 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQGait: Toward Accurate Quantization for Gait Recognition with Binarized Input
May 22, 2024Existing deep learning methods have made significant progress in gait recognition. Typically, appearance-based models binarize inputs into silhouette sequences. However, mainstream quantization methods prioritize minimizing task loss over quantization error, which is detrimental to gait recognition with binarized inputs. Minor variations in silhouette sequences can be diminished in the network's intermediate layers due to the accumulation of quantization errors. To address this, we propose a differentiable soft quantizer, which better simulates the gradient of the round function during backpropagation. This enables the network to learn from subtle input perturbations. However, our theoretical analysis and empirical studies reveal that directly applying the soft quantizer can hinder network convergence. We further refine the training strategy to ensure convergence while simulating quantization errors. Additionally, we visualize the distribution of outputs from different samples in the feature space and observe significant changes compared to the full precision network, which harms performance. Based on this, we propose an Inter-class Distance-guided Distillation (IDD) strategy to preserve the relative distance between the embeddings of samples with different labels. Extensive experiments validate the effectiveness of our approach, demonstrating state-of-the-art accuracy across various settings and datasets. The code will be made publicly available.
Adaptive quantization with mixed-precision based on low-cost proxy
Feb 27, 2024It is critical to deploy complicated neural network models on hardware with limited resources. This paper proposes a novel model quantization method, named the Low-Cost Proxy-Based Adaptive Mixed-Precision Model Quantization (LCPAQ), which contains three key modules. The hardware-aware module is designed by considering the hardware limitations, while an adaptive mixed-precision quantization module is developed to evaluate the quantization sensitivity by using the Hessian matrix and Pareto frontier techniques. Integer linear programming is used to fine-tune the quantization across different layers. Then the low-cost proxy neural architecture search module efficiently explores the ideal quantization hyperparameters. Experiments on the ImageNet demonstrate that the proposed LCPAQ achieves comparable or superior quantization accuracy to existing mixed-precision models. Notably, LCPAQ achieves 1/200 of the search time compared with existing methods, which provides a shortcut in practical quantization use for resource-limited devices.
A Comprehensive Comparison of Projections in Omnidirectional Super-Resolution
Apr 13, 2023
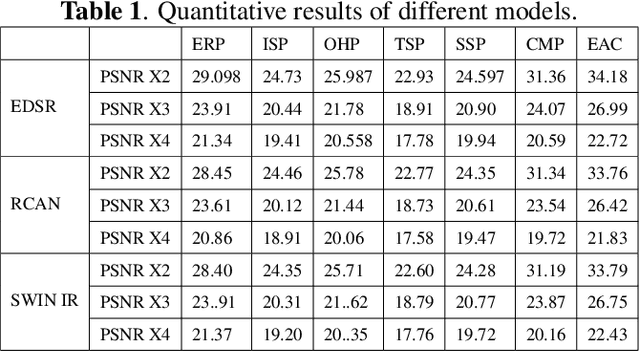

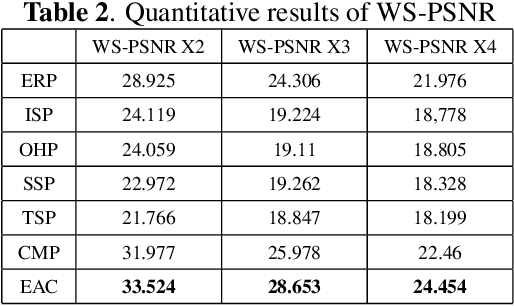
Super-Resolution (SR) has gained increasing research attention over the past few years. With the development of Deep Neural Networks (DNNs), many super-resolution methods based on DNNs have been proposed. Although most of these methods are aimed at ordinary frames, there are few works on super-resolution of omnidirectional frames. In these works, omnidirectional frames are projected from the 3D sphere to a 2D plane by Equi-Rectangular Projection (ERP). Although ERP has been widely used for projection, it has severe projection distortion near poles. Current DNN-based SR methods use 2D convolution modules, which is more suitable for the regular grid. In this paper, we find that different projection methods have great impact on the performance of DNNs. To study this problem, a comprehensive comparison of projections in omnidirectional super-resolution is conducted. We compare the SR results of different projection methods. Experimental results show that Equi-Angular cube map projection (EAC), which has minimal distortion, achieves the best result in terms of WS-PSNR compared with other projections. Code and data will be released.
CABM: Content-Aware Bit Mapping for Single Image Super-Resolution Network with Large Input
Apr 13, 2023
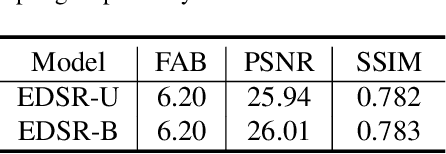

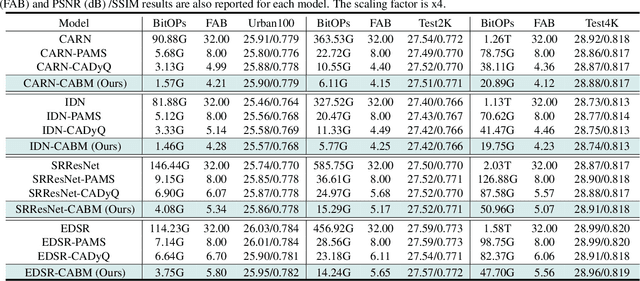
With the development of high-definition display devices, the practical scenario of Super-Resolution (SR) usually needs to super-resolve large input like 2K to higher resolution (4K/8K). To reduce the computational and memory cost, current methods first split the large input into local patches and then merge the SR patches into the output. These methods adaptively allocate a subnet for each patch. Quantization is a very important technique for network acceleration and has been used to design the subnets. Current methods train an MLP bit selector to determine the propoer bit for each layer. However, they uniformly sample subnets for training, making simple subnets overfitted and complicated subnets underfitted. Therefore, the trained bit selector fails to determine the optimal bit. Apart from this, the introduced bit selector brings additional cost to each layer of the SR network. In this paper, we propose a novel method named Content-Aware Bit Mapping (CABM), which can remove the bit selector without any performance loss. CABM also learns a bit selector for each layer during training. After training, we analyze the relation between the edge information of an input patch and the bit of each layer. We observe that the edge information can be an effective metric for the selected bit. Therefore, we design a strategy to build an Edge-to-Bit lookup table that maps the edge score of a patch to the bit of each layer during inference. The bit configuration of SR network can be determined by the lookup tables of all layers. Our strategy can find better bit configuration, resulting in more efficient mixed precision networks. We conduct detailed experiments to demonstrate the generalization ability of our method. The code will be released.