 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLCGC: Learning from Consistency Gradient Conflicting for Class-Imbalanced Semi-Supervised Debiasing
Apr 09, 2025Classifiers often learn to be biased corresponding to the class-imbalanced dataset, especially under the semi-supervised learning (SSL) set. While previous work tries to appropriately re-balance the classifiers by subtracting a class-irrelevant image's logit, but lacks a firm theoretical basis. We theoretically analyze why exploiting a baseline image can refine pseudo-labels and prove that the black image is the best choice. We also indicated that as the training process deepens, the pseudo-labels before and after refinement become closer. Based on this observation, we propose a debiasing scheme dubbed LCGC, which Learning from Consistency Gradient Conflicting, by encouraging biased class predictions during training. We intentionally update the pseudo-labels whose gradient conflicts with the debiased logits, representing the optimization direction offered by the over-imbalanced classifier predictions. Then, we debiased the predictions by subtracting the baseline image logits during testing. Extensive experiments demonstrate that LCGC can significantly improve the prediction accuracy of existing CISSL models on public benchmarks.
Replacement Learning: Training Vision Tasks with Fewer Learnable Parameters
Oct 02, 2024



Traditional end-to-end deep learning models often enhance feature representation and overall performance by increasing the depth and complexity of the network during training. However, this approach inevitably introduces issues of parameter redundancy and resource inefficiency, especially in deeper networks. While existing works attempt to skip certain redundant layers to alleviate these problems, challenges related to poor performance, computational complexity, and inefficient memory usage remain. To address these issues, we propose an innovative training approach called Replacement Learning, which mitigates these limitations by completely replacing all the parameters of the frozen layers with only two learnable parameters. Specifically, Replacement Learning selectively freezes the parameters of certain layers, and the frozen layers utilize parameters from adjacent layers, updating them through a parameter integration mechanism controlled by two learnable parameters. This method leverages information from surrounding structures, reduces computation, conserves GPU memory, and maintains a balance between historical context and new inputs, ultimately enhancing overall model performance. We conducted experiments across four benchmark datasets, including CIFAR-10, STL-10, SVHN, and ImageNet, utilizing various architectures such as CNNs and ViTs to validate the effectiveness of Replacement Learning. Experimental results demonstrate that our approach reduces the number of parameters, training time, and memory consumption while completely surpassing the performance of end-to-end training.
Inference for Large Scale Regression Models with Dependent Errors
Sep 08, 2024

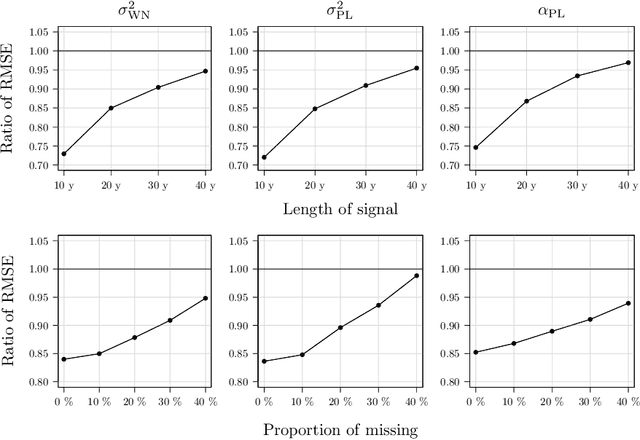
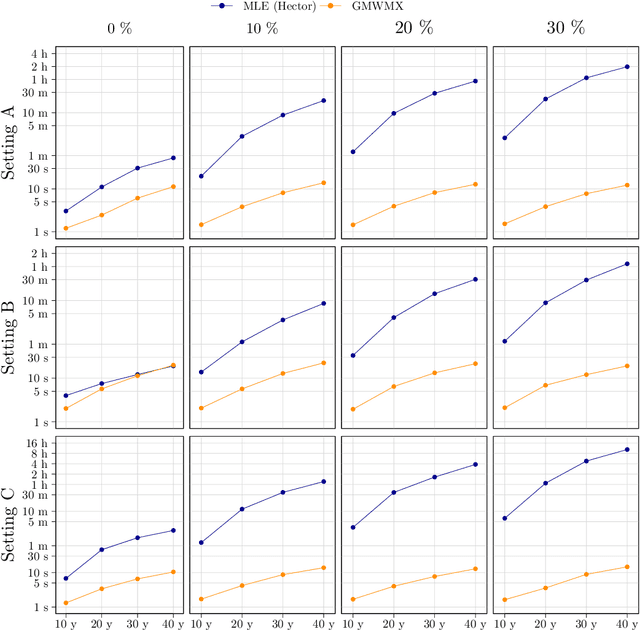
The exponential growth in data sizes and storage costs has brought considerable challenges to the data science community, requiring solutions to run learning methods on such data. While machine learning has scaled to achieve predictive accuracy in big data settings, statistical inference and uncertainty quantification tools are still lagging. Priority scientific fields collect vast data to understand phenomena typically studied with statistical methods like regression. In this setting, regression parameter estimation can benefit from efficient computational procedures, but the main challenge lies in computing error process parameters with complex covariance structures. Identifying and estimating these structures is essential for inference and often used for uncertainty quantification in machine learning with Gaussian Processes. However, estimating these structures becomes burdensome as data scales, requiring approximations that compromise the reliability of outputs. These approximations are even more unreliable when complexities like long-range dependencies or missing data are present. This work defines and proves the statistical properties of the Generalized Method of Wavelet Moments with Exogenous variables (GMWMX), a highly scalable, stable, and statistically valid method for estimating and delivering inference for linear models using stochastic processes in the presence of data complexities like latent dependence structures and missing data. Applied examples from Earth Sciences and extensive simulations highlight the advantages of the GMWMX.
LAKD-Activation Mapping Distillation Based on Local Learning
Aug 22, 2024



Knowledge distillation is widely applied in various fundamental vision models to enhance the performance of compact models. Existing knowledge distillation methods focus on designing different distillation targets to acquire knowledge from teacher models. However, these methods often overlook the efficient utilization of distilled information, crudely coupling different types of information, making it difficult to explain how the knowledge from the teacher network aids the student network in learning. This paper proposes a novel knowledge distillation framework, Local Attention Knowledge Distillation (LAKD), which more efficiently utilizes the distilled information from teacher networks, achieving higher interpretability and competitive performance. The framework establishes an independent interactive training mechanism through a separation-decoupling mechanism and non-directional activation mapping. LAKD decouples the teacher's features and facilitates progressive interaction training from simple to complex. Specifically, the student network is divided into local modules with independent gradients to decouple the knowledge transferred from the teacher. The non-directional activation mapping helps the student network integrate knowledge from different local modules by learning coarse-grained feature knowledge. We conducted experiments on the CIFAR-10, CIFAR-100, and ImageNet datasets, and the results show that our LAKD method significantly outperforms existing methods, consistently achieving state-of-the-art performance across different datasets.
GSO-YOLO: Global Stability Optimization YOLO for Construction Site Detection
Jul 01, 2024



Safety issues at construction sites have long plagued the industry, posing risks to worker safety and causing economic damage due to potential hazards. With the advancement of artificial intelligence, particularly in the field of computer vision, the automation of safety monitoring on construction sites has emerged as a solution to this longstanding issue. Despite achieving impressive performance, advanced object detection methods like YOLOv8 still face challenges in handling the complex conditions found at construction sites. To solve these problems, this study presents the Global Stability Optimization YOLO (GSO-YOLO) model to address challenges in complex construction sites. The model integrates the Global Optimization Module (GOM) and Steady Capture Module (SCM) to enhance global contextual information capture and detection stability. The innovative AIoU loss function, which combines CIoU and EIoU, improves detection accuracy and efficiency. Experiments on datasets like SODA, MOCS, and CIS show that GSO-YOLO outperforms existing methods, achieving SOTA performance.
MLAAN: Scaling Supervised Local Learning with Multilaminar Leap Augmented Auxiliary Network
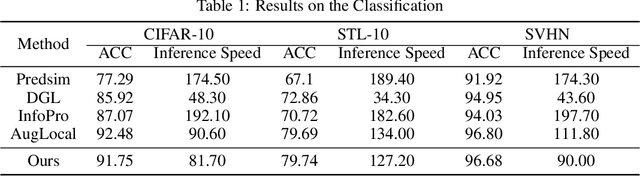
Jun 24, 2024End-to-end (E2E) training approaches are commonly plagued by high memory consumption, reduced efficiency in training, challenges in model parallelization, and suboptimal biocompatibility. Local learning is considered a novel interactive training method that holds promise as an alternative to E2E. Nonetheless, conventional local learning methods fall short in achieving high model accuracy due to inadequate local inter-module interactions. In this paper, we introduce a new model known as the Scaling Supervised Local Learning with Multilaminar Leap Augmented Auxiliary Network (MLAAN). MLAAN features an innovative supervised local learning approach coupled with a robust reinforcement module. This dual-component design enables the MLAAN to integrate smoothly with established local learning techniques, thereby enhancing the efficacy of the foundational methods. The method simultaneously acquires the local and global features of the model separately by constructing an independent auxiliary network and a cascade auxiliary network on the one hand and incorporates a leap augmented module, which serves to counteract the reduced learning capacity often associated with weaker supervision. This architecture not only augments the exchange of information amongst the local modules but also effectively mitigates the model's tendency toward myopia. The experimental evaluations conducted on four benchmark datasets, CIFAR-10, STL-10, SVHN, and ImageNet, demonstrate that the integration of MLAAN with existing supervised local learning methods significantly enhances the original methodologies. Of particular note, MLAAN enables local learning methods to comprehensively outperform end-to-end training approaches in terms of optimal performance while saving GPU memory.
GLCAN: Global-Local Collaborative Auxiliary Network for Local Learning
Jun 01, 2024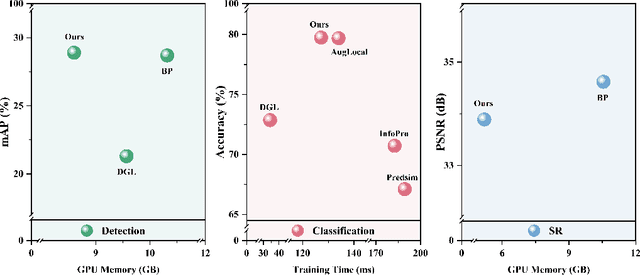
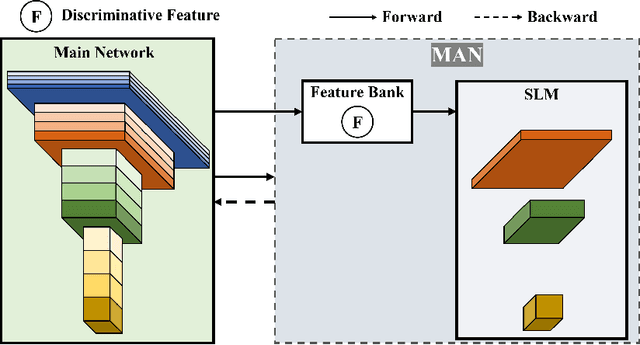
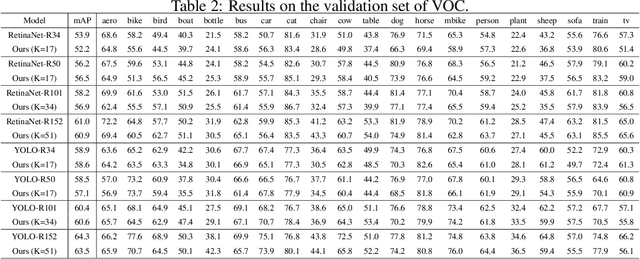
Traditional deep neural networks typically use end-to-end backpropagation, which often places a big burden on GPU memory. Another promising training method is local learning, which involves splitting the network into blocks and training them in parallel with the help of an auxiliary network. Local learning has been widely studied and applied to image classification tasks, and its performance is comparable to that of end-to-end method. However, different image tasks often rely on different feature representations, which is difficult for typical auxiliary networks to adapt to. To solve this problem, we propose the construction method of Global-Local Collaborative Auxiliary Network (GLCAN), which provides a macroscopic design approach for auxiliary networks. This is the first demonstration that local learning methods can be successfully applied to other tasks such as object detection and super-resolution. GLCAN not only saves a lot of GPU memory, but also has comparable performance to an end-to-end approach on data sets for multiple different tasks.