 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisionNVS: Self-Supervised Inpainting for Novel View Synthesis under the Virtual-Shift Paradigm
Mar 18, 2026A fundamental bottleneck in Novel View Synthesis (NVS) for autonomous driving is the inherent supervision gap on novel trajectories: models are tasked with synthesizing unseen views during inference, yet lack ground truth images for these shifted poses during training. In this paper, we propose VisionNVS, a camera-only framework that fundamentally reformulates view synthesis from an ill-posed extrapolation problem into a self-supervised inpainting task. By introducing a ``Virtual-Shift'' strategy, we use monocular depth proxies to simulate occlusion patterns and map them onto the original view. This paradigm shift allows the use of raw, recorded images as pixel-perfect supervision, effectively eliminating the domain gap inherent in previous approaches. Furthermore, we address spatial consistency through a Pseudo-3D Seam Synthesis strategy, which integrates visual data from adjacent cameras during training to explicitly model real-world photometric discrepancies and calibration errors. Experiments demonstrate that VisionNVS achieves superior geometric fidelity and visual quality compared to LiDAR-dependent baselines, offering a robust solution for scalable driving simulation.
Momentum Auxiliary Network for Supervised Local Learning
Jul 09, 2024



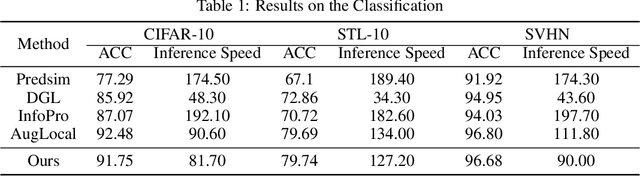
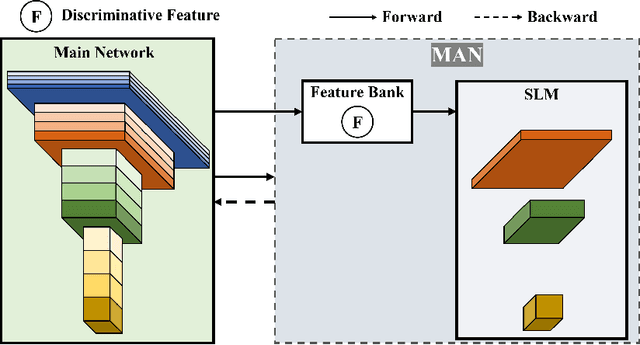
Deep neural networks conventionally employ end-to-end backpropagation for their training process, which lacks biological credibility and triggers a locking dilemma during network parameter updates, leading to significant GPU memory use. Supervised local learning, which segments the network into multiple local blocks updated by independent auxiliary networks. However, these methods cannot replace end-to-end training due to lower accuracy, as gradients only propagate within their local block, creating a lack of information exchange between blocks. To address this issue and establish information transfer across blocks, we propose a Momentum Auxiliary Network (MAN) that establishes a dynamic interaction mechanism. The MAN leverages an exponential moving average (EMA) of the parameters from adjacent local blocks to enhance information flow. This auxiliary network, updated through EMA, helps bridge the informational gap between blocks. Nevertheless, we observe that directly applying EMA parameters has certain limitations due to feature discrepancies among local blocks. To overcome this, we introduce learnable biases, further boosting performance. We have validated our method on four image classification datasets (CIFAR-10, STL-10, SVHN, ImageNet), attaining superior performance and substantial memory savings. Notably, our method can reduce GPU memory usage by more than 45\% on the ImageNet dataset compared to end-to-end training, while achieving higher performance. The Momentum Auxiliary Network thus offers a new perspective for supervised local learning. Our code is available at: https://github.com/JunhaoSu0/MAN.
HPFF: Hierarchical Locally Supervised Learning with Patch Feature Fusion
Jul 09, 2024Traditional deep learning relies on end-to-end backpropagation for training, but it suffers from drawbacks such as high memory consumption and not aligning with biological neural networks. Recent advancements have introduced locally supervised learning, which divides networks into modules with isolated gradients and trains them locally. However, this approach can lead to performance lag due to limited interaction between these modules, and the design of auxiliary networks occupies a certain amount of GPU memory. To overcome these limitations, we propose a novel model called HPFF that performs hierarchical locally supervised learning and patch-level feature computation on the auxiliary networks. Hierarchical Locally Supervised Learning (HiLo) enables the network to learn features at different granularity levels along their respective local paths. Specifically, the network is divided into two-level local modules: independent local modules and cascade local modules. The cascade local modules combine two adjacent independent local modules, incorporating both updates within the modules themselves and information exchange between adjacent modules. Patch Feature Fusion (PFF) reduces GPU memory usage by splitting the input features of the auxiliary networks into patches for computation. By averaging these patch-level features, it enhances the network's ability to focus more on those patterns that are prevalent across multiple patches. Furthermore, our method exhibits strong generalization capabilities and can be seamlessly integrated with existing techniques. We conduct experiments on CIFAR-10, STL-10, SVHN, and ImageNet datasets, and the results demonstrate that our proposed HPFF significantly outperforms previous approaches, consistently achieving state-of-the-art performance across different datasets. Our code is available at: https://github.com/Zeudfish/HPFF.
GLCAN: Global-Local Collaborative Auxiliary Network for Local Learning
Jun 01, 2024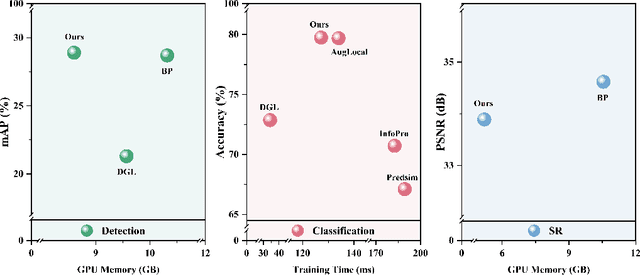
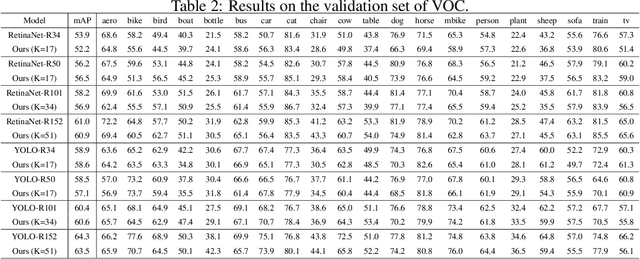
Traditional deep neural networks typically use end-to-end backpropagation, which often places a big burden on GPU memory. Another promising training method is local learning, which involves splitting the network into blocks and training them in parallel with the help of an auxiliary network. Local learning has been widely studied and applied to image classification tasks, and its performance is comparable to that of end-to-end method. However, different image tasks often rely on different feature representations, which is difficult for typical auxiliary networks to adapt to. To solve this problem, we propose the construction method of Global-Local Collaborative Auxiliary Network (GLCAN), which provides a macroscopic design approach for auxiliary networks. This is the first demonstration that local learning methods can be successfully applied to other tasks such as object detection and super-resolution. GLCAN not only saves a lot of GPU memory, but also has comparable performance to an end-to-end approach on data sets for multiple different tasks.
Listen, Disentangle, and Control: Controllable Speech-Driven Talking Head Generation
May 12, 2024Most earlier investigations on talking face generation have focused on the synchronization of lip motion and speech content. However, human head pose and facial emotions are equally important characteristics of natural human faces. While audio-driven talking face generation has seen notable advancements, existing methods either overlook facial emotions or are limited to specific individuals and cannot be applied to arbitrary subjects. In this paper, we propose a one-shot Talking Head Generation framework (SPEAK) that distinguishes itself from general Talking Face Generation by enabling emotional and postural control. Specifically, we introduce the Inter-Reconstructed Feature Disentanglement (IRFD) method to decouple human facial features into three latent spaces. We then design a face editing module that modifies speech content and facial latent codes into a single latent space. Subsequently, we present a novel generator that employs modified latent codes derived from the editing module to regulate emotional expression, head poses, and speech content in synthesizing facial animations. Extensive trials demonstrate that our method can generate realistic talking head with coordinated lip motions, authentic facial emotions, and smooth head movements. The demo video is available at the anonymous link: https://anonymous.4open.science/r/SPEAK-F56E