 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLCGC: Learning from Consistency Gradient Conflicting for Class-Imbalanced Semi-Supervised Debiasing
Apr 09, 2025Classifiers often learn to be biased corresponding to the class-imbalanced dataset, especially under the semi-supervised learning (SSL) set. While previous work tries to appropriately re-balance the classifiers by subtracting a class-irrelevant image's logit, but lacks a firm theoretical basis. We theoretically analyze why exploiting a baseline image can refine pseudo-labels and prove that the black image is the best choice. We also indicated that as the training process deepens, the pseudo-labels before and after refinement become closer. Based on this observation, we propose a debiasing scheme dubbed LCGC, which Learning from Consistency Gradient Conflicting, by encouraging biased class predictions during training. We intentionally update the pseudo-labels whose gradient conflicts with the debiased logits, representing the optimization direction offered by the over-imbalanced classifier predictions. Then, we debiased the predictions by subtracting the baseline image logits during testing. Extensive experiments demonstrate that LCGC can significantly improve the prediction accuracy of existing CISSL models on public benchmarks.
Exploring Few-Shot Defect Segmentation in General Industrial Scenarios with Metric Learning and Vision Foundation Models
Feb 03, 2025



Industrial defect segmentation is critical for manufacturing quality control. Due to the scarcity of training defect samples, few-shot semantic segmentation (FSS) holds significant value in this field. However, existing studies mostly apply FSS to tackle defects on simple textures, without considering more diverse scenarios. This paper aims to address this gap by exploring FSS in broader industrial products with various defect types. To this end, we contribute a new real-world dataset and reorganize some existing datasets to build a more comprehensive few-shot defect segmentation (FDS) benchmark. On this benchmark, we thoroughly investigate metric learning-based FSS methods, including those based on meta-learning and those based on Vision Foundation Models (VFMs). We observe that existing meta-learning-based methods are generally not well-suited for this task, while VFMs hold great potential. We further systematically study the applicability of various VFMs in this task, involving two paradigms: feature matching and the use of Segment Anything (SAM) models. We propose a novel efficient FDS method based on feature matching. Meanwhile, we find that SAM2 is particularly effective for addressing FDS through its video track mode. The contributed dataset and code will be available at: https://github.com/liutongkun/GFDS.
AutoDSL: Automated domain-specific language design for structural representation of procedures with constraints
Jun 18, 2024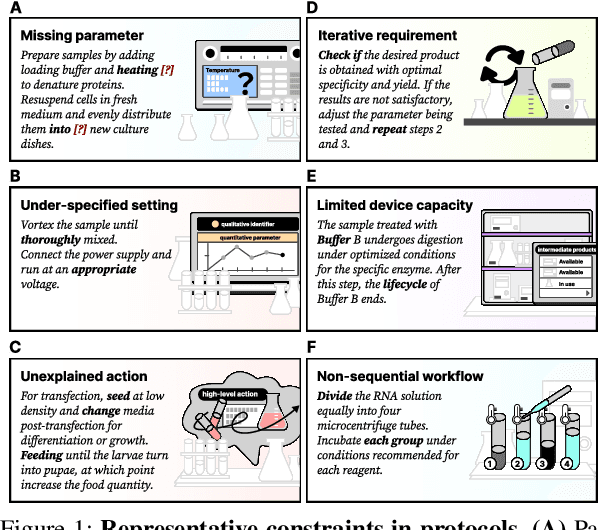



Accurate representation of procedures in restricted scenarios, such as non-standardized scientific experiments, requires precise depiction of constraints. Unfortunately, Domain-specific Language (DSL), as an effective tool to express constraints structurally, often requires case-by-case hand-crafting, necessitating customized, labor-intensive efforts. To overcome this challenge, we introduce the AutoDSL framework to automate DSL-based constraint design across various domains. Utilizing domain specified experimental protocol corpora, AutoDSL optimizes syntactic constraints and abstracts semantic constraints. Quantitative and qualitative analyses of the DSLs designed by AutoDSL across five distinct domains highlight its potential as an auxiliary module for language models, aiming to improve procedural planning and execution.
Perturbing Attention Gives You More Bang for the Buck: Subtle Imaging Perturbations That Efficiently Fool Customized Diffusion Models
Apr 23, 2024


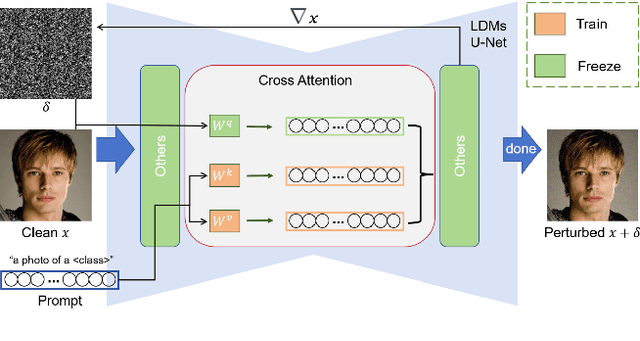
Diffusion models (DMs) embark a new era of generative modeling and offer more opportunities for efficient generating high-quality and realistic data samples. However, their widespread use has also brought forth new challenges in model security, which motivates the creation of more effective adversarial attackers on DMs to understand its vulnerability. We propose CAAT, a simple but generic and efficient approach that does not require costly training to effectively fool latent diffusion models (LDMs). The approach is based on the observation that cross-attention layers exhibits higher sensitivity to gradient change, allowing for leveraging subtle perturbations on published images to significantly corrupt the generated images. We show that a subtle perturbation on an image can significantly impact the cross-attention layers, thus changing the mapping between text and image during the fine-tuning of customized diffusion models. Extensive experiments demonstrate that CAAT is compatible with diverse diffusion models and outperforms baseline attack methods in a more effective (more noise) and efficient (twice as fast as Anti-DreamBooth and Mist) manner.
TransGPT: Multi-modal Generative Pre-trained Transformer for Transportation
Feb 11, 2024



Natural language processing (NLP) is a key component of intelligent transportation systems (ITS), but it faces many challenges in the transportation domain, such as domain-specific knowledge and data, and multi-modal inputs and outputs. This paper presents TransGPT, a novel (multi-modal) large language model for the transportation domain, which consists of two independent variants: TransGPT-SM for single-modal data and TransGPT-MM for multi-modal data. TransGPT-SM is finetuned on a single-modal Transportation dataset (STD) that contains textual data from various sources in the transportation domain. TransGPT-MM is finetuned on a multi-modal Transportation dataset (MTD) that we manually collected from three areas of the transportation domain: driving tests, traffic signs, and landmarks. We evaluate TransGPT on several benchmark datasets for different tasks in the transportation domain, and show that it outperforms baseline models on most tasks. We also showcase the potential applications of TransGPT for traffic analysis and modeling, such as generating synthetic traffic scenarios, explaining traffic phenomena, answering traffic-related questions, providing traffic recommendations, and generating traffic reports. This work advances the state-of-the-art of NLP in the transportation domain and provides a useful tool for ITS researchers and practitioners.
DoDo-Code: a Deep Levenshtein Distance Embedding-based Code for IDS Channel and DNA Storage
Dec 20, 2023Recently, DNA storage has emerged as a promising data storage solution, offering significant advantages in storage density, maintenance cost efficiency, and parallel replication capability. Mathematically, the DNA storage pipeline can be viewed as an insertion, deletion, and substitution (IDS) channel. Because of the mathematical terra incognita of the Levenshtein distance, designing an IDS-correcting code is still a challenge. In this paper, we propose an innovative approach that utilizes deep Levenshtein distance embedding to bypass these mathematical challenges. By representing the Levenshtein distance between two sequences as a conventional distance between their corresponding embedding vectors, the inherent structural property of Levenshtein distance is revealed in the friendly embedding space. Leveraging this embedding space, we introduce the DoDo-Code, an IDS-correcting code that incorporates deep embedding of Levenshtein distance, deep embedding-based codeword search, and deep embedding-based segment correcting. To address the requirements of DNA storage, we also present a preliminary algorithm for long sequence decoding. As far as we know, the DoDo-Code is the first IDS-correcting code designed using plausible deep learning methodologies, potentially paving the way for a new direction in error-correcting code research. It is also the first IDS code that exhibits characteristics of being `optimal' in terms of redundancy, significantly outperforming the mainstream IDS-correcting codes of the Varshamov-Tenengolts code family in code rate.
Levenshtein Distance Embedding with Poisson Regression for DNA Storage
Dec 13, 2023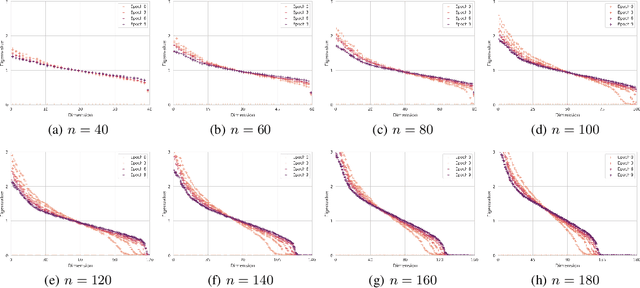
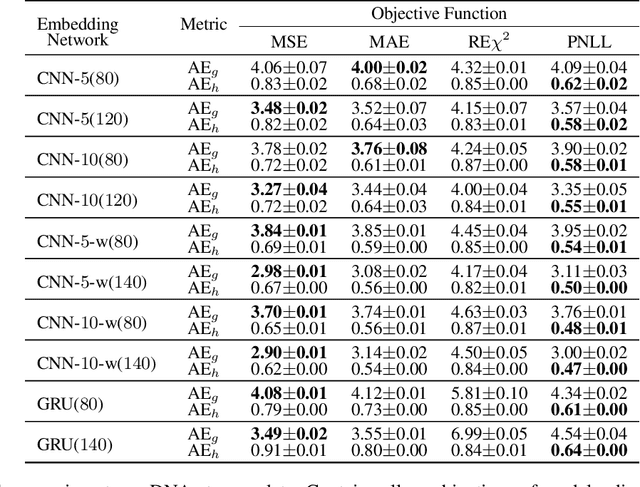
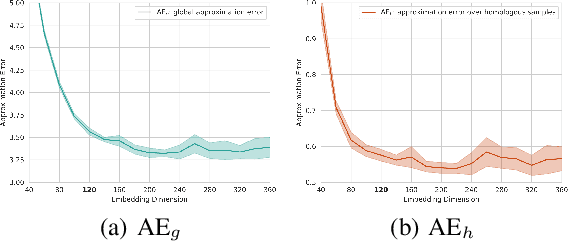
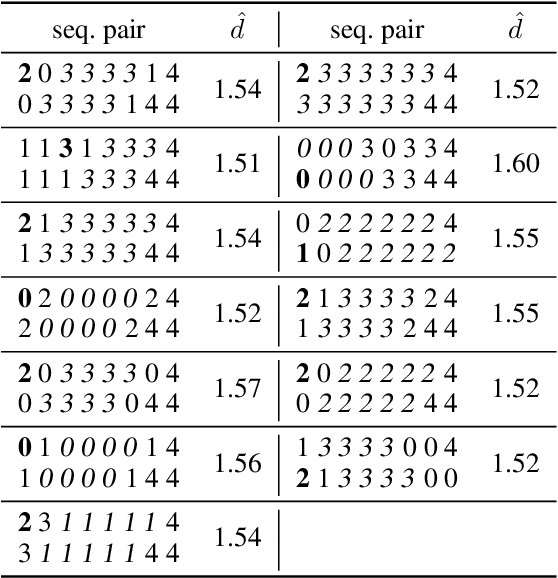
Efficient computation or approximation of Levenshtein distance, a widely-used metric for evaluating sequence similarity, has attracted significant attention with the emergence of DNA storage and other biological applications. Sequence embedding, which maps Levenshtein distance to a conventional distance between embedding vectors, has emerged as a promising solution. In this paper, a novel neural network-based sequence embedding technique using Poisson regression is proposed. We first provide a theoretical analysis of the impact of embedding dimension on model performance and present a criterion for selecting an appropriate embedding dimension. Under this embedding dimension, the Poisson regression is introduced by assuming the Levenshtein distance between sequences of fixed length following a Poisson distribution, which naturally aligns with the definition of Levenshtein distance. Moreover, from the perspective of the distribution of embedding distances, Poisson regression approximates the negative log likelihood of the chi-squared distribution and offers advancements in removing the skewness. Through comprehensive experiments on real DNA storage data, we demonstrate the superior performance of the proposed method compared to state-of-the-art approaches.
CollabKG: A Learnable Human-Machine-Cooperative Information Extraction Toolkit for (Event) Knowledge Graph Construction
Jul 03, 2023



In order to construct or extend entity-centric and event-centric knowledge graphs (KG and EKG), the information extraction (IE) annotation toolkit is essential. However, existing IE toolkits have several non-trivial problems, such as not supporting multi-tasks, not supporting automatic updates. In this work, we present CollabKG, a learnable human-machine-cooperative IE toolkit for KG and EKG construction. Specifically, for the multi-task issue, CollabKG unifies different IE subtasks, including named entity recognition (NER), entity-relation triple extraction (RE), and event extraction (EE), and supports both KG and EKG. Then, combining advanced prompting-based IE technology, the human-machine-cooperation mechanism with LLMs as the assistant machine is presented which can provide a lower cost as well as a higher performance. Lastly, owing to the two-way interaction between the human and machine, CollabKG with learning ability allows self-renewal. Besides, CollabKG has several appealing features (e.g., customization, training-free, propagation, etc.) that make the system powerful, easy-to-use, and high-productivity. We holistically compare our toolkit with other existing tools on these features. Human evaluation quantitatively illustrates that CollabKG significantly improves annotation quality, efficiency, and stability simultaneously.
Prompt What You Need: Enhancing Segmentation in Rainy Scenes with Anchor-based Prompting
May 12, 2023Semantic segmentation in rainy scenes is a challenging task due to the complex environment, class distribution imbalance, and limited annotated data. To address these challenges, we propose a novel framework that utilizes semi-supervised learning and pre-trained segmentation foundation model to achieve superior performance. Specifically, our framework leverages the semi-supervised model as the basis for generating raw semantic segmentation results, while also serving as a guiding force to prompt pre-trained foundation model to compensate for knowledge gaps with entropy-based anchors. In addition, to minimize the impact of irrelevant segmentation masks generated by the pre-trained foundation model, we also propose a mask filtering and fusion mechanism that optimizes raw semantic segmentation results based on the principle of minimum risk. The proposed framework achieves superior segmentation performance on the Rainy WCity dataset and is awarded the first prize in the sub-track of STRAIN in ICME 2023 Grand Challenges.
Zero-Shot Information Extraction via Chatting with ChatGPT
Feb 20, 2023



Zero-shot information extraction (IE) aims to build IE systems from the unannotated text. It is challenging due to involving little human intervention. Challenging but worthwhile, zero-shot IE reduces the time and effort that data labeling takes. Recent efforts on large language models (LLMs, e.g., GPT-3, ChatGPT) show promising performance on zero-shot settings, thus inspiring us to explore prompt-based methods. In this work, we ask whether strong IE models can be constructed by directly prompting LLMs. Specifically, we transform the zero-shot IE task into a multi-turn question-answering problem with a two-stage framework (ChatIE). With the power of ChatGPT, we extensively evaluate our framework on three IE tasks: entity-relation triple extract, named entity recognition, and event extraction. Empirical results on six datasets across two languages show that ChatIE achieves impressive performance and even surpasses some full-shot models on several datasets (e.g., NYT11-HRL). We believe that our work could shed light on building IE models with limited resources.