 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGmd: Gaussian mixture descriptor for pair matching of 3D fragments
Apr 23, 2026In the automatic reassembly of fragments acquired using laser scanners to reconstruct objects, a crucial step is the matching of fractured surfaces. In this paper, we propose a novel local descriptor that uses the Gaussian Mixture Model (GMM) to fit the distribution of points, allowing for the description and matching of fractured surfaces of fragments. Our method involves dividing a local surface patch into concave and convex regions for estimating the k value of GMM. Then the final Gaussian Mixture Descriptor (GMD) of the fractured surface is formed by merging the regional GMDs. To measure the similarities between GMDs for determining adjacent fragments, we employ the L2 distance and align the fragments using Random Sample Consensus (RANSAC) and Iterative Closest Point (ICP). The extensive experiments on real-scanned public datasets and Terracotta datasets demonstrate the effectiveness of our approach; furthermore, the comparisons with several existing methods also validate the advantage of the proposed method.
* 24 pages, 10 figures. Published in Multimedia Systems
Random Walk on Point Clouds for Feature Detection
Apr 22, 2026The points on the point clouds that can entirely outline the shape of the model are of critical importance, as they serve as the foundation for numerous point cloud processing tasks and are widely utilized in computer graphics and computer-aided design. This study introduces a novel method, RWoDSN, for extracting such feature points, incorporating considerations of sharp-to-smooth transitions, large-to-small scales, and textural-to-detailed features. We approach feature extraction as a two-stage context-dependent analysis problem. In the first stage, we propose a novel neighborhood descriptor, termed the Disk Sampling Neighborhood (DSN), which, unlike traditional spatially and geometrically invariant approaches, preserves a matrix structure while maintaining normal neighborhood relationships. In the second stage, a random walk is performed on the DSN (RWoDSN), yielding a graph-based DSN that simultaneously accounts for the spatial distribution, topological properties, and geometric characteristics of the local surface surrounding each point. This enables the effective extraction of feature points. Experimental results demonstrate that the proposed RWoDSN method achieves a recall of 0.769-22% higher than the current state-of-the-art-alongside a precision of 0.784. Furthermore, it significantly outperforms several traditional and deep-learning techniques across eight evaluation metrics.
* 20 pages, 11 figures. Published in Information Sciences
WeatherReasonSeg: A Benchmark for Weather-Aware Reasoning Segmentation in Visual Language Models
Mar 18, 2026Existing vision-language models (VLMs) have demonstrated impressive performance in reasoning-based segmentation. However, current benchmarks are primarily constructed from high-quality images captured under idealized conditions. This raises a critical question: when visual cues are severely degraded by adverse weather conditions such as rain, snow, or fog, can VLMs sustain reliable reasoning segmentation capabilities? In response to this challenge, we introduce WeatherReasonSeg, a benchmark designed to evaluate VLM performance in reasoning-based segmentation under adverse weather conditions. It consists of two complementary components. First, we construct a controllable reasoning dataset by applying synthetic weather with varying severity levels to existing segmentation datasets, enabling fine-grained robustness analysis. Second, to capture real-world complexity, we curate a real-world adverse-weather reasoning segmentation dataset with semantically consistent queries generated via mask-guided LLM prompting. We further broaden the evaluation scope across five reasoning dimensions, including functionality, application scenarios, structural attributes, interactions, and requirement matching. Extensive experiments across diverse VLMs reveal two key findings: (1) VLM performance degrades monotonically with increasing weather severity, and (2) different weather types induce distinct vulnerability patterns. We hope WeatherReasonSeg will serve as a foundation for advancing robust, weather-aware reasoning.
Human Identification at a Distance: Challenges, Methods and Results on the Competition HID 2025
Feb 07, 2026Human identification at a distance (HID) is challenging because traditional biometric modalities such as face and fingerprints are often difficult to acquire in real-world scenarios. Gait recognition provides a practical alternative, as it can be captured reliably at a distance. To promote progress in gait recognition and provide a fair evaluation platform, the International Competition on Human Identification at a Distance (HID) has been organized annually since 2020. Since 2023, the competition has adopted the challenging SUSTech-Competition dataset, which features substantial variations in clothing, carried objects, and view angles. No dedicated training data are provided, requiring participants to train their models using external datasets. Each year, the competition applies a different random seed to generate distinct evaluation splits, which reduces the risk of overfitting and supports a fair assessment of cross-domain generalization. While HID 2023 and HID 2024 already used this dataset, HID 2025 explicitly examined whether algorithmic advances could surpass the accuracy limits observed previously. Despite the heightened difficulty, participants achieved further improvements, and the best-performing method reached 94.2% accuracy, setting a new benchmark on this dataset. We also analyze key technical trends and outline potential directions for future research in gait recognition.
CRTrack: Low-Light Semi-Supervised Multi-object Tracking Based on Consistency Regularization
Feb 24, 2025


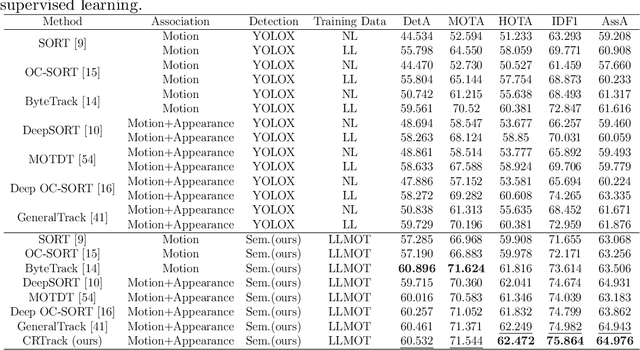
Multi-object tracking under low-light environments is prevalent in real life. Recent years have seen rapid development in the field of multi-object tracking. However, due to the lack of datasets and the high cost of annotations, multi-object tracking under low-light environments remains a persistent challenge. In this paper, we focus on multi-object tracking under low-light conditions. To address the issues of limited data and the lack of dataset, we first constructed a low-light multi-object tracking dataset (LLMOT). This dataset comprises data from MOT17 that has been enhanced for nighttime conditions as well as multiple unannotated low-light videos. Subsequently, to tackle the high annotation costs and address the issue of image quality degradation, we propose a semi-supervised multi-object tracking method based on consistency regularization named CRTrack. First, we calibrate a consistent adaptive sampling assignment to replace the static IoU-based strategy, enabling the semi-supervised tracking method to resist noisy pseudo-bounding boxes. Then, we design a adaptive semi-supervised network update method, which effectively leverages unannotated data to enhance model performance. Dataset and Code: https://github.com/ZJZhao123/CRTrack.
QGait: Toward Accurate Quantization for Gait Recognition with Binarized Input
May 22, 2024Existing deep learning methods have made significant progress in gait recognition. Typically, appearance-based models binarize inputs into silhouette sequences. However, mainstream quantization methods prioritize minimizing task loss over quantization error, which is detrimental to gait recognition with binarized inputs. Minor variations in silhouette sequences can be diminished in the network's intermediate layers due to the accumulation of quantization errors. To address this, we propose a differentiable soft quantizer, which better simulates the gradient of the round function during backpropagation. This enables the network to learn from subtle input perturbations. However, our theoretical analysis and empirical studies reveal that directly applying the soft quantizer can hinder network convergence. We further refine the training strategy to ensure convergence while simulating quantization errors. Additionally, we visualize the distribution of outputs from different samples in the feature space and observe significant changes compared to the full precision network, which harms performance. Based on this, we propose an Inter-class Distance-guided Distillation (IDD) strategy to preserve the relative distance between the embeddings of samples with different labels. Extensive experiments validate the effectiveness of our approach, demonstrating state-of-the-art accuracy across various settings and datasets. The code will be made publicly available.
Adaptive quantization with mixed-precision based on low-cost proxy
Feb 27, 2024It is critical to deploy complicated neural network models on hardware with limited resources. This paper proposes a novel model quantization method, named the Low-Cost Proxy-Based Adaptive Mixed-Precision Model Quantization (LCPAQ), which contains three key modules. The hardware-aware module is designed by considering the hardware limitations, while an adaptive mixed-precision quantization module is developed to evaluate the quantization sensitivity by using the Hessian matrix and Pareto frontier techniques. Integer linear programming is used to fine-tune the quantization across different layers. Then the low-cost proxy neural architecture search module efficiently explores the ideal quantization hyperparameters. Experiments on the ImageNet demonstrate that the proposed LCPAQ achieves comparable or superior quantization accuracy to existing mixed-precision models. Notably, LCPAQ achieves 1/200 of the search time compared with existing methods, which provides a shortcut in practical quantization use for resource-limited devices.
NightRain: Nighttime Video Deraining via Adaptive-Rain-Removal and Adaptive-Correction
Jan 10, 2024

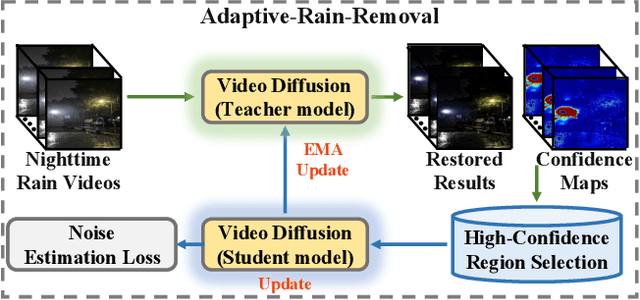
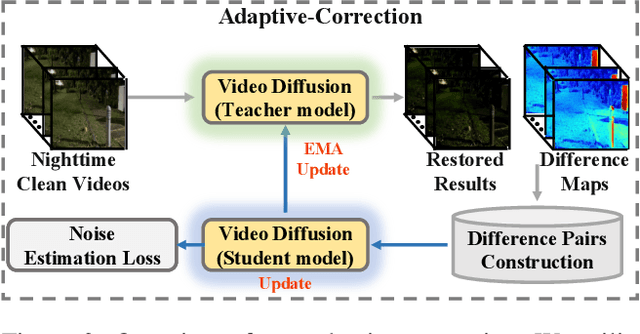
Existing deep-learning-based methods for nighttime video deraining rely on synthetic data due to the absence of real-world paired data. However, the intricacies of the real world, particularly with the presence of light effects and low-light regions affected by noise, create significant domain gaps, hampering synthetic-trained models in removing rain streaks properly and leading to over-saturation and color shifts. Motivated by this, we introduce NightRain, a novel nighttime video deraining method with adaptive-rain-removal and adaptive-correction. Our adaptive-rain-removal uses unlabeled rain videos to enable our model to derain real-world rain videos, particularly in regions affected by complex light effects. The idea is to allow our model to obtain rain-free regions based on the confidence scores. Once rain-free regions and the corresponding regions from our input are obtained, we can have region-based paired real data. These paired data are used to train our model using a teacher-student framework, allowing the model to iteratively learn from less challenging regions to more challenging regions. Our adaptive-correction aims to rectify errors in our model's predictions, such as over-saturation and color shifts. The idea is to learn from clear night input training videos based on the differences or distance between those input videos and their corresponding predictions. Our model learns from these differences, compelling our model to correct the errors. From extensive experiments, our method demonstrates state-of-the-art performance. It achieves a PSNR of 26.73dB, surpassing existing nighttime video deraining methods by a substantial margin of 13.7%.
SSPFusion: A Semantic Structure-Preserving Approach for Infrared and Visible Image Fusion
Sep 26, 2023Most existing learning-based infrared and visible image fusion (IVIF) methods exhibit massive redundant information in the fusion images, i.e., yielding edge-blurring effect or unrecognizable for object detectors. To alleviate these issues, we propose a semantic structure-preserving approach for IVIF, namely SSPFusion. At first, we design a Structural Feature Extractor (SFE) to extract the structural features of infrared and visible images. Then, we introduce a multi-scale Structure-Preserving Fusion (SPF) module to fuse the structural features of infrared and visible images, while maintaining the consistency of semantic structures between the fusion and source images. Owing to these two effective modules, our method is able to generate high-quality fusion images from pairs of infrared and visible images, which can boost the performance of downstream computer-vision tasks. Experimental results on three benchmarks demonstrate that our method outperforms eight state-of-the-art image fusion methods in terms of both qualitative and quantitative evaluations. The code for our method, along with additional comparison results, will be made available at: https://github.com/QiaoYang-CV/SSPFUSION.
IAIFNet: An Illumination-Aware Infrared and Visible Image Fusion Network
Sep 26, 2023Infrared and visible image fusion (IVIF) is used to generate fusion images with comprehensive features of both images, which is beneficial for downstream vision tasks. However, current methods rarely consider the illumination condition in low-light environments, and the targets in the fused images are often not prominent. To address the above issues, we propose an Illumination-Aware Infrared and Visible Image Fusion Network, named as IAIFNet. In our framework, an illumination enhancement network first estimates the incident illumination maps of input images. Afterwards, with the help of proposed adaptive differential fusion module (ADFM) and salient target aware module (STAM), an image fusion network effectively integrates the salient features of the illumination-enhanced infrared and visible images into a fusion image of high visual quality. Extensive experimental results verify that our method outperforms five state-of-the-art methods of fusing infrared and visible images.