 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShedding the Facades, Connecting the Domains: Detecting Shifting Multimodal Hate Video with Test-Time Adaptation
Jan 28, 2026Hate Video Detection (HVD) is crucial for online ecosystems. Existing methods assume identical distributions between training (source) and inference (target) data. However, hateful content often evolves into irregular and ambiguous forms to evade censorship, resulting in substantial semantic drift and rendering previously trained models ineffective. Test-Time Adaptation (TTA) offers a solution by adapting models during inference to narrow the cross-domain gap, while conventional TTA methods target mild distribution shifts and struggle with the severe semantic drift in HVD. To tackle these challenges, we propose SCANNER, the first TTA framework tailored for HVD. Motivated by the insight that, despite the evolving nature of hateful manifestations, their underlying cores remain largely invariant (i.e., targeting is still based on characteristics like gender, race, etc), we leverage these stable cores as a bridge to connect the source and target domains. Specifically, SCANNER initially reveals the stable cores from the ambiguous layout in evolving hateful content via a principled centroid-guided alignment mechanism. To alleviate the impact of outlier-like samples that are weakly correlated with centroids during the alignment process, SCANNER enhances the prior by incorporating a sample-level adaptive centroid alignment strategy, promoting more stable adaptation. Furthermore, to mitigate semantic collapse from overly uniform outputs within clusters, SCANNER introduces an intra-cluster diversity regularization that encourages the cluster-wise semantic richness. Experiments show that SCANNER outperforms all baselines, with an average gain of 4.69% in Macro-F1 over the best.
TransMedSeg: A Transferable Semantic Framework for Semi-Supervised Medical Image Segmentation
May 20, 2025Semi-supervised learning (SSL) has achieved significant progress in medical image segmentation (SSMIS) through effective utilization of limited labeled data. While current SSL methods for medical images predominantly rely on consistency regularization and pseudo-labeling, they often overlook transferable semantic relationships across different clinical domains and imaging modalities. To address this, we propose TransMedSeg, a novel transferable semantic framework for semi-supervised medical image segmentation. Our approach introduces a Transferable Semantic Augmentation (TSA) module, which implicitly enhances feature representations by aligning domain-invariant semantics through cross-domain distribution matching and intra-domain structural preservation. Specifically, TransMedSeg constructs a unified feature space where teacher network features are adaptively augmented towards student network semantics via a lightweight memory module, enabling implicit semantic transformation without explicit data generation. Interestingly, this augmentation is implicitly realized through an expected transferable cross-entropy loss computed over the augmented teacher distribution. An upper bound of the expected loss is theoretically derived and minimized during training, incurring negligible computational overhead. Extensive experiments on medical image datasets demonstrate that TransMedSeg outperforms existing semi-supervised methods, establishing a new direction for transferable representation learning in medical image analysis.
GraphCL: Graph-based Clustering for Semi-Supervised Medical Image Segmentation
Nov 20, 2024



Semi-supervised learning (SSL) has made notable advancements in medical image segmentation (MIS), particularly in scenarios with limited labeled data and significantly enhancing data utilization efficiency. Previous methods primarily focus on complex training strategies to utilize unlabeled data but neglect the importance of graph structural information. Different from existing methods, we propose a graph-based clustering for semi-supervised medical image segmentation (GraphCL) by jointly modeling graph data structure in a unified deep model. The proposed GraphCL model enjoys several advantages. Firstly, to the best of our knowledge, this is the first work to model the data structure information for semi-supervised medical image segmentation (SSMIS). Secondly, to get the clustered features across different graphs, we integrate both pairwise affinities between local image features and raw features as inputs. Extensive experimental results on three standard benchmarks show that the proposed GraphCL algorithm outperforms state-of-the-art semi-supervised medical image segmentation methods.
AGLP: A Graph Learning Perspective for Semi-supervised Domain Adaptation
Nov 20, 2024In semi-supervised domain adaptation (SSDA), the model aims to leverage partially labeled target domain data along with a large amount of labeled source domain data to enhance its generalization capability for the target domain. A key advantage of SSDA is its ability to significantly reduce reliance on labeled data, thereby lowering the costs and time associated with data preparation. Most existing SSDA methods utilize information from domain labels and class labels but overlook the structural information of the data. To address this issue, this paper proposes a graph learning perspective (AGLP) for semi-supervised domain adaptation. We apply the graph convolutional network to the instance graph which allows structural information to propagate along the weighted graph edges. The proposed AGLP model has several advantages. First, to the best of our knowledge, this is the first work to model structural information in SSDA. Second, the proposed model can effectively learn domain-invariant and semantic representations, reducing domain discrepancies in SSDA. Extensive experimental results on multiple standard benchmarks demonstrate that the proposed AGLP algorithm outperforms state-of-the-art semi-supervised domain adaptation methods.
Atrial Fibrillation Detection System via Acoustic Sensing for Mobile Phones
Oct 28, 2024


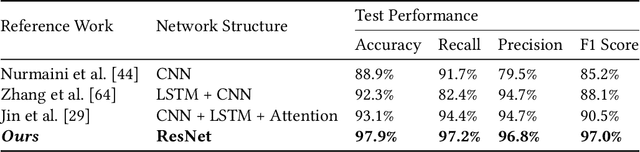
Atrial fibrillation (AF) is characterized by irregular electrical impulses originating in the atria, which can lead to severe complications and even death. Due to the intermittent nature of the AF, early and timely monitoring of AF is critical for patients to prevent further exacerbation of the condition. Although ambulatory ECG Holter monitors provide accurate monitoring, the high cost of these devices hinders their wider adoption. Current mobile-based AF detection systems offer a portable solution, however, these systems have various applicability issues such as being easily affected by environmental factors and requiring significant user effort. To overcome the above limitations, we present MobileAF, a novel smartphone-based AF detection system using speakers and microphones. In order to capture minute cardiac activities, we propose a multi-channel pulse wave probing method. In addition, we enhance the signal quality by introducing a three-stage pulse wave purification pipeline. What's more, a ResNet-based network model is built to implement accurate and reliable AF detection. We collect data from 23 participants utilizing our data collection application on the smartphone. Extensive experimental results demonstrate the superior performance of our system, with 97.9% accuracy, 96.8% precision, 97.2% recall, 98.3% specificity, and 97.0% F1 score.
KAN v.s. MLP for Offline Reinforcement Learning
Sep 15, 2024Kolmogorov-Arnold Networks (KAN) is an emerging neural network architecture in machine learning. It has greatly interested the research community about whether KAN can be a promising alternative of the commonly used Multi-Layer Perceptions (MLP). Experiments in various fields demonstrated that KAN-based machine learning can achieve comparable if not better performance than MLP-based methods, but with much smaller parameter scales and are more explainable. In this paper, we explore the incorporation of KAN into the actor and critic networks for offline reinforcement learning (RL). We evaluated the performance, parameter scales, and training efficiency of various KAN and MLP based conservative Q-learning (CQL) on the the classical D4RL benchmark for offline RL. Our study demonstrates that KAN can achieve performance close to the commonly used MLP with significantly fewer parameters. This provides us an option to choose the base networks according to the requirements of the offline RL tasks.
Open-World Test-Time Training: Self-Training with Contrast Learning
Sep 15, 2024



Traditional test-time training (TTT) methods, while addressing domain shifts, often assume a consistent class set, limiting their applicability in real-world scenarios characterized by infinite variety. Open-World Test-Time Training (OWTTT) addresses the challenge of generalizing deep learning models to unknown target domain distributions, especially in the presence of strong Out-of-Distribution (OOD) data. Existing TTT methods often struggle to maintain performance when confronted with strong OOD data. In OWTTT, the focus has predominantly been on distinguishing between overall strong and weak OOD data. However, during the early stages of TTT, initial feature extraction is hampered by interference from strong OOD and corruptions, resulting in diminished contrast and premature classification of certain classes as strong OOD. To address this, we introduce Open World Dynamic Contrastive Learning (OWDCL), an innovative approach that utilizes contrastive learning to augment positive sample pairs. This strategy not only bolsters contrast in the early stages but also significantly enhances model robustness in subsequent stages. In comparison datasets, our OWDCL model has produced the most advanced performance.
AcousAF: Acoustic Sensing-Based Atrial Fibrillation Detection System for Mobile Phones
Aug 09, 2024
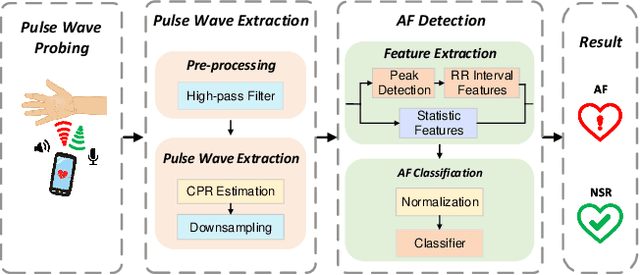
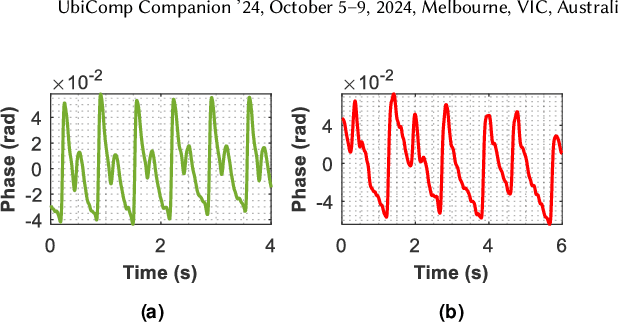
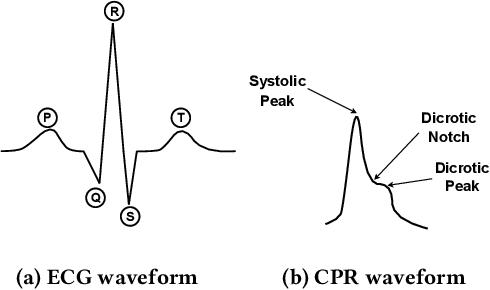
Atrial fibrillation (AF) is characterized by irregular electrical impulses originating in the atria, which can lead to severe complications and even death. Due to the intermittent nature of the AF, early and timely monitoring of AF is critical for patients to prevent further exacerbation of the condition. Although ambulatory ECG Holter monitors provide accurate monitoring, the high cost of these devices hinders their wider adoption. Current mobile-based AF detection systems offer a portable solution. However, these systems have various applicability issues, such as being easily affected by environmental factors and requiring significant user effort. To overcome the above limitations, we present AcousAF, a novel AF detection system based on acoustic sensors of smartphones. Particularly, we explore the potential of pulse wave acquisition from the wrist using smartphone speakers and microphones. In addition, we propose a well-designed framework comprised of pulse wave probing, pulse wave extraction, and AF detection to ensure accurate and reliable AF detection. We collect data from 20 participants utilizing our custom data collection application on the smartphone. Extensive experimental results demonstrate the high performance of our system, with 92.8% accuracy, 86.9% precision, 87.4% recall, and 87.1% F1 Score.
GLCAN: Global-Local Collaborative Auxiliary Network for Local Learning
Jun 01, 2024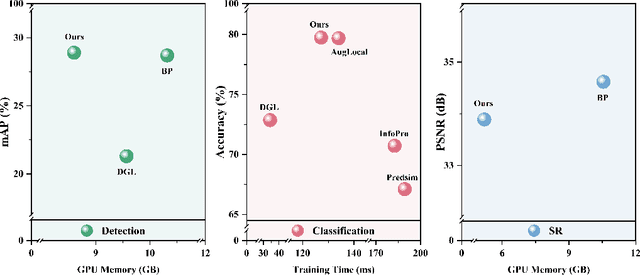
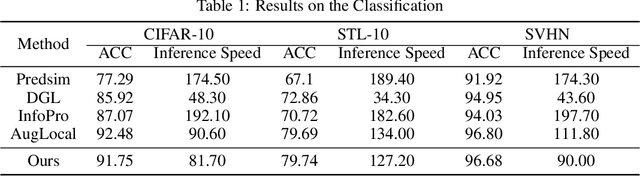
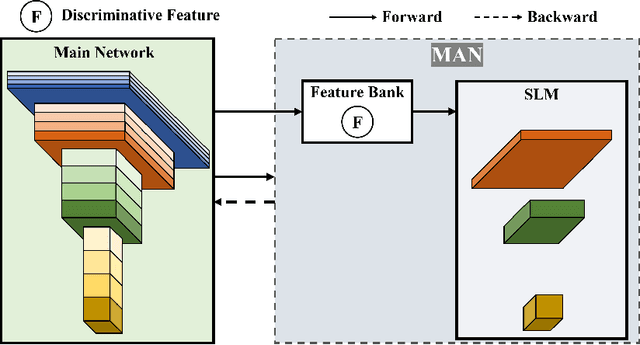
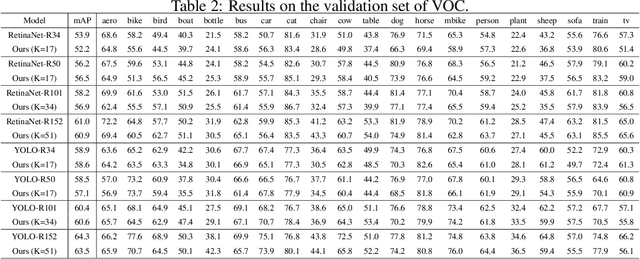
Traditional deep neural networks typically use end-to-end backpropagation, which often places a big burden on GPU memory. Another promising training method is local learning, which involves splitting the network into blocks and training them in parallel with the help of an auxiliary network. Local learning has been widely studied and applied to image classification tasks, and its performance is comparable to that of end-to-end method. However, different image tasks often rely on different feature representations, which is difficult for typical auxiliary networks to adapt to. To solve this problem, we propose the construction method of Global-Local Collaborative Auxiliary Network (GLCAN), which provides a macroscopic design approach for auxiliary networks. This is the first demonstration that local learning methods can be successfully applied to other tasks such as object detection and super-resolution. GLCAN not only saves a lot of GPU memory, but also has comparable performance to an end-to-end approach on data sets for multiple different tasks.
Listen, Disentangle, and Control: Controllable Speech-Driven Talking Head Generation
May 12, 2024Most earlier investigations on talking face generation have focused on the synchronization of lip motion and speech content. However, human head pose and facial emotions are equally important characteristics of natural human faces. While audio-driven talking face generation has seen notable advancements, existing methods either overlook facial emotions or are limited to specific individuals and cannot be applied to arbitrary subjects. In this paper, we propose a one-shot Talking Head Generation framework (SPEAK) that distinguishes itself from general Talking Face Generation by enabling emotional and postural control. Specifically, we introduce the Inter-Reconstructed Feature Disentanglement (IRFD) method to decouple human facial features into three latent spaces. We then design a face editing module that modifies speech content and facial latent codes into a single latent space. Subsequently, we present a novel generator that employs modified latent codes derived from the editing module to regulate emotional expression, head poses, and speech content in synthesizing facial animations. Extensive trials demonstrate that our method can generate realistic talking head with coordinated lip motions, authentic facial emotions, and smooth head movements. The demo video is available at the anonymous link: https://anonymous.4open.science/r/SPEAK-F56E