 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWan: Open and Advanced Large-Scale Video Generative Models
Mar 26, 2025



This report presents Wan, a comprehensive and open suite of video foundation models designed to push the boundaries of video generation. Built upon the mainstream diffusion transformer paradigm, Wan achieves significant advancements in generative capabilities through a series of innovations, including our novel VAE, scalable pre-training strategies, large-scale data curation, and automated evaluation metrics. These contributions collectively enhance the model's performance and versatility. Specifically, Wan is characterized by four key features: Leading Performance: The 14B model of Wan, trained on a vast dataset comprising billions of images and videos, demonstrates the scaling laws of video generation with respect to both data and model size. It consistently outperforms the existing open-source models as well as state-of-the-art commercial solutions across multiple internal and external benchmarks, demonstrating a clear and significant performance superiority. Comprehensiveness: Wan offers two capable models, i.e., 1.3B and 14B parameters, for efficiency and effectiveness respectively. It also covers multiple downstream applications, including image-to-video, instruction-guided video editing, and personal video generation, encompassing up to eight tasks. Consumer-Grade Efficiency: The 1.3B model demonstrates exceptional resource efficiency, requiring only 8.19 GB VRAM, making it compatible with a wide range of consumer-grade GPUs. Openness: We open-source the entire series of Wan, including source code and all models, with the goal of fostering the growth of the video generation community. This openness seeks to significantly expand the creative possibilities of video production in the industry and provide academia with high-quality video foundation models. All the code and models are available at https://github.com/Wan-Video/Wan2.1.
ChatDiT: A Training-Free Baseline for Task-Agnostic Free-Form Chatting with Diffusion Transformers
Dec 17, 2024



Recent research arXiv:2410.15027 arXiv:2410.23775 has highlighted the inherent in-context generation capabilities of pretrained diffusion transformers (DiTs), enabling them to seamlessly adapt to diverse visual tasks with minimal or no architectural modifications. These capabilities are unlocked by concatenating self-attention tokens across multiple input and target images, combined with grouped and masked generation pipelines. Building upon this foundation, we present ChatDiT, a zero-shot, general-purpose, and interactive visual generation framework that leverages pretrained diffusion transformers in their original form, requiring no additional tuning, adapters, or modifications. Users can interact with ChatDiT to create interleaved text-image articles, multi-page picture books, edit images, design IP derivatives, or develop character design settings, all through free-form natural language across one or more conversational rounds. At its core, ChatDiT employs a multi-agent system comprising three key components: an Instruction-Parsing agent that interprets user-uploaded images and instructions, a Strategy-Planning agent that devises single-step or multi-step generation actions, and an Execution agent that performs these actions using an in-context toolkit of diffusion transformers. We thoroughly evaluate ChatDiT on IDEA-Bench arXiv:2412.11767, comprising 100 real-world design tasks and 275 cases with diverse instructions and varying numbers of input and target images. Despite its simplicity and training-free approach, ChatDiT surpasses all competitors, including those specifically designed and trained on extensive multi-task datasets. We further identify key limitations of pretrained DiTs in zero-shot adapting to tasks. We release all code, agents, results, and intermediate outputs to facilitate further research at https://github.com/ali-vilab/ChatDiT
IDEA-Bench: How Far are Generative Models from Professional Designing?
Dec 16, 2024



Real-world design tasks - such as picture book creation, film storyboard development using character sets, photo retouching, visual effects, and font transfer - are highly diverse and complex, requiring deep interpretation and extraction of various elements from instructions, descriptions, and reference images. The resulting images often implicitly capture key features from references or user inputs, making it challenging to develop models that can effectively address such varied tasks. While existing visual generative models can produce high-quality images based on prompts, they face significant limitations in professional design scenarios that involve varied forms and multiple inputs and outputs, even when enhanced with adapters like ControlNets and LoRAs. To address this, we introduce IDEA-Bench, a comprehensive benchmark encompassing 100 real-world design tasks, including rendering, visual effects, storyboarding, picture books, fonts, style-based, and identity-preserving generation, with 275 test cases to thoroughly evaluate a model's general-purpose generation capabilities. Notably, even the best-performing model only achieves 22.48 on IDEA-Bench, while the best general-purpose model only achieves 6.81. We provide a detailed analysis of these results, highlighting the inherent challenges and providing actionable directions for improvement. Additionally, we provide a subset of 18 representative tasks equipped with multimodal large language model (MLLM)-based auto-evaluation techniques to facilitate rapid model development and comparison. We releases the benchmark data, evaluation toolkits, and an online leaderboard at https://github.com/ali-vilab/IDEA-Bench, aiming to drive the advancement of generative models toward more versatile and applicable intelligent design systems.
In-Context LoRA for Diffusion Transformers
Oct 31, 2024



Recent research arXiv:2410.15027 has explored the use of diffusion transformers (DiTs) for task-agnostic image generation by simply concatenating attention tokens across images. However, despite substantial computational resources, the fidelity of the generated images remains suboptimal. In this study, we reevaluate and streamline this framework by hypothesizing that text-to-image DiTs inherently possess in-context generation capabilities, requiring only minimal tuning to activate them. Through diverse task experiments, we qualitatively demonstrate that existing text-to-image DiTs can effectively perform in-context generation without any tuning. Building on this insight, we propose a remarkably simple pipeline to leverage the in-context abilities of DiTs: (1) concatenate images instead of tokens, (2) perform joint captioning of multiple images, and (3) apply task-specific LoRA tuning using small datasets (e.g., $20\sim 100$ samples) instead of full-parameter tuning with large datasets. We name our models In-Context LoRA (IC-LoRA). This approach requires no modifications to the original DiT models, only changes to the training data. Remarkably, our pipeline generates high-fidelity image sets that better adhere to prompts. While task-specific in terms of tuning data, our framework remains task-agnostic in architecture and pipeline, offering a powerful tool for the community and providing valuable insights for further research on product-level task-agnostic generation systems. We release our code, data, and models at https://github.com/ali-vilab/In-Context-LoRA
Group Diffusion Transformers are Unsupervised Multitask Learners
Oct 19, 2024
While large language models (LLMs) have revolutionized natural language processing with their task-agnostic capabilities, visual generation tasks such as image translation, style transfer, and character customization still rely heavily on supervised, task-specific datasets. In this work, we introduce Group Diffusion Transformers (GDTs), a novel framework that unifies diverse visual generation tasks by redefining them as a group generation problem. In this approach, a set of related images is generated simultaneously, optionally conditioned on a subset of the group. GDTs build upon diffusion transformers with minimal architectural modifications by concatenating self-attention tokens across images. This allows the model to implicitly capture cross-image relationships (e.g., identities, styles, layouts, surroundings, and color schemes) through caption-based correlations. Our design enables scalable, unsupervised, and task-agnostic pretraining using extensive collections of image groups sourced from multimodal internet articles, image galleries, and video frames. We evaluate GDTs on a comprehensive benchmark featuring over 200 instructions across 30 distinct visual generation tasks, including picture book creation, font design, style transfer, sketching, colorization, drawing sequence generation, and character customization. Our models achieve competitive zero-shot performance without any additional fine-tuning or gradient updates. Furthermore, ablation studies confirm the effectiveness of key components such as data scaling, group size, and model design. These results demonstrate the potential of GDTs as scalable, general-purpose visual generation systems.
FlashFace: Human Image Personalization with High-fidelity Identity Preservation
Mar 25, 2024



This work presents FlashFace, a practical tool with which users can easily personalize their own photos on the fly by providing one or a few reference face images and a text prompt. Our approach is distinguishable from existing human photo customization methods by higher-fidelity identity preservation and better instruction following, benefiting from two subtle designs. First, we encode the face identity into a series of feature maps instead of one image token as in prior arts, allowing the model to retain more details of the reference faces (e.g., scars, tattoos, and face shape ). Second, we introduce a disentangled integration strategy to balance the text and image guidance during the text-to-image generation process, alleviating the conflict between the reference faces and the text prompts (e.g., personalizing an adult into a "child" or an "elder"). Extensive experimental results demonstrate the effectiveness of our method on various applications, including human image personalization, face swapping under language prompts, making virtual characters into real people, etc. Project Page: https://jshilong.github.io/flashface-page.
Grow and Merge: A Unified Framework for Continuous Categories Discovery
Oct 09, 2022

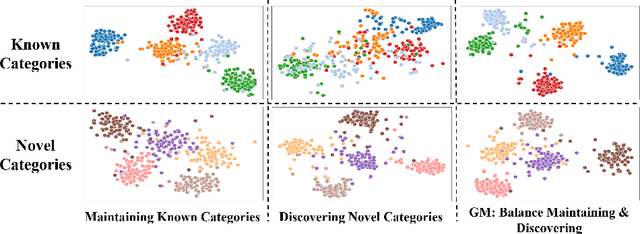
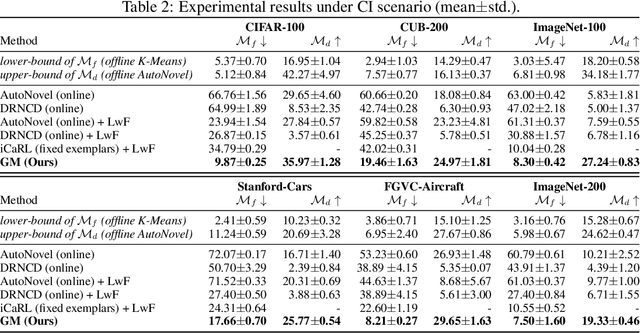
Although a number of studies are devoted to novel category discovery, most of them assume a static setting where both labeled and unlabeled data are given at once for finding new categories. In this work, we focus on the application scenarios where unlabeled data are continuously fed into the category discovery system. We refer to it as the {\bf Continuous Category Discovery} ({\bf CCD}) problem, which is significantly more challenging than the static setting. A common challenge faced by novel category discovery is that different sets of features are needed for classification and category discovery: class discriminative features are preferred for classification, while rich and diverse features are more suitable for new category mining. This challenge becomes more severe for dynamic setting as the system is asked to deliver good performance for known classes over time, and at the same time continuously discover new classes from unlabeled data. To address this challenge, we develop a framework of {\bf Grow and Merge} ({\bf GM}) that works by alternating between a growing phase and a merging phase: in the growing phase, it increases the diversity of features through a continuous self-supervised learning for effective category mining, and in the merging phase, it merges the grown model with a static one to ensure satisfying performance for known classes. Our extensive studies verify that the proposed GM framework is significantly more effective than the state-of-the-art approaches for continuous category discovery.
NGC: A Unified Framework for Learning with Open-World Noisy Data
Aug 25, 2021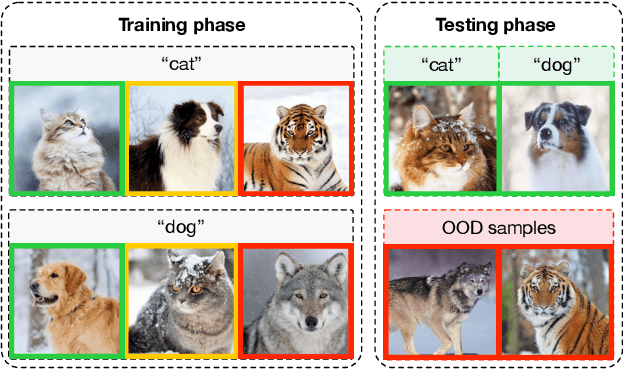
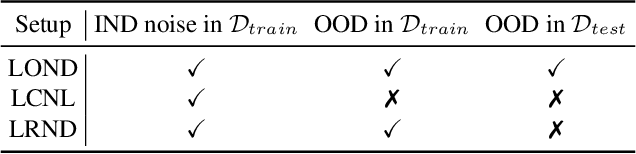
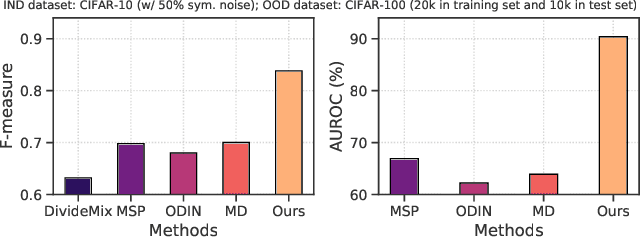
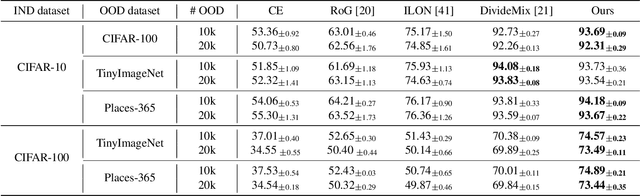
The existence of noisy data is prevalent in both the training and testing phases of machine learning systems, which inevitably leads to the degradation of model performance. There have been plenty of works concentrated on learning with in-distribution (IND) noisy labels in the last decade, i.e., some training samples are assigned incorrect labels that do not correspond to their true classes. Nonetheless, in real application scenarios, it is necessary to consider the influence of out-of-distribution (OOD) samples, i.e., samples that do not belong to any known classes, which has not been sufficiently explored yet. To remedy this, we study a new problem setup, namely Learning with Open-world Noisy Data (LOND). The goal of LOND is to simultaneously learn a classifier and an OOD detector from datasets with mixed IND and OOD noise. In this paper, we propose a new graph-based framework, namely Noisy Graph Cleaning (NGC), which collects clean samples by leveraging geometric structure of data and model predictive confidence. Without any additional training effort, NGC can detect and reject the OOD samples based on the learned class prototypes directly in testing phase. We conduct experiments on multiple benchmarks with different types of noise and the results demonstrate the superior performance of our method against state of the arts.