yields a better baseline than query only conditioning. Building on these insights, we propose Group Causal Policy Optimization (GCPO), which integrates causal structure into optimization through two key components: a causally informed reward adjustment and a novel KL regularization term that aligns the policy with a causally projected reference distribution. Comprehensive experimental evaluations demonstrate that GCPO consistently surpasses existing methods, including GRPO across multiple reasoning benchmarks.
Multi-Modal Learning with Bayesian-Oriented Gradient Calibration
May 29, 2025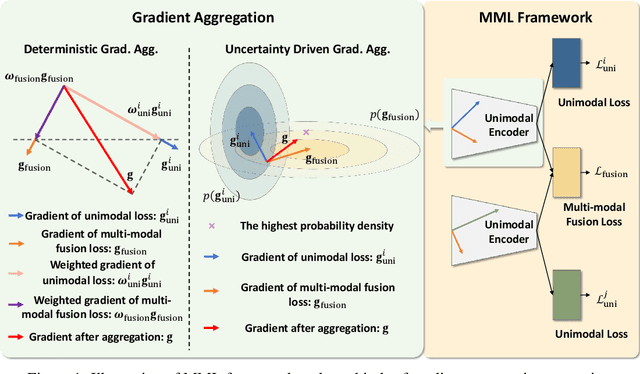
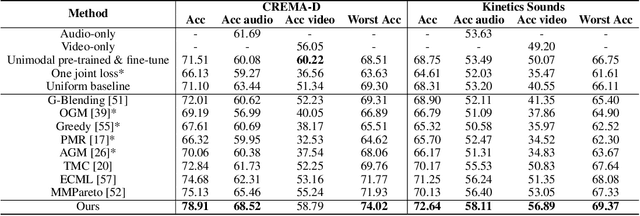
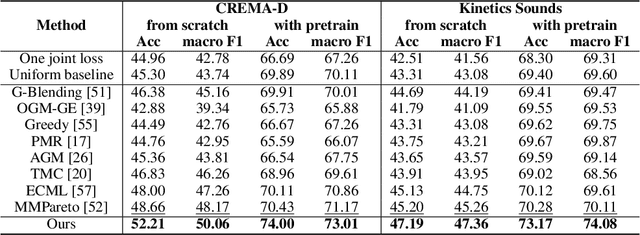
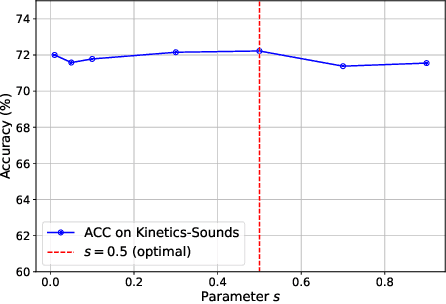
Multi-Modal Learning (MML) integrates information from diverse modalities to improve predictive accuracy. However, existing methods mainly aggregate gradients with fixed weights and treat all dimensions equally, overlooking the intrinsic gradient uncertainty of each modality. This may lead to (i) excessive updates in sensitive dimensions, degrading performance, and (ii) insufficient updates in less sensitive dimensions, hindering learning. To address this issue, we propose BOGC-MML, a Bayesian-Oriented Gradient Calibration method for MML to explicitly model the gradient uncertainty and guide the model optimization towards the optimal direction. Specifically, we first model each modality's gradient as a random variable and derive its probability distribution, capturing the full uncertainty in the gradient space. Then, we propose an effective method that converts the precision (inverse variance) of each gradient distribution into a scalar evidence. This evidence quantifies the confidence of each modality in every gradient dimension. Using these evidences, we explicitly quantify per-dimension uncertainties and fuse them via a reduced Dempster-Shafer rule. The resulting uncertainty-weighted aggregation produces a calibrated update direction that balances sensitivity and conservatism across dimensions. Extensive experiments on multiple benchmark datasets demonstrate the effectiveness and advantages of the proposed method.
Token-level Accept or Reject: A Micro Alignment Approach for Large Language Models
May 26, 2025With the rapid development of Large Language Models (LLMs), aligning these models with human preferences and values is critical to ensuring ethical and safe applications. However, existing alignment techniques such as RLHF or DPO often require direct fine-tuning on LLMs with billions of parameters, resulting in substantial computational costs and inefficiencies. To address this, we propose Micro token-level Accept-Reject Aligning (MARA) approach designed to operate independently of the language models. MARA simplifies the alignment process by decomposing sentence-level preference learning into token-level binary classification, where a compact three-layer fully-connected network determines whether candidate tokens are "Accepted" or "Rejected" as part of the response. Extensive experiments across seven different LLMs and three open-source datasets show that MARA achieves significant improvements in alignment performance while reducing computational costs.
CAIFormer: A Causal Informed Transformer for Multivariate Time Series Forecasting
May 22, 2025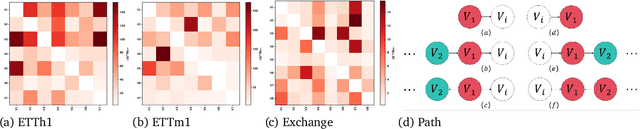

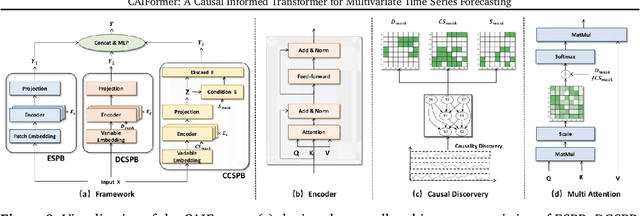

Most existing multivariate time series forecasting methods adopt an all-to-all paradigm that feeds all variable histories into a unified model to predict their future values without distinguishing their individual roles. However, this undifferentiated paradigm makes it difficult to identify variable-specific causal influences and often entangles causally relevant information with spurious correlations. To address this limitation, we propose an all-to-one forecasting paradigm that predicts each target variable separately. Specifically, we first construct a Structural Causal Model from observational data and then, for each target variable, we partition the historical sequence into four sub-segments according to the inferred causal structure: endogenous, direct causal, collider causal, and spurious correlation. The prediction relies solely on the first three causally relevant sub-segments, while the spurious correlation sub-segment is excluded. Furthermore, we propose Causal Informed Transformer (CAIFormer), a novel forecasting model comprising three components: Endogenous Sub-segment Prediction Block, Direct Causal Sub-segment Prediction Block, and Collider Causal Sub-segment Prediction Block, which process the endogenous, direct causal, and collider causal sub-segments, respectively. Their outputs are then combined to produce the final prediction. Extensive experiments on multiple benchmark datasets demonstrate the effectiveness of the CAIFormer.
M2I2: Learning Efficient Multi-Agent Communication via Masked State Modeling and Intention Inference
Dec 31, 2024Communication is essential in coordinating the behaviors of multiple agents. However, existing methods primarily emphasize content, timing, and partners for information sharing, often neglecting the critical aspect of integrating shared information. This gap can significantly impact agents' ability to understand and respond to complex, uncertain interactions, thus affecting overall communication efficiency. To address this issue, we introduce M2I2, a novel framework designed to enhance the agents' capabilities to assimilate and utilize received information effectively. M2I2 equips agents with advanced capabilities for masked state modeling and joint-action prediction, enriching their perception of environmental uncertainties and facilitating the anticipation of teammates' intentions. This approach ensures that agents are furnished with both comprehensive and relevant information, bolstering more informed and synergistic behaviors. Moreover, we propose a Dimensional Rational Network, innovatively trained via a meta-learning paradigm, to identify the importance of dimensional pieces of information, evaluating their contributions to decision-making and auxiliary tasks. Then, we implement an importance-based heuristic for selective information masking and sharing. This strategy optimizes the efficiency of masked state modeling and the rationale behind information sharing. We evaluate M2I2 across diverse multi-agent tasks, the results demonstrate its superior performance, efficiency, and generalization capabilities, over existing state-of-the-art methods in various complex scenarios.
Rethinking Generalizability and Discriminability of Self-Supervised Learning from Evolutionary Game Theory Perspective
Nov 30, 2024



Representations learned by self-supervised approaches are generally considered to possess sufficient generalizability and discriminability. However, we disclose a nontrivial mutual-exclusion relationship between these critical representation properties through an exploratory demonstration on self-supervised learning. State-of-the-art self-supervised methods tend to enhance either generalizability or discriminability but not both simultaneously. Thus, learning representations jointly possessing strong generalizability and discriminability presents a specific challenge for self-supervised learning. To this end, we revisit the learning paradigm of self-supervised learning from the perspective of evolutionary game theory (EGT) and outline the theoretical roadmap to achieve a desired trade-off between these representation properties. EGT performs well in analyzing the trade-off point in a two-player game by utilizing dynamic system modeling. However, the EGT analysis requires sufficient annotated data, which contradicts the principle of self-supervised learning, i.e., the EGT analysis cannot be conducted without the annotations of the specific target domain for self-supervised learning. Thus, to enhance the methodological generalization, we propose a novel self-supervised learning method that leverages advancements in reinforcement learning to jointly benefit from the general guidance of EGT and sequentially optimize the model to chase the consistent improvement of generalizability and discriminability for specific target domains during pre-training. Theoretically, we establish that the proposed method tightens the generalization error upper bound of self-supervised learning. Empirically, our method achieves state-of-the-art performance on various benchmarks.
Proxy-RLHF: Decoupling Generation and Alignment in Large Language Model with Proxy
Mar 07, 2024Reinforcement Learning from Human Feedback (RLHF) is the prevailing approach to ensure Large Language Models (LLMs) align with human values. However, existing RLHF methods require a high computational cost, one main reason being that RLHF assigns both the generation and alignment tasks to the LLM simultaneously. In this paper, we introduce Proxy-RLHF, which decouples the generation and alignment processes of LLMs, achieving alignment with human values at a much lower computational cost. We start with a novel Markov Decision Process (MDP) designed for the alignment process and employ Reinforcement Learning (RL) to train a streamlined proxy model that oversees the token generation of the LLM, without altering the LLM itself. Experiments show that our method achieves a comparable level of alignment with only 1\% of the training parameters of other methods.
T2MAC: Targeted and Trusted Multi-Agent Communication through Selective Engagement and Evidence-Driven Integration
Jan 19, 2024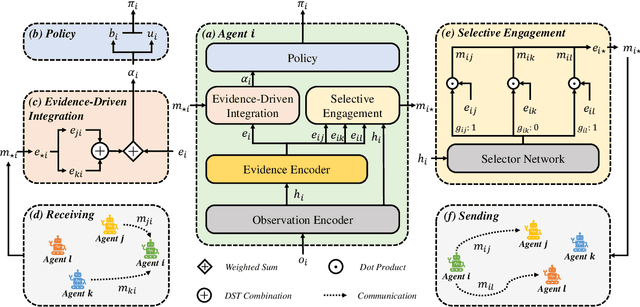
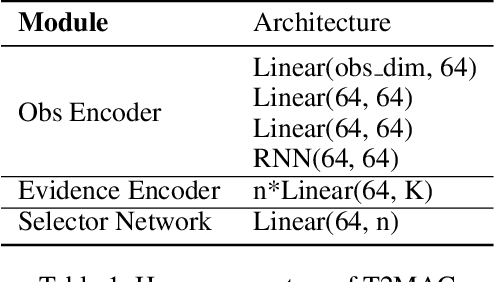
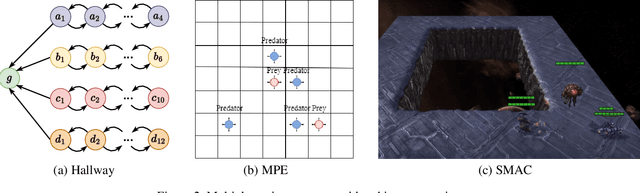
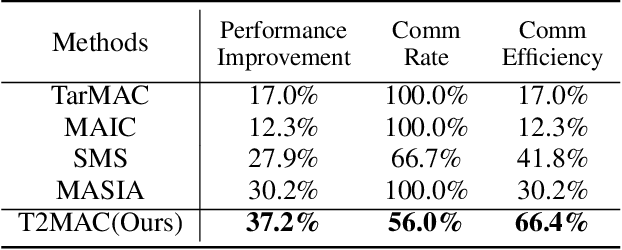
Communication stands as a potent mechanism to harmonize the behaviors of multiple agents. However, existing works primarily concentrate on broadcast communication, which not only lacks practicality, but also leads to information redundancy. This surplus, one-fits-all information could adversely impact the communication efficiency. Furthermore, existing works often resort to basic mechanisms to integrate observed and received information, impairing the learning process. To tackle these difficulties, we propose Targeted and Trusted Multi-Agent Communication (T2MAC), a straightforward yet effective method that enables agents to learn selective engagement and evidence-driven integration. With T2MAC, agents have the capability to craft individualized messages, pinpoint ideal communication windows, and engage with reliable partners, thereby refining communication efficiency. Following the reception of messages, the agents integrate information observed and received from different sources at an evidence level. This process enables agents to collectively use evidence garnered from multiple perspectives, fostering trusted and cooperative behaviors. We evaluate our method on a diverse set of cooperative multi-agent tasks, with varying difficulties, involving different scales and ranging from Hallway, MPE to SMAC. The experiments indicate that the proposed model not only surpasses the state-of-the-art methods in terms of cooperative performance and communication efficiency, but also exhibits impressive generalization.