 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchically Encapsulated Representation for Protocol Design in Self-Driving Labs
Apr 04, 2025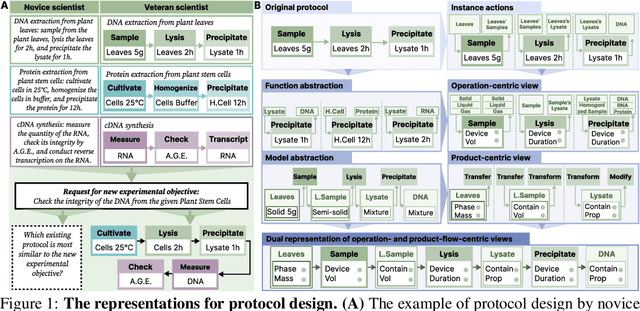

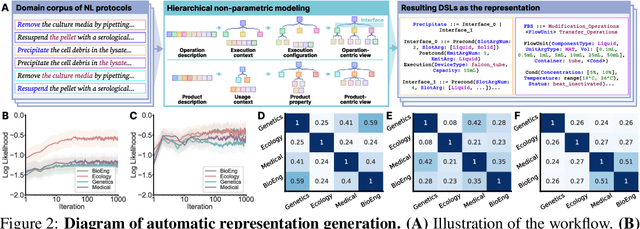
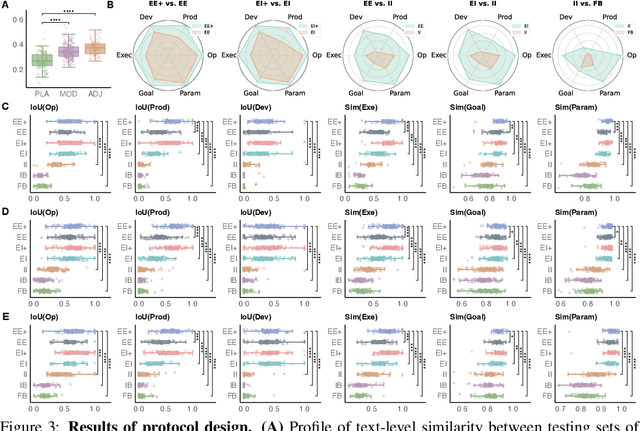
Self-driving laboratories have begun to replace human experimenters in performing single experimental skills or predetermined experimental protocols. However, as the pace of idea iteration in scientific research has been intensified by Artificial Intelligence, the demand for rapid design of new protocols for new discoveries become evident. Efforts to automate protocol design have been initiated, but the capabilities of knowledge-based machine designers, such as Large Language Models, have not been fully elicited, probably for the absence of a systematic representation of experimental knowledge, as opposed to isolated, flatten pieces of information. To tackle this issue, we propose a multi-faceted, multi-scale representation, where instance actions, generalized operations, and product flow models are hierarchically encapsulated using Domain-Specific Languages. We further develop a data-driven algorithm based on non-parametric modeling that autonomously customizes these representations for specific domains. The proposed representation is equipped with various machine designers to manage protocol design tasks, including planning, modification, and adjustment. The results demonstrate that the proposed method could effectively complement Large Language Models in the protocol design process, serving as an auxiliary module in the realm of machine-assisted scientific exploration.
Expert-level protocol translation for self-driving labs
Nov 01, 2024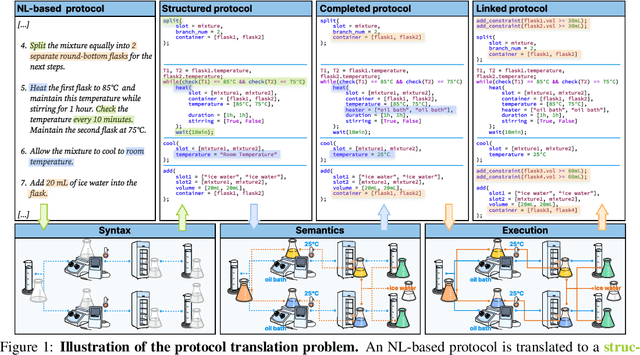
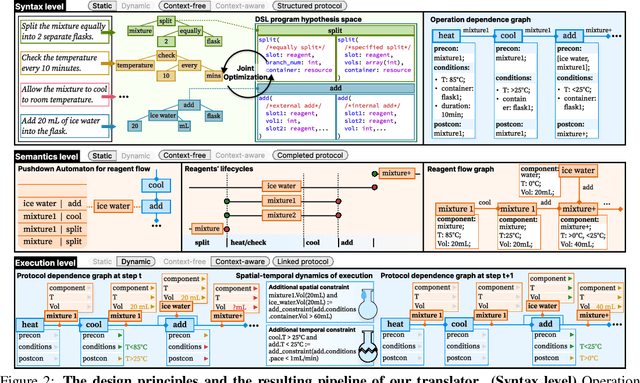
Recent development in Artificial Intelligence (AI) models has propelled their application in scientific discovery, but the validation and exploration of these discoveries require subsequent empirical experimentation. The concept of self-driving laboratories promises to automate and thus boost the experimental process following AI-driven discoveries. However, the transition of experimental protocols, originally crafted for human comprehension, into formats interpretable by machines presents significant challenges, which, within the context of specific expert domain, encompass the necessity for structured as opposed to natural language, the imperative for explicit rather than tacit knowledge, and the preservation of causality and consistency throughout protocol steps. Presently, the task of protocol translation predominantly requires the manual and labor-intensive involvement of domain experts and information technology specialists, rendering the process time-intensive. To address these issues, we propose a framework that automates the protocol translation process through a three-stage workflow, which incrementally constructs Protocol Dependence Graphs (PDGs) that approach structured on the syntax level, completed on the semantics level, and linked on the execution level. Quantitative and qualitative evaluations have demonstrated its performance at par with that of human experts, underscoring its potential to significantly expedite and democratize the process of scientific discovery by elevating the automation capabilities within self-driving laboratories.
Abstract Hardware Grounding towards the Automated Design of Automation Systems
Oct 08, 2024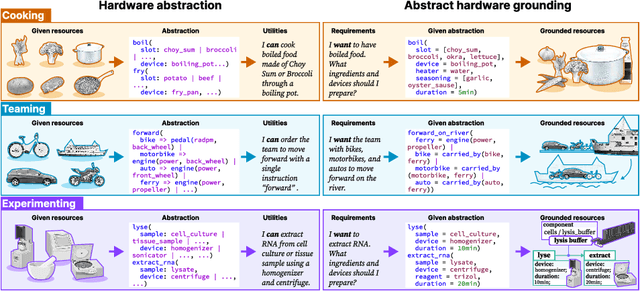
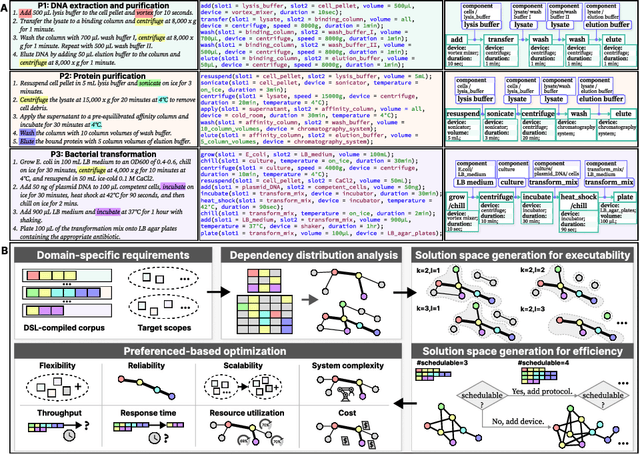
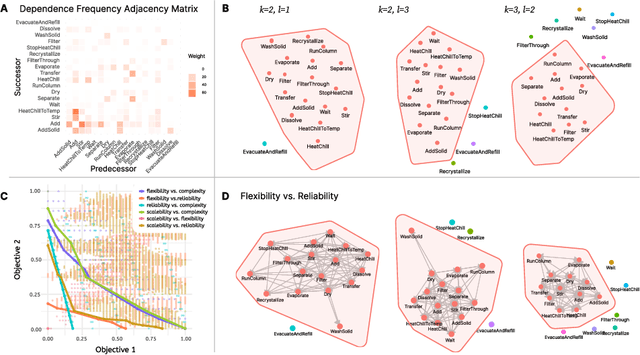
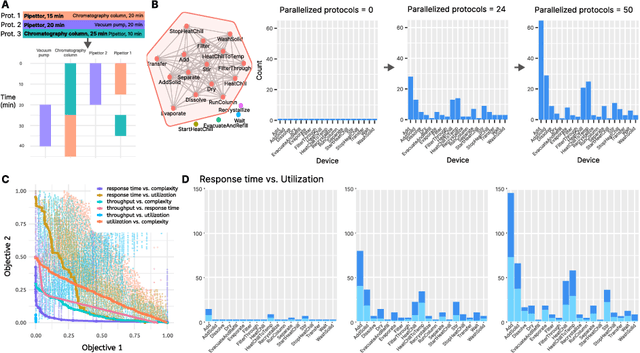
Crafting automation systems tailored for specific domains requires aligning the space of human experts' semantics with the space of robot executable actions, and scheduling the required resources and system layout accordingly. Regrettably, there are three major gaps, fine-grained domain-specific knowledge injection, heterogeneity between human knowledge and robot instructions, and diversity of users' preferences, resulting automation system design a case-by-case and labour-intensive effort, thus hindering the democratization of automation. We refer to this challenging alignment as the abstract hardware grounding problem, where we firstly regard the procedural operations in humans' semantics space as the abstraction of hardware requirements, then we ground such abstractions to instantiated hardware devices, subject to constraints and preferences in the real world -- optimizing this problem is essentially standardizing and automating the design of automation systems. On this basis, we develop an automated design framework in a hybrid data-driven and principle-derived fashion. Results on designing self-driving laboratories for enhancing experiment-driven scientific discovery suggest our framework's potential to produce compact systems that fully satisfy domain-specific and user-customized requirements with no redundancy.
AutoDSL: Automated domain-specific language design for structural representation of procedures with constraints
Jun 18, 2024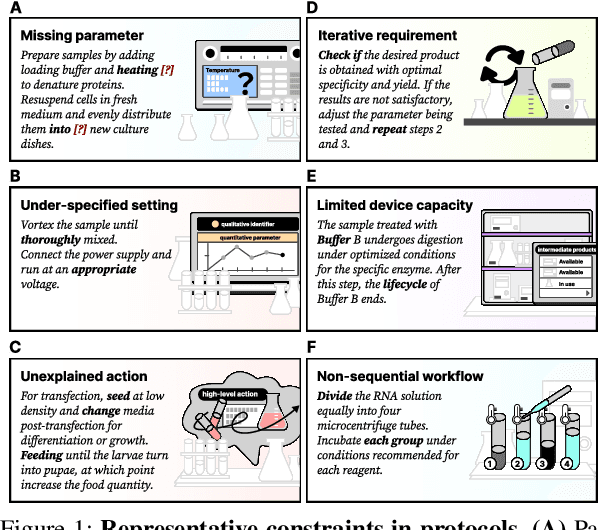



Accurate representation of procedures in restricted scenarios, such as non-standardized scientific experiments, requires precise depiction of constraints. Unfortunately, Domain-specific Language (DSL), as an effective tool to express constraints structurally, often requires case-by-case hand-crafting, necessitating customized, labor-intensive efforts. To overcome this challenge, we introduce the AutoDSL framework to automate DSL-based constraint design across various domains. Utilizing domain specified experimental protocol corpora, AutoDSL optimizes syntactic constraints and abstracts semantic constraints. Quantitative and qualitative analyses of the DSLs designed by AutoDSL across five distinct domains highlight its potential as an auxiliary module for language models, aiming to improve procedural planning and execution.
To think inside the box, or to think out of the box? Scientific discovery via the reciprocation of insights and concepts
Dec 04, 2022


If scientific discovery is one of the main driving forces of human progress, insight is the fuel for the engine, which has long attracted behavior-level research to understand and model its underlying cognitive process. However, current tasks that abstract scientific discovery mostly focus on the emergence of insight, ignoring the special role played by domain knowledge. In this concept paper, we view scientific discovery as an interplay between $thinking \ out \ of \ the \ box$ that actively seeks insightful solutions and $thinking \ inside \ the \ box$ that generalizes on conceptual domain knowledge to keep correct. Accordingly, we propose Mindle, a semantic searching game that triggers scientific-discovery-like thinking spontaneously, as infrastructure for exploring scientific discovery on a large scale. On this basis, the meta-strategies for insights and the usage of concepts can be investigated reciprocally. In the pilot studies, several interesting observations inspire elaborated hypotheses on meta-strategies, context, and individual diversity for further investigations.
On the Complexity of Bayesian Generalization
Nov 26, 2022



We consider concept generalization at a large scale in the diverse and natural visual spectrum. Established computational modes (i.e., rule-based or similarity-based) are primarily studied isolated and focus on confined and abstract problem spaces. In this work, we study these two modes when the problem space scales up, and the $complexity$ of concepts becomes diverse. Specifically, at the $representational \ level$, we seek to answer how the complexity varies when a visual concept is mapped to the representation space. Prior psychology literature has shown that two types of complexities (i.e., subjective complexity and visual complexity) (Griffiths and Tenenbaum, 2003) build an inverted-U relation (Donderi, 2006; Sun and Firestone, 2021). Leveraging Representativeness of Attribute (RoA), we computationally confirm the following observation: Models use attributes with high RoA to describe visual concepts, and the description length falls in an inverted-U relation with the increment in visual complexity. At the $computational \ level$, we aim to answer how the complexity of representation affects the shift between the rule- and similarity-based generalization. We hypothesize that category-conditioned visual modeling estimates the co-occurrence frequency between visual and categorical attributes, thus potentially serving as the prior for the natural visual world. Experimental results show that representations with relatively high subjective complexity outperform those with relatively low subjective complexity in the rule-based generalization, while the trend is the opposite in the similarity-based generalization.