 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWan-Image: Pushing the Boundaries of Generative Visual Intelligence
Apr 21, 2026We present Wan-Image, a unified visual generation system explicitly engineered to paradigm-shift image generation models from casual synthesizers into professional-grade productivity tools. While contemporary diffusion models excel at aesthetic generation, they frequently encounter critical bottlenecks in rigorous design workflows that demand absolute controllability, complex typography rendering, and strict identity preservation. To address these challenges, Wan-Image features a natively unified multi-modal architecture by synergizing the cognitive capabilities of large language models with the high-fidelity pixel synthesis of diffusion transformers, which seamlessly translates highly nuanced user intents into precise visual outputs. It is fundamentally powered by large-scale multi-modal data scaling, a systematic fine-grained annotation engine, and curated reinforcement learning data to surpass basic instruction following and unlock expert-level professional capabilities. These include ultra-long complex text rendering, hyper-diverse portrait generation, palette-guided generation, multi-subject identity preservation, coherent sequential visual generation, precise multi-modal interactive editing, native alpha-channel generation, and high-efficiency 4K synthesis. Across diverse human evaluations, Wan-Image exceeds Seedream 5.0 Lite and GPT Image 1.5 in overall performance, reaching parity with Nano Banana Pro in challenging tasks. Ultimately, Wan-Image revolutionizes visual content creation across e-commerce, entertainment, education, and personal productivity, redefining the boundaries of professional visual synthesis.
Wan-Weaver: Interleaved Multi-modal Generation via Decoupled Training
Mar 26, 2026Recent unified models have made unprecedented progress in both understanding and generation. However, while most of them accept multi-modal inputs, they typically produce only single-modality outputs. This challenge of producing interleaved content is mainly due to training data scarcity and the difficulty of modeling long-range cross-modal context. To address this issue, we decompose interleaved generation into textual planning and visual consistency modeling, and introduce a framework consisting of a planner and a visualizer. The planner produces dense textual descriptions for visual content, while the visualizer synthesizes images accordingly. Under this guidance, we construct large-scale textual-proxy interleaved data (where visual content is represented in text) to train the planner, and curate reference-guided image data to train the visualizer. These designs give rise to Wan-Weaver, which exhibits emergent interleaved generation ability with long-range textual coherence and visual consistency. Meanwhile, the integration of diverse understanding and generation data into planner training enables Wan-Weaver to achieve robust task reasoning and generation proficiency. To assess the model's capability in interleaved generation, we further construct a benchmark that spans a wide range of use cases across multiple dimensions. Extensive experiments demonstrate that, even without access to any real interleaved data, Wan-Weaver achieves superior performance over existing methods.
Beyond Endpoints: Path-Centric Reasoning for Vectorized Off-Road Network Extraction
Dec 12, 2025Deep learning has advanced vectorized road extraction in urban settings, yet off-road environments remain underexplored and challenging. A significant domain gap causes advanced models to fail in wild terrains due to two key issues: lack of large-scale vectorized datasets and structural weakness in prevailing methods. Models such as SAM-Road employ a node-centric paradigm that reasons at sparse endpoints, making them fragile to occlusions and ambiguous junctions in off-road scenes, leading to topological errors. This work addresses these limitations in two complementary ways. First, we release WildRoad, a global off-road road network dataset constructed efficiently with a dedicated interactive annotation tool tailored for road-network labeling. Second, we introduce MaGRoad (Mask-aware Geodesic Road network extractor), a path-centric framework that aggregates multi-scale visual evidence along candidate paths to infer connectivity robustly. Extensive experiments show that MaGRoad achieves state-of-the-art performance on our challenging WildRoad benchmark while generalizing well to urban datasets. A streamlined pipeline also yields roughly 2.5x faster inference, improving practical applicability. Together, the dataset and path-centric paradigm provide a stronger foundation for mapping roads in the wild. We release both the dataset and code at https://github.com/xiaofei-guan/MaGRoad.
E-MMDiT: Revisiting Multimodal Diffusion Transformer Design for Fast Image Synthesis under Limited Resources
Oct 31, 2025Diffusion models have shown strong capabilities in generating high-quality images from text prompts. However, these models often require large-scale training data and significant computational resources to train, or suffer from heavy structure with high latency. To this end, we propose Efficient Multimodal Diffusion Transformer (E-MMDiT), an efficient and lightweight multimodal diffusion model with only 304M parameters for fast image synthesis requiring low training resources. We provide an easily reproducible baseline with competitive results. Our model for 512px generation, trained with only 25M public data in 1.5 days on a single node of 8 AMD MI300X GPUs, achieves 0.66 on GenEval and easily reaches to 0.72 with some post-training techniques such as GRPO. Our design philosophy centers on token reduction as the computational cost scales significantly with the token count. We adopt a highly compressive visual tokenizer to produce a more compact representation and propose a novel multi-path compression module for further compression of tokens. To enhance our design, we introduce Position Reinforcement, which strengthens positional information to maintain spatial coherence, and Alternating Subregion Attention (ASA), which performs attention within subregions to further reduce computational cost. In addition, we propose AdaLN-affine, an efficient lightweight module for computing modulation parameters in transformer blocks. Our code is available at https://github.com/AMD-AGI/Nitro-E and we hope E-MMDiT serves as a strong and practical baseline for future research and contributes to democratization of generative AI models.
Wan: Open and Advanced Large-Scale Video Generative Models
Mar 26, 2025



This report presents Wan, a comprehensive and open suite of video foundation models designed to push the boundaries of video generation. Built upon the mainstream diffusion transformer paradigm, Wan achieves significant advancements in generative capabilities through a series of innovations, including our novel VAE, scalable pre-training strategies, large-scale data curation, and automated evaluation metrics. These contributions collectively enhance the model's performance and versatility. Specifically, Wan is characterized by four key features: Leading Performance: The 14B model of Wan, trained on a vast dataset comprising billions of images and videos, demonstrates the scaling laws of video generation with respect to both data and model size. It consistently outperforms the existing open-source models as well as state-of-the-art commercial solutions across multiple internal and external benchmarks, demonstrating a clear and significant performance superiority. Comprehensiveness: Wan offers two capable models, i.e., 1.3B and 14B parameters, for efficiency and effectiveness respectively. It also covers multiple downstream applications, including image-to-video, instruction-guided video editing, and personal video generation, encompassing up to eight tasks. Consumer-Grade Efficiency: The 1.3B model demonstrates exceptional resource efficiency, requiring only 8.19 GB VRAM, making it compatible with a wide range of consumer-grade GPUs. Openness: We open-source the entire series of Wan, including source code and all models, with the goal of fostering the growth of the video generation community. This openness seeks to significantly expand the creative possibilities of video production in the industry and provide academia with high-quality video foundation models. All the code and models are available at https://github.com/Wan-Video/Wan2.1.
ChatDiT: A Training-Free Baseline for Task-Agnostic Free-Form Chatting with Diffusion Transformers
Dec 17, 2024



Recent research arXiv:2410.15027 arXiv:2410.23775 has highlighted the inherent in-context generation capabilities of pretrained diffusion transformers (DiTs), enabling them to seamlessly adapt to diverse visual tasks with minimal or no architectural modifications. These capabilities are unlocked by concatenating self-attention tokens across multiple input and target images, combined with grouped and masked generation pipelines. Building upon this foundation, we present ChatDiT, a zero-shot, general-purpose, and interactive visual generation framework that leverages pretrained diffusion transformers in their original form, requiring no additional tuning, adapters, or modifications. Users can interact with ChatDiT to create interleaved text-image articles, multi-page picture books, edit images, design IP derivatives, or develop character design settings, all through free-form natural language across one or more conversational rounds. At its core, ChatDiT employs a multi-agent system comprising three key components: an Instruction-Parsing agent that interprets user-uploaded images and instructions, a Strategy-Planning agent that devises single-step or multi-step generation actions, and an Execution agent that performs these actions using an in-context toolkit of diffusion transformers. We thoroughly evaluate ChatDiT on IDEA-Bench arXiv:2412.11767, comprising 100 real-world design tasks and 275 cases with diverse instructions and varying numbers of input and target images. Despite its simplicity and training-free approach, ChatDiT surpasses all competitors, including those specifically designed and trained on extensive multi-task datasets. We further identify key limitations of pretrained DiTs in zero-shot adapting to tasks. We release all code, agents, results, and intermediate outputs to facilitate further research at https://github.com/ali-vilab/ChatDiT
LADDER: An Efficient Framework for Video Frame Interpolation
Apr 17, 2024



Video Frame Interpolation (VFI) is a crucial technique in various applications such as slow-motion generation, frame rate conversion, video frame restoration etc. This paper introduces an efficient video frame interpolation framework that aims to strike a favorable balance between efficiency and quality. Our framework follows a general paradigm consisting of a flow estimator and a refinement module, while incorporating carefully designed components. First of all, we adopt depth-wise convolution with large kernels in the flow estimator that simultaneously reduces the parameters and enhances the receptive field for encoding rich context and handling complex motion. Secondly, diverging from a common design for the refinement module with a UNet-structure (encoder-decoder structure), which we find redundant, our decoder-only refinement module directly enhances the result from coarse to fine features, offering a more efficient process. In addition, to address the challenge of handling high-definition frames, we also introduce an innovative HD-aware augmentation strategy during training, leading to consistent enhancement on HD images. Extensive experiments are conducted on diverse datasets, Vimeo90K, UCF101, Xiph and SNU-FILM. The results demonstrate that our approach achieves state-of-the-art performance with clear improvement while requiring much less FLOPs and parameters, reaching to a better spot for balancing efficiency and quality.
A Novel Autonomous Robotics System for Aquaculture Environment Monitoring
Nov 08, 2022
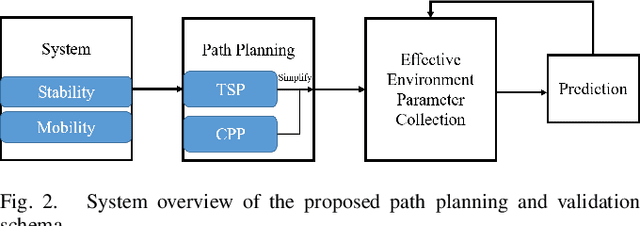
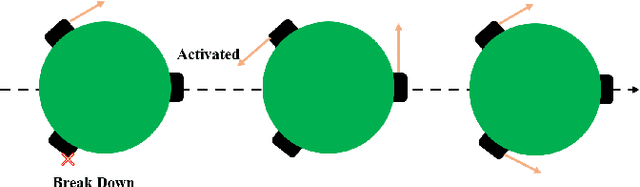
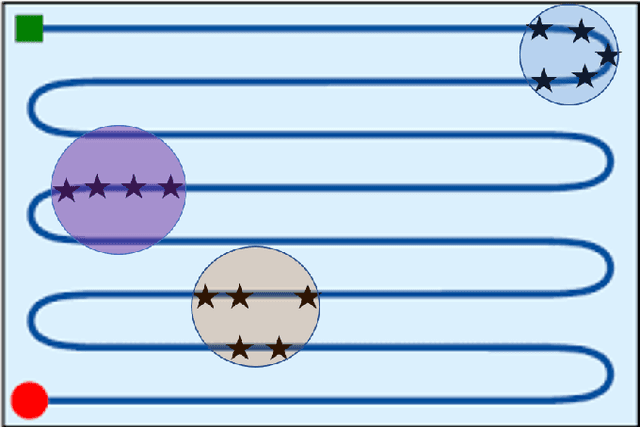
Implementing fully automatic unmanned surface vehicles (USVs) monitoring water quality is challenging since effectively collecting environmental data while keeping the platform stable and environmental-friendly is hard to approach. To address this problem, we construct a USV that can automatically navigate an efficient path to sample water quality parameters in order to monitor the aquatic environment. The detection device needs to be stable enough to resist a hostile environment or climates while enormous volumes will disturb the aquaculture environment. Meanwhile, planning an efficient path for information collecting needs to deal with the contradiction between the restriction of energy and the amount of information in the coverage region. To tackle with mentioned challenges, we provide a USV platform that can perfectly balance mobility, stability, and portability attributed to its special round-shape structure and redundancy motion design. For informative planning, we combined the TSP and CPP algorithms to construct an optimistic plan for collecting more data within a certain range and limiting energy restrictions.We designed a fish existence prediction scenario to verify the novel system in both simulation experiments and field experiments. The novel aquaculture environment monitoring system significantly reduces the burden of manual operation in the fishery inspection field. Additionally, the simplicity of the sensor setup and the minimal cost of the platform enables its other possible applications in aquatic exploration and commercial utilization.
ViDA-MAN: Visual Dialog with Digital Humans
Oct 26, 2021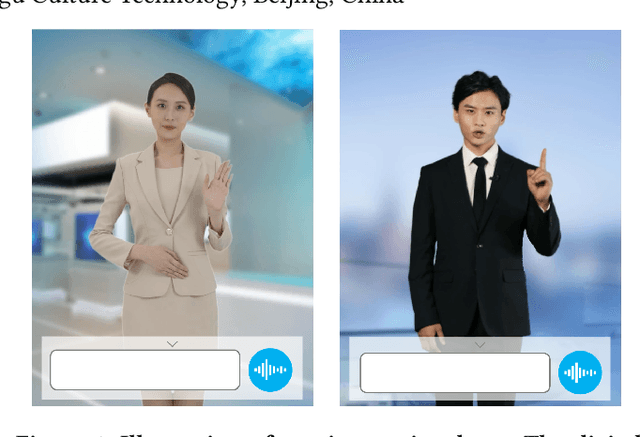
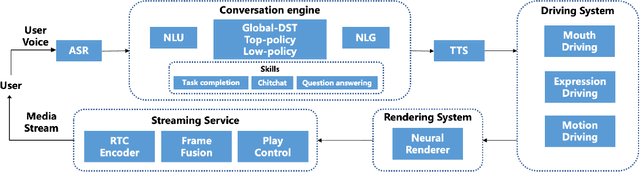
We demonstrate ViDA-MAN, a digital-human agent for multi-modal interaction, which offers realtime audio-visual responses to instant speech inquiries. Compared to traditional text or voice-based system, ViDA-MAN offers human-like interactions (e.g, vivid voice, natural facial expression and body gestures). Given a speech request, the demonstration is able to response with high quality videos in sub-second latency. To deliver immersive user experience, ViDA-MAN seamlessly integrates multi-modal techniques including Acoustic Speech Recognition (ASR), multi-turn dialog, Text To Speech (TTS), talking heads video generation. Backed with large knowledge base, ViDA-MAN is able to chat with users on a number of topics including chit-chat, weather, device control, News recommendations, booking hotels, as well as answering questions via structured knowledge.
Deep Person Generation: A Survey from the Perspective of Face, Pose and Cloth Synthesis
Sep 05, 2021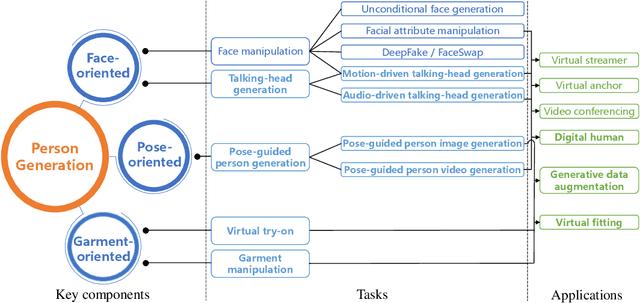



Deep person generation has attracted extensive research attention due to its wide applications in virtual agents, video conferencing, online shopping and art/movie production. With the advancement of deep learning, visual appearances (face, pose, cloth) of a person image can be easily generated or manipulated on demand. In this survey, we first summarize the scope of person generation, and then systematically review recent progress and technical trends in deep person generation, covering three major tasks: talking-head generation (face), pose-guided person generation (pose) and garment-oriented person generation (cloth). More than two hundred papers are covered for a thorough overview, and the milestone works are highlighted to witness the major technical breakthrough. Based on these fundamental tasks, a number of applications are investigated, e.g., virtual fitting, digital human, generative data augmentation. We hope this survey could shed some light on the future prospects of deep person generation, and provide a helpful foundation for full applications towards digital human.