 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGLADformer: A Mixed Perspective for Graph-level Anomaly Detection
Jun 02, 2024Graph-Level Anomaly Detection (GLAD) aims to distinguish anomalous graphs within a graph dataset. However, current methods are constrained by their receptive fields, struggling to learn global features within the graphs. Moreover, most contemporary methods are based on spatial domain and lack exploration of spectral characteristics. In this paper, we propose a multi-perspective hybrid graph-level anomaly detector namely GLADformer, consisting of two key modules. Specifically, we first design a Graph Transformer module with global spectrum enhancement, which ensures balanced and resilient parameter distributions by fusing global features and spectral distribution characteristics. Furthermore, to uncover local anomalous attributes, we customize a band-pass spectral GNN message passing module that further enhances the model's generalization capability. Through comprehensive experiments on ten real-world datasets from multiple domains, we validate the effectiveness and robustness of GLADformer. This demonstrates that GLADformer outperforms current state-of-the-art models in graph-level anomaly detection, particularly in effectively capturing global anomaly representations and spectral characteristics.
Perturbing Attention Gives You More Bang for the Buck: Subtle Imaging Perturbations That Efficiently Fool Customized Diffusion Models
Apr 23, 2024


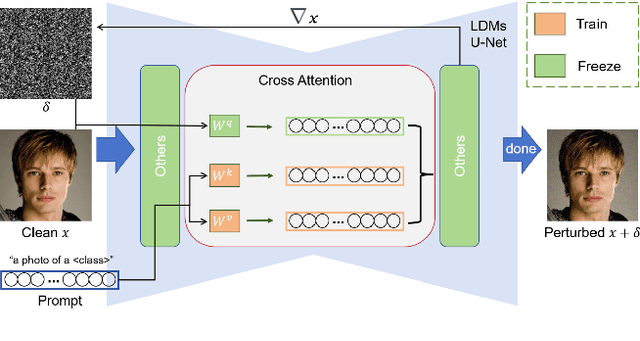
Diffusion models (DMs) embark a new era of generative modeling and offer more opportunities for efficient generating high-quality and realistic data samples. However, their widespread use has also brought forth new challenges in model security, which motivates the creation of more effective adversarial attackers on DMs to understand its vulnerability. We propose CAAT, a simple but generic and efficient approach that does not require costly training to effectively fool latent diffusion models (LDMs). The approach is based on the observation that cross-attention layers exhibits higher sensitivity to gradient change, allowing for leveraging subtle perturbations on published images to significantly corrupt the generated images. We show that a subtle perturbation on an image can significantly impact the cross-attention layers, thus changing the mapping between text and image during the fine-tuning of customized diffusion models. Extensive experiments demonstrate that CAAT is compatible with diverse diffusion models and outperforms baseline attack methods in a more effective (more noise) and efficient (twice as fast as Anti-DreamBooth and Mist) manner.